Nesta página, você aprenderá como fornecer várias linhas de dados para o AutoML Tables de uma só vez e receber uma previsão para cada linha.
Introdução
Após criar (treinar) um modelo, use o método batchPredict e faça uma solicitação assíncrona para receber um lote de previsões. Forneça os dados de entrada para o método batchPredict, no formato de tabela.
Cada linha fornece valores para os atributos que o modelo foi treinado a usar.
O método batchPredict envia esses dados para o modelo e retorna previsões para cada linha de dados.
Os modelos precisam ser treinados novamente a cada seis meses para que possam continuar exibindo previsões.
Como solicitar uma previsão em lote
Para previsões em lote, especifique uma origem de dados e um destino de resultados em uma Tabela do BigQuery ou em um arquivo CSV no Cloud Storage. Você não precisa usar a mesma tecnologia para a origem e o destino. Por exemplo, é possível usar o BigQuery para a fonte de dados e um arquivo CSV no Cloud Storage para o destino dos resultados. Siga as etapas apropriadas nas duas tarefas abaixo, dependendo dos seus requisitos.
Sua fonte de dados precisa conter dados tabulares que incluam todas as colunas usadas para treinar o modelo. É possível incluir colunas que não estejam nos dados de treinamento ou que estejam nos dados, mas não tenham sido usadas para o treinamento. Essas colunas extras são incluídas na saída da previsão, mas não são usadas para gerar a previsão.
Como usar tabelas do BigQuery
Os nomes das colunas e os tipos dos dados de entrada precisam corresponder aos dados usados no treinamento. As colunas podem ser ordenadas de modo diferente dos dados de treinamento.
Requisitos para tabelas do BigQuery
- As tabelas de origem de dados do BigQuery não podem ser maiores que 100 GB.
- Você precisa usar um conjunto de dados multirregional do BigQuery nos locais
USouEU. - Se a tabela estiver em outro projeto, você precisará conceder o papel
BigQuery Data Editorà conta de serviço do AutoML Table do projeto. Saiba mais.
Como solicitar a previsão em lote
Console
Acesse a página do AutoML Tables no console do Google Cloud.
Selecione Modelos e abra o que você quer usar.
Selecione a guia Testar e usar.
Clique em Previsão em lote.
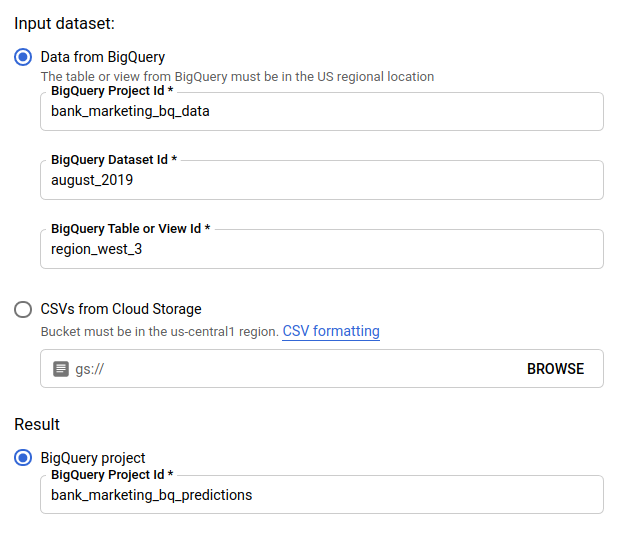
No caso de Conjunto de dados de entrada, selecione Tabela do BigQuery e forneça os IDs do projeto, do conjunto de dados e da tabela de fonte de dados.
No caso de Resultado, selecione Projeto do BigQuery e forneça o ID do projeto de destino dos resultados.
Se você quiser ver o impacto de cada recurso na previsão, selecione Gerar importância do atributo.
A geração de importância de atributos aumenta o tempo e calcula os atributos necessários para sua previsão. A importância do recurso local não está disponível com um destino de resultados do Cloud Storage.
Clique em Enviar previsão em lote para solicitá-la.
REST
Para solicitar previsões em lote, use o método models.batchPredict.
Antes de usar os dados da solicitação, faça as substituições a seguir:
-
endpoint:
automl.googleapis.compara o local global eeu-automl.googleapis.compara a região da UE. - project-id: é seu ID do projeto no Google Cloud.
- location: o local do recurso:
us-central1para global oueupara a União Europeia. - model-id: o código do modelo. Por exemplo,
TBL543. - dataset-id: o ID do conjunto de dados do BigQuery em que os dados de previsão estão localizados.
-
table-id: o código da tabela do BigQuery em que os dados de previsão estão localizados.
O AutoML Tables cria uma subpasta para os resultados da previsão chamada
prediction-<model_name>-<timestamp>em project-id.dataset-id.table-id.
Método HTTP e URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Corpo JSON da solicitação:
{
"inputConfig": {
"bigquerySource": {
"inputUri": "bq://project-id.dataset-id.table-id"
},
},
"outputConfig": {
"bigqueryDestination": {
"outputUri": "bq://project-id"
},
},
}
Para enviar a solicitação, escolha uma destas opções:
curl
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
Para receber a importância do recurso local, adicione o parâmetro feature_importance aos dados da solicitação. Para mais informações, consulte Importância do recurso local.
Java
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Node.js
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Python
A biblioteca de cliente para AutoML Tables inclui outros métodos Python que simplificam o uso da API AutoML Tables. Esses métodos se referem aos conjuntos de dados e aos modelos pelos nomes e não pelos IDs. É preciso que os nomes dos conjuntos de dados e modelos sejam exclusivos. Para mais informações, consulte a Referência do cliente.
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Como usar arquivos CSV no Cloud Storage
Os nomes das colunas e os tipos dos dados de entrada precisam corresponder aos dados usados no treinamento. As colunas podem ser ordenadas de modo diferente dos dados de treinamento.
Requisitos para arquivos CSV
- A primeira linha da fonte de dados precisa conter os nomes das colunas.
Cada arquivo de fonte de dados não pode ser superior a 10 GB.
É possível incluir vários arquivos até um máximo de 100 GB.
É preciso que o bucket do Cloud Storage esteja em conformidade com os requisitos de bucket.
Se o bucket do Cloud Storage estiver em um projeto diferente daquele em você usa o AutoML Tables, será preciso conceder o papel
Storage Object Creatorà conta de serviço do AutoML Tables no projeto. Saiba mais.
Console
Acesse a página do AutoML Tables no console do Google Cloud.
Selecione Modelos e abra o que você quer usar.
Selecione a guia Testar e usar.
Clique em Previsão em lote.
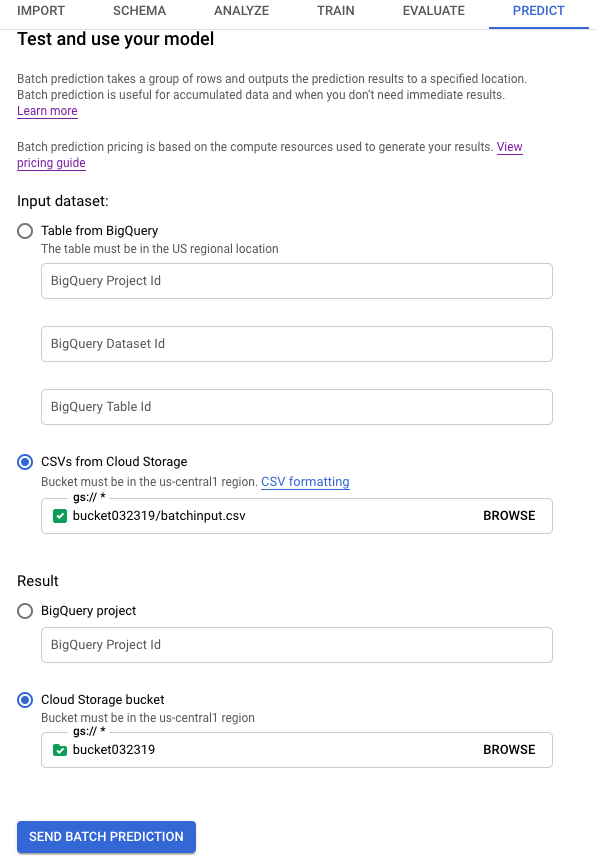
Em Conjunto de dados de entrada, selecione CSVs do Cloud Storage e forneça o URI do bucket da fonte de dados.
No caso de Resultado, selecione bucket do Cloud Storage e forneça o URI do bucket de destino.
Se você quiser ver o impacto de cada recurso na previsão, selecione Gerar importância do atributo.
A geração de importância de atributos aumenta o tempo e calcula os atributos necessários para sua previsão. A importância do recurso local não está disponível com um destino de resultados do Cloud Storage.
Clique em Enviar previsão em lote para solicitá-la.
REST
Para solicitar previsões em lote, use o método models.batchPredict.
Antes de usar os dados da solicitação, faça as substituições a seguir:
-
endpoint:
automl.googleapis.compara o local global eeu-automl.googleapis.compara a região da UE. - project-id: é seu ID do projeto no Google Cloud.
- location: o local do recurso:
us-central1para global oueupara a União Europeia. - model-id: o código do modelo. Por exemplo,
TBL543. - input-bucket-name: o nome do bucket do Cloud Storage em que os dados de previsão estão localizados.
- input-directory-name: o nome do diretório do Cloud Storage em que os dados de previsão estão localizados.
- object-name: o nome do objeto do Cloud Storage em que os dados de previsão estão localizados.
- output-bucket-name: o nome do bucket do Cloud Storage para os resultados de previsão.
-
output-directory-name: o nome do diretório do Cloud Storage para os
resultados de previsão.
O AutoML Tables cria uma subpasta para os resultados de previsão denominados
prediction-<model_name>-<timestamp>emgs://output-bucket-name/output-directory-name. Você precisa ter permissões de gravação nesse caminho.
Método HTTP e URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Corpo JSON da solicitação:
{
"inputConfig": {
"gcsSource": {
"inputUris": [
"gs://input-bucket-name/input-directory-name/object-name.csv"
]
},
},
"outputConfig": {
"gcsDestination": {
"outputUriPrefix": "gs://output-bucket-name/output-directory-name"
},
},
}
Para enviar a solicitação, escolha uma destas opções:
curl
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
Para receber a importância do recurso local, adicione o parâmetro feature_importance aos dados da solicitação. Para mais informações, consulte Importância do recurso local.
Java
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Node.js
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Python
A biblioteca de cliente para AutoML Tables inclui outros métodos Python que simplificam o uso da API AutoML Tables. Esses métodos se referem aos conjuntos de dados e aos modelos pelos nomes e não pelos IDs. É preciso que os nomes dos conjuntos de dados e modelos sejam exclusivos. Para mais informações, consulte a Referência do cliente.
Se os recursos estiverem localizados na região da UE, você precisará definir o endpoint explicitamente. Saiba mais.
Como recuperar resultados
Como recuperar resultados de previsão no BigQuery
Se você tiver especificado o BigQuery como destino de saída, os resultados da solicitação de previsão em lote serão retornados como um novo conjunto de dados no projeto do BigQuery especificado. O conjunto de dados do BigQuery é o nome do modelo, precedido por "prediction_" e anexado com o carimbo de data/hora do momento em que o job de previsão foi iniciado. Encontre o nome do conjunto de dados do BigQuery em Previsões recentes, na página Previsão em lote da guia Testar e usar do seu modelo.
O conjunto de dados do BigQuery contém duas tabelas: predictions e errors. A tabela errors tem uma linha para cada linha da solicitação de previsão para que o AutoML Tables não conseguir retornar uma previsão, por exemplo, no caso de um recurso não anulável estar nulo. A tabela predictions contém uma linha para cada previsão retornada.
Na tabela predictions, o AutoML Tables retorna seus dados de previsão e cria uma nova coluna para os resultados de previsão com a adição de "predicted_" antes do nome da coluna de destino. A coluna com os resultados da previsão contém uma estrutura aninhada do BigQuery, contendo os resultados da previsão.
Use uma consulta no console do BigQuery para recuperar os resultados da previsão. O formato da consulta depende do seu tipo de modelo.
Classificação binária:
SELECT predicted_<target-column-name>[OFFSET(0)].tables AS value_1, predicted_<target-column-name>[OFFSET(1)].tables AS value_2 FROM <bq-dataset-name>.predictions
"value_1" e "value_2" são marcadores de lugar. É possível substituí-los pelos valores de destino ou por um equivalente.
Classificação multiclasse:
SELECT predicted_<target-column-name>[OFFSET(0)].tables AS value_1, predicted_<target-column-name>[OFFSET(1)].tables AS value_2, predicted_<target-column-name>[OFFSET(2)].tables AS value_3, ... predicted_<target-column-name>[OFFSET(4)].tables AS value_5 FROM <bq-dataset-name>.predictions
"valor_1", "valor_2" etc. são marcadores de lugar. É possível substituí-los pelos valores de destino ou por um equivalente.
Regressão:
SELECT predicted_<target-column-name>[OFFSET(0)].tables.value, predicted_<target-column-name>[OFFSET(0)].tables.prediction_interval.start, predicted_<target-column-name>[OFFSET(0)].tables.prediction_interval.end FROM <bq-dataset-name>.predictions
Como recuperar resultados no Cloud Storage
Se você tiver especificado o Cloud Storage como destino de saída, os resultados da solicitação de previsão em lote serão retornados como arquivos CSV em uma nova pasta no bucket especificado. O nome da pasta é o nome do modelo, precedido por "prediction-" e anexado ao carimbo de data/hora do momento em que o job de previsão foi iniciado. Encontre o nome da pasta do Cloud Storage em Previsões recentes, na parte inferior da página Previsão em lote da guia Testar e usar do modelo.
A pasta do Cloud Storage contém dois tipos de arquivos: arquivos de erro e arquivos de previsão. Se os resultados forem extensos, serão criados outros arquivos.
Os arquivos de erro são denominados errors_1.csv, errors_2.csv e assim por diante. Esses arquivos
contêm uma linha de cabeçalho e uma linha para cada linha da solicitação de previsão para
que o AutoML Tables não conseguir retornar uma previsão.
Os arquivos de previsão são denominados tables_1.csv, tables_2.csv e assim por diante. Esses arquivos contêm uma linha de cabeçalho com os nomes das colunas e uma linha para cada previsão retornada.
Nos arquivos de previsão, o AutoML Tables retorna os dados de previsão e cria uma ou mais colunas para os resultados da previsão, dependendo do tipo de modelo:
Classificação:
Para cada valor potencial da coluna de destino, uma coluna chamada <target-column-name>_<value>_score é adicionada aos resultados. Essa coluna
contém a pontuação ou a estimativa de confiança desse valor.
Regressão:
O valor previsto para essa linha é retornado em uma coluna chamada predicted_<target-column-name>. O intervalo de previsão não é retornado para
a saída CSV.
A importância do recurso local não está disponível para resultados no Cloud Storage.
Como interpretar os resultados
A forma como você interpreta os resultados depende do problema comercial que você está buscando resolver e de como seus dados são distribuídos.
Como interpretar resultados de modelos de classificação
Os resultados de previsão para modelos de classificação (binários e multiclasses) retornam uma pontuação de probabilidade para cada valor potencial da coluna de destino. Você precisa determinar como quer usar as pontuações. Por exemplo, para receber uma classificação binária a partir das pontuações fornecidas, você identificaria um valor limite. Se houver duas classes, "A" e "B", classifique o exemplo como "A" se a pontuação de "A" for maior que o limite escolhido, e como "B" se for menor. Em conjuntos de dados desequilibrados, o limite pode se aproximar de 100% ou de 0%.
É possível usar o gráfico de curva de recall de precisão, o gráfico de curva do operador do receptor e outras estatísticas relevantes por rótulo na página Avaliar do modelo no Console do Google Cloud para ver como a alteração do limite altera suas métricas de avaliação. Isso ajuda você a determinar a melhor maneira de usar os valores de pontuação para interpretar os resultados da previsão.
Como interpretar os resultados em modelos de regressão
O valor esperado, que é retornado em modelos de regressão, pode ser usado diretamente para muitos tipos de problemas. Também é possível usar o intervalo de previsão, se ele for retornado e se um intervalo fizer sentido para seu problema de negócios.
Como interpretar os resultados de importância do recurso local
Para informações sobre como interpretar os resultados de importância do recurso local, consulte Importância do recurso local.
A seguir
- Saiba mais sobre a importância do recurso local.
- Saiba mais sobre operações de longa duração.