Introdução
Imagine que você trabalhe no departamento de marketing de um varejista digital. Você e sua equipe estão criando um programa de e-mail personalizado com base nos perfis dos clientes. Você criou os perfis e tem os e-mails de marketing prontos. Agora você precisa criar um sistema que agrupe os clientes em cada perfil com base nas preferências de compras e no comportamento de gastos, mesmo no caso de clientes novos. Você também quer saber os hábitos de consumo dos clientes para otimizar o envio de e-mails e maximizar o engajamento.
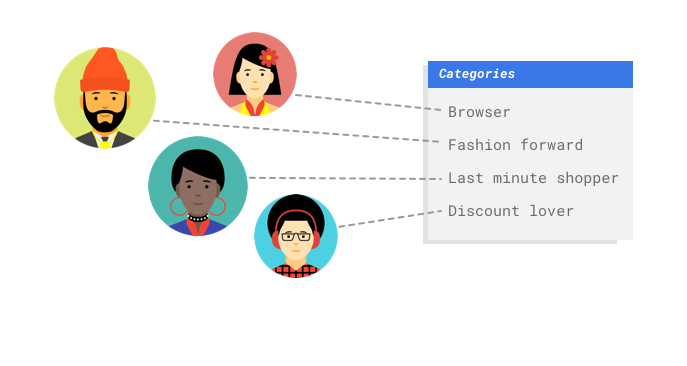
Como sua empresa é um varejista digital, você tem dados sobre os clientes e as compras que eles fizeram. Mas e quanto aos clientes novos? É possível calcular esses valores dos clientes atuais com longos históricos de compras usando as abordagens tradicionais. No entanto, elas não funcionam quando aplicadas a clientes com poucos dados históricos. E se fosse possível criar um sistema capaz de prever esses valores e acelerar a entrega de programas de marketing personalizados aos clientes?
Felizmente, é possível resolver esses problemas satisfatoriamente com a tecnologia de machine learning e o AutoML Tables. Ao ler este guia, você entenderá como o AutoML Tables funciona e conhecerá os tipos de problemas que ele foi criado para solucionar.
Como o AutoML Tables funciona?
 O AutoML Tables é um serviço de aprendizado supervisionado. Isso significa que os modelos de machine learning são treinados com dados de exemplo. O AutoML Tables usa dados em tabelas (estruturados) para treinar modelos de machine learning e fazer predições sobre dados novos. O modelo aprenderá a prever uma coluna do conjunto de dados, chamada de objetivo. Um determinado número das demais colunas de dados servem de entradas, chamadas de recursos, que o modelo usará para aprender padrões. É possível usar os mesmos atributos de entrada para criar vários tipos de modelos, bastando alterar o objetivo. No exemplo dos e-mails de marketing, isso significa que é possível criar dois modelos usando os mesmos atributos de entrada: um modelo para prever o perfil do cliente (um objetivo categórico) e outro para prever o gasto mensal do cliente (um objetivo numérico).
O AutoML Tables é um serviço de aprendizado supervisionado. Isso significa que os modelos de machine learning são treinados com dados de exemplo. O AutoML Tables usa dados em tabelas (estruturados) para treinar modelos de machine learning e fazer predições sobre dados novos. O modelo aprenderá a prever uma coluna do conjunto de dados, chamada de objetivo. Um determinado número das demais colunas de dados servem de entradas, chamadas de recursos, que o modelo usará para aprender padrões. É possível usar os mesmos atributos de entrada para criar vários tipos de modelos, bastando alterar o objetivo. No exemplo dos e-mails de marketing, isso significa que é possível criar dois modelos usando os mesmos atributos de entrada: um modelo para prever o perfil do cliente (um objetivo categórico) e outro para prever o gasto mensal do cliente (um objetivo numérico).
O fluxo de trabalho do AutoML Tables
O AutoML Tables usa um fluxo de trabalho de machine learning padrão:
- Coleta de dados: determine os dados necessários para treinar e testar o modelo com base no resultado pretendido.
- Preparação dos dados: verifique se os dados estão formatados corretamente antes e depois de importá-los.
- Treinamento: defina os parâmetros e crie o modelo.
- Avaliação: analise as métricas do modelo.
- Teste: faça um ensaio com o modelo usando dados de teste.
- Implantação e predição: disponibilize o modelo para uso.
Antes de começar a coletar os dados, é preciso pensar no problema que você está tentando resolver. Isso determina os requisitos dos dados.
Pense no caso de uso

Comece com seu problema: qual é o resultado que você quer alcançar? Que tipo de dados estão na coluna de objetivo? Qual a quantidade de dados a que você tem acesso?
Dependendo das respostas, o AutoML Tables cria o modelo necessário para solucionar o caso de uso:
Um modelo de classificação binária prevê um resultado binário, ou seja, que tenha uma entre duas classes. Esse tipo de modelo é adequado para perguntas com resposta “sim” ou “não”. Por exemplo, para prever se um cliente estaria disposto (ou não) a adquirir uma assinatura. Em circunstâncias iguais, um problema de classificação binária requer menos dados do que outros tipos de modelo.
Um modelo de classificação multiclasse prevê um resultado que tenha uma entre três ou mais classes distintas. Esse tipo de modelo é adequado para categorizações. No exemplo do varejista, convém criar um modelo de classificação multiclasse para segmentar os clientes em perfis diferentes.
Um modelo de regressão prevê um resultado com valor contínuo. No exemplo do varejista, convém também criar um modelo de regressão para prever os gastos dos clientes no próximo mês.
O AutoML Tables define automaticamente o problema e o modelo a ser criado com base no tipo de dados da coluna de objetivo. Portanto, se a coluna de objetivo contiver dados numéricos, o AutoML Tables criará um modelo de regressão. Entretanto, se a coluna de objetivo contiver dados categóricos, o AutoML Tables detectará o número de classes e determinará se é necessário criar um modelo binário ou multiclasse.
Uma observação sobre imparcialidade
A imparcialidade é uma das práticas de responsabilidade de IA do Google. O objetivo da imparcialidade é entender e prevenir o tratamento injusto ou preconceituoso de pessoas relacionado a raça, renda, orientação sexual, religião, gênero e outras características historicamente associadas à discriminação e marginalização, sempre que se manifestarem em sistemas algorítmicos ou na tomada de decisões auxiliada por algoritmos. Mais adiante neste guia você verá observações sobre imparcialidade, em que se discute como criar um modelo de machine learning mais justo. Saiba mais
Coletar dados
 Depois de estabelecer o caso de uso, é preciso coletar dados para treinar o modelo.
A obtenção e a preparação de dados são etapas críticas para a criação de um modelo de machine learning. Os dados que você tem disponíveis informarão o tipo de problemas que você pode resolver.
Quantos dados você tem disponíveis? Seus dados são relevantes para as perguntas que você
está tentando responder? Ao coletar seus dados, tenha em mente as considerações importantes a seguir.
Depois de estabelecer o caso de uso, é preciso coletar dados para treinar o modelo.
A obtenção e a preparação de dados são etapas críticas para a criação de um modelo de machine learning. Os dados que você tem disponíveis informarão o tipo de problemas que você pode resolver.
Quantos dados você tem disponíveis? Seus dados são relevantes para as perguntas que você
está tentando responder? Ao coletar seus dados, tenha em mente as considerações importantes a seguir.
Selecionar atributos relevantes
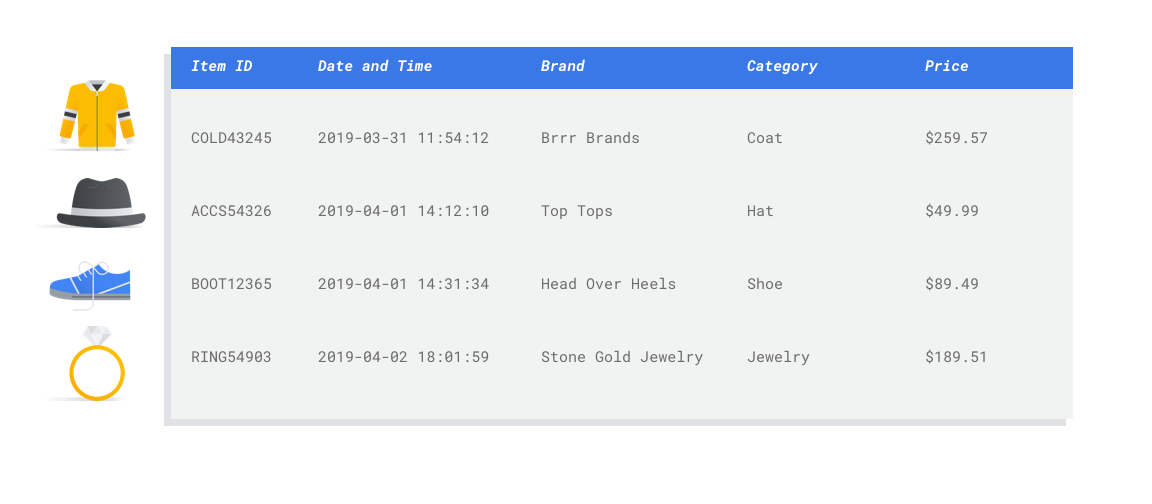
Um atributo é uma entrada usada no treinamento do modelo. Os atributos são os elementos usados pelo modelo para identificar padrões e fazer predições. Portanto, eles precisam ser relevantes para o problema em questão. Por exemplo, para criar um modelo que prevê se uma transação com cartão de crédito é fraudulenta ou não, será necessário criar um conjunto de dados que contenha detalhes sobre as transações, como comprador, vendedor, valor, itens comprados, data e hora. Outros atributos possivelmente úteis são as informações históricas sobre o comprador e o vendedor e com que frequência houve fraudes na compra do item em questão. Que outros atributos talvez sejam relevantes?
Lembrando do uso de caso dos e-mails de marketing do varejista na introdução, estas são algumas colunas de atributo que provavelmente serão necessárias:
- Lista de itens comprados (incluindo marcas, categorias, preços e descontos)
- Número de itens comprados (último dia, semana, mês e ano)
- Soma do valor gasto (último dia, semana, mês e ano)
- Perfil demográfico conhecido do comprador
Incluir dados suficientes
 Em geral, quanto mais exemplos de treinamento você tiver, melhor serão os resultados. A
quantidade de dados de exemplo necessária também aumenta de acordo com a complexidade do problema
que você está tentando resolver. Você não precisa de tantos dados para conseguir um modelo de classificação binária preciso em comparação com um modelo multiclasse, porque é menos complicado prever uma classe a partir de duas em vez de muitas.
Em geral, quanto mais exemplos de treinamento você tiver, melhor serão os resultados. A
quantidade de dados de exemplo necessária também aumenta de acordo com a complexidade do problema
que você está tentando resolver. Você não precisa de tantos dados para conseguir um modelo de classificação binária preciso em comparação com um modelo multiclasse, porque é menos complicado prever uma classe a partir de duas em vez de muitas.
Não há uma fórmula perfeita. No entanto, há um número mínimo recomendado de linhas de dados de exemplo:
- Problema de classificação: 50 x o número de recursos
- Problema de regressão: 200 x o número de atributos
Capturar variações
É necessário que o conjunto de dados capture a diversidade do espaço do problema. Quanto mais exemplos diversos um modelo vê durante o treinamento, mais imediatamente ele pode generalizar para exemplos novos ou menos comuns. Imagine que o modelo de varejo fosse treinado usando apenas dados de compras no período de inverno. Ele seria capaz de prever com sucesso as preferências de vestuário ou os comportamentos de consumo durante o verão?
Preparar os dados

Depois de identificar os dados disponíveis, é necessário ter certeza de que eles estão prontos para o treinamento. Se os dados forem parciais ou tiverem valores errados ou ausentes, o modelo refletirá essas falhas no treinamento. Pense nos pontos abaixo antes de começar a treinar um modelo. Saiba mais
Evitar vazamento de dados e distorção entre treinamento e exibição
O vazamento de dados ocorre quando são usados atributos de entrada durante o treinamento que “vazam” informações sobre o objetivo que você quer prever, que não estarão disponíveis durante a real exibição do modelo. É possível detectar esse tipo de ocorrência quando um atributo altamente correlacionado com a coluna de objetivo é incluso como um dos atributos de entrada. Por exemplo, imagine que você esteja criando um modelo para prever se um cliente adquirirá uma assinatura no próximo mês, e um dos atributos de entrada é um pagamento futuro pela assinatura realizado por esse cliente. Isso pode resultar em desempenho forte do modelo durante o teste, mas não quando ele for implantado em produção, já que as informações de pagamentos futuros pela assinatura não estarão disponíveis no momento da exibição.
A distorção entre treinamento e exibição ocorre quando os atributos de entrada usados durante o treinamento são diferentes daqueles fornecidos ao modelo durante a exibição, resultando na má qualidade do modelo quando em produção. Por exemplo, criar um modelo para prever as temperaturas a cada hora, mas treiná-lo com dados que contêm apenas temperaturas por semana. Outro exemplo seria sempre fornecer as notas de um aluno nos dados de treinamento para prever a evasão escolar, mas não fornecer essas informações no momento de exibição.
Entender os dados de treinamento é importante para evitar o vazamento de dados e a distorção entre treinamento e exibição:
- Antes de usar qualquer dado, verifique se você sabe o que significam e se eles servem ou não como atributo.
- Verifique a correlação na guia "Treinar". Correlações altas precisam ser sinalizadas para revisão.
- Quanto à distorção entre treinamento e exibição, verifique se foram fornecidos ao modelo apenas atributos de entrada que estarão disponíveis exatamente no mesmo formato no momento da exibição.
Limpar dados ausentes, incompletos e inconsistentes
É comum que os dados de exemplo incluam valores ausentes e imprecisos. Reserve um tempo para revisar e, se possível, melhorar a qualidade dos dados antes de usá-los no treinamento. Quanto mais valores ausentes, menos úteis serão os dados para treinar um modelo de machine learning.
Verifique seus dados quanto a valores ausentes e corrija-os, se possível, ou deixe o valor em branco se a coluna estiver definida como anulável. O AutoML Tables pode cuidar de valores ausentes, mas há mais chances de você conseguir melhores resultados se todos os valores estiverem disponíveis.
Corrija ou exclua erros ou ruídos para limpar os dados. Faça com que os dados sejam consistentes revisando a ortografia, as abreviações e a formatação.
Analisar os dados após a importação
O AutoML Tables apresenta uma visão geral do conjunto de dados após a importação. Revise o conjunto de dados importado para garantir que cada coluna tenha o tipo de variável correto. O AutoML Tables detecta automaticamente o tipo de variável com base nos valores das colunas, mas ainda assim o melhor é revisar cada uma delas. Além disso, analise em cada coluna a nulidade, que determina se uma coluna pode ter valores ausentes ou NULL.
Treinar o modelo
Após importar o conjunto de dados, a próxima etapa é treinar um modelo. O AutoML Tables gera um modelo de machine learning confiável com os padrões de treinamento. No entanto, talvez seja melhor você ajustar alguns parâmetros de acordo com seu caso de uso.
Selecione o máximo possível de colunas de atributos para o treinamento, mas analise cada uma para garantir que sejam apropriadas. Lembre-se do seguinte ao selecionar os atributos:
- Não selecione colunas de recursos que vão criar ruídos, como colunas de identificador atribuídas aleatoriamente com um valor exclusivo para cada linha.
- Certifique-se de entender cada coluna de recursos e os valores correspondentes.
- Se você pretende criar vários modelos usando um único conjunto de dados, remova as colunas de objetivo que não façam parte do problema de predição em que você está trabalhando no momento.
- Lembre-se dos princípios de imparcialidade: você está treinando o modelo com um atributo que poderia resultar em decisões enviesadas ou injustas com relação a grupos marginalizados?
Como o AutoML Tables usa o conjunto de dados
O conjunto de dados é dividido em conjuntos de treinamento, validação e teste. Por padrão, o AutoML Tables usa 80% dos dados para treinamento, 10% para validação e 10% para teste. No entanto, é possível editar esses valores manualmente, se necessário.
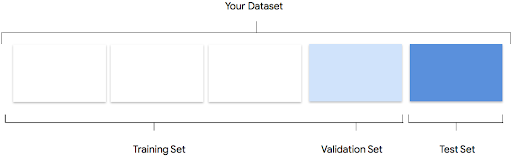
Conjunto de treinamento
 A maior parte dos dados precisa estar no conjunto de treinamento. Esses são os dados que o modelo "vê" durante o treinamento. Eles são usados para aprender os parâmetros do modelo, ou seja, os pesos das conexões entre os nós da rede neural.
A maior parte dos dados precisa estar no conjunto de treinamento. Esses são os dados que o modelo "vê" durante o treinamento. Eles são usados para aprender os parâmetros do modelo, ou seja, os pesos das conexões entre os nós da rede neural.
Conjunto de validação
 O conjunto de validação, às vezes chamado de conjunto "dev", também é usado durante
o processo de treinamento. Depois que os dados são incorporados pelo framework de aprendizado do modelo em cada iteração do processo de treinamento, o desempenho do modelo é usado no conjunto de validação para ajustar os hiperparâmetros, que são variáveis usadas para especificar a estrutura do modelo. Se você usar o conjunto de treinamento para ajustar os hiperparâmetros, é bem provável que os dados de treinamento sejam excessivamente enfatizados no modelo e ele terá dificuldades para generalizar exemplos que não correspondam exatamente aos dados. O modelo terá melhor capacidade de generalização se você usar um conjunto de dados relativamente novo para ajustar a estrutura.
O conjunto de validação, às vezes chamado de conjunto "dev", também é usado durante
o processo de treinamento. Depois que os dados são incorporados pelo framework de aprendizado do modelo em cada iteração do processo de treinamento, o desempenho do modelo é usado no conjunto de validação para ajustar os hiperparâmetros, que são variáveis usadas para especificar a estrutura do modelo. Se você usar o conjunto de treinamento para ajustar os hiperparâmetros, é bem provável que os dados de treinamento sejam excessivamente enfatizados no modelo e ele terá dificuldades para generalizar exemplos que não correspondam exatamente aos dados. O modelo terá melhor capacidade de generalização se você usar um conjunto de dados relativamente novo para ajustar a estrutura.
Conjunto de teste
 O conjunto de teste não faz parte do processo de treinamento. Depois que o treinamento do modelo for totalmente concluído, o AutoML Tables usa o conjunto de teste como um novo desafio para seu modelo. O desempenho do modelo no conjunto de teste serve para dar uma boa ideia de como ele vai se sair com dados reais.
O conjunto de teste não faz parte do processo de treinamento. Depois que o treinamento do modelo for totalmente concluído, o AutoML Tables usa o conjunto de teste como um novo desafio para seu modelo. O desempenho do modelo no conjunto de teste serve para dar uma boa ideia de como ele vai se sair com dados reais.
Avaliar o modelo
 Após o treinamento do modelo, você receberá um resumo do desempenho dele. As métricas de avaliação são baseadas no desempenho do modelo em relação a uma parte do conjunto de dados (o conjunto de dados de teste). Há algumas métricas e conceitos importantes a serem considerados ao determinar se o modelo está pronto para ser usado em dados reais.
Após o treinamento do modelo, você receberá um resumo do desempenho dele. As métricas de avaliação são baseadas no desempenho do modelo em relação a uma parte do conjunto de dados (o conjunto de dados de teste). Há algumas métricas e conceitos importantes a serem considerados ao determinar se o modelo está pronto para ser usado em dados reais.
Métricas de classificação
Limite de pontuação
Imagine um modelo de machine learning que prevê se um cliente comprará uma jaqueta no próximo ano. Qual nível de certeza o modelo precisa ter para prever que um determinado cliente comprará uma jaqueta? Nos modelos de classificação, é atribuída a cada predição uma pontuação de confiança, que é uma avaliação numérica da certeza do modelo de que a classe prevista está correta. O limite de pontuação é o número que determina quando uma pontuação específica é convertida em uma decisão de “sim” ou “não”, isto é, o valor em que o modelo diz “sim, essa pontuação de confiança é alta o suficiente para concluir que esse cliente comprará um casaco no próximo ano”.
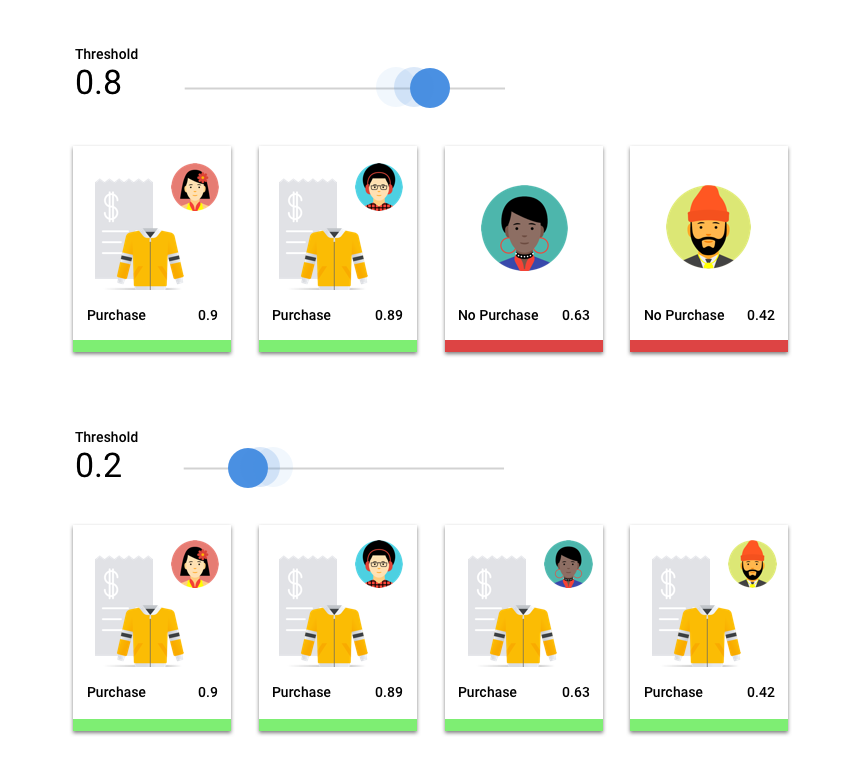
Se o limite de pontuação for baixo, o modelo correrá o risco de fazer classificações errôneas. Por isso, o limite de pontuação precisa ser baseado em um caso de uso específico.
Resultados da predição
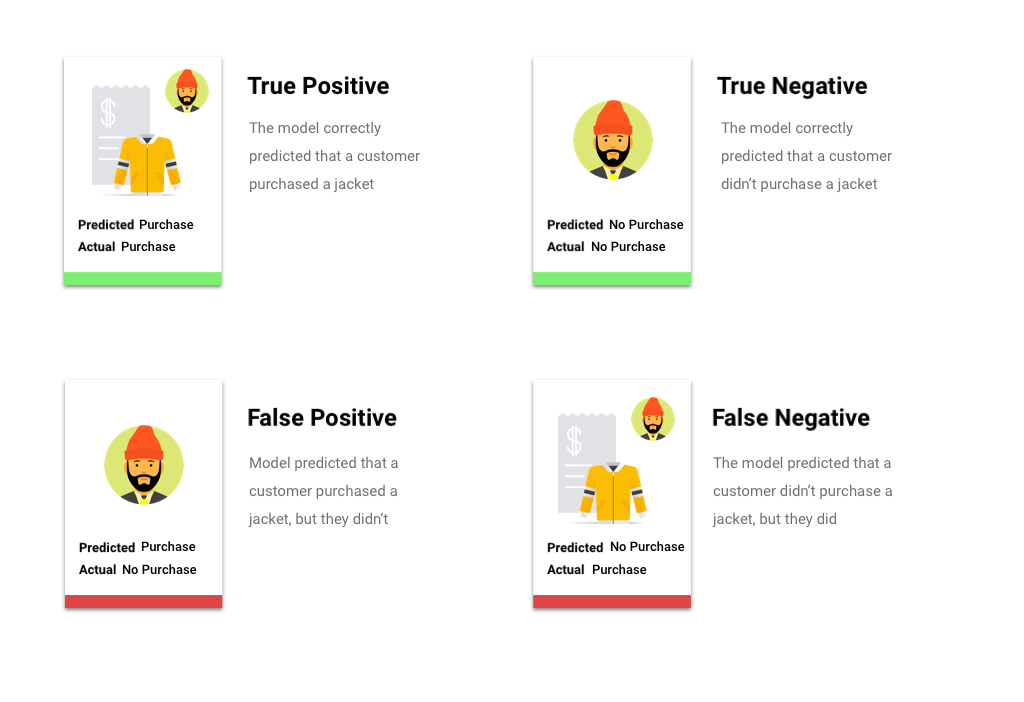
Depois de aplicar o limite de pontuação, as predições feitas pelo modelo são colocadas em uma de quatro categorias. Para entender essas categorias, imagine novamente o modelo de classificação binária sobre a compra da jaqueta. Nesse exemplo, a classe positiva (o que a modelo está tentando prever) é que o cliente comprará uma jaqueta no próximo ano.
- Verdadeiro positivo: o modelo prevê corretamente a classe positiva. Ou seja, ele previu corretamente que o cliente compraria uma jaqueta.
- Falso positivo: o modelo prevê incorretamente a classe positiva. Ou seja, ele previu que o cliente compraria uma jaqueta, mas isso não ocorreu.
- Verdadeiro negativo: o modelo prevê corretamente a classe negativa. Ou seja, ele previu corretamente que o cliente não compraria uma jaqueta.
- Falso negativo: o modelo prevê incorretamente uma classe negativa. Ou seja, ele previu que o cliente não compraria uma jaqueta, mas o cliente comprou.
Precisão e recall
Com as métricas de precisão e recall, é possível entender o desempenho do modelo na captura de informações e o quanto ele não está considerando. Saiba mais sobre precisão e recall.
- A precisão é a fração das predições positivas que estava correta. De todas as previsões de que um cliente faria uma compra, qual é a fração de compras realizadas de fato?
- Recall é a fração de linhas com esse rótulo que o modelo previu corretamente. De todas as compras feitas por clientes que poderiam ter sido identificadas, qual a fração das que foram identificadas de fato?
Dependendo do caso de uso, talvez seja preciso otimizar a precisão ou o recall.
Outras métricas de classificação
AUC PR: área sob curva de precisão-recall (PR, na sigla em inglês). Ela varia de 0 a 1. Um valor maior indica um modelo de melhor qualidade.
AUC ROC: área sob a curva de característica de operação do receptor (ROC, na sigla em inglês). Ela varia de 0 a 1. Um valor maior indica um modelo de melhor qualidade.
Precisão: fração de previsões de classificação produzidas pelo modelo que estavam corretas.
Perda de registro: entropia cruzada entre as previsões do modelo e os valores desejados. Ela varia de zero a infinito. Um valor menor indica um modelo de melhor qualidade.
Pontuação F1: média harmônica de precisão e recall. F1 é uma métrica útil quando você está procurando um equilíbrio entre precisão e recall e a distribuição de classes é desigual.
Métricas de regressão
Depois de criar o modelo, o AutoML Tables fornece uma variedade de métricas de regressão padrão para análise. Não há uma resposta perfeita sobre como avaliar o modelo. É preciso considerar as métricas de avaliação de acordo com o contexto do tipo de problema e o resultado pretendido com o modelo. Confira abaixo a visão geral de algumas métricas disponíveis.
Erro médio absoluto (MAE)
O erro médio absoluto (MAE, na sigla em inglês) é a diferença média absoluta entre os valores de objetivo e previstos. Essa métrica mede a magnitude média dos erros (a diferença entre um valor de objetivo e um valor previsto) em um conjunto de predições. Como essa métrica usa valores absolutos, o MAE não considera a direção da relação nem indica o desempenho abaixo ou acima do esperado. Ao avaliar o MAE, um valor menor indica um modelo de maior qualidade (0 representa um preditor perfeito).
Raiz do erro médio quadrático (REMQ)
A raiz do erro médio quadrático (REMQ) é a raiz quadrada da diferença média ao quadrado entre os valores de objetivo e previstos. A REMQ é mais sensível a outliers do que o MAE. Portanto, se você estiver preocupado com erros grandes, talvez seja mais útil avaliar a REMQ. Assim como no caso do MAE, um valor menor indica um modelo de maior qualidade (0 representa um preditor perfeito).
Raiz do erro médio quadrático e logarítmico (RMSLE)
A raiz do erro quadrático e logarítmico (RMSLE, na sigla em inglês) é a REMQ em escala logarítmica. A RMSLE é mais sensível a erros relativos do que erros absolutos e enfoca mais o desempenho insatisfatório do que o desempenho acima do esperado.
Testar o modelo
Avaliar as métricas do modelo significa antes de mais nada determinar se o modelo está pronto para ser implantado. No entanto, também é possível testá-lo com dados novos. Faça o upload de dados novos para constatar se as predições do modelo correspondem às suas expectativas. Com base nas métricas de avaliação ou nos testes com dados novos, você saberá se é necessário aprimorar mais o desempenho do modelo. Saiba mais sobre como solucionar problemas do modelo.
Implantar o modelo e fazer predições
 Quando o desempenho for satisfatório para você, será hora de usar o modelo. Isso pode significar o uso em escala de produção ou talvez em uma única solicitação de previsão. Dependendo do caso de uso, o modelo poderá ser usado de maneiras diferentes.
Quando o desempenho for satisfatório para você, será hora de usar o modelo. Isso pode significar o uso em escala de produção ou talvez em uma única solicitação de previsão. Dependendo do caso de uso, o modelo poderá ser usado de maneiras diferentes.
Previsão em lote
A previsão em lote é útil para fazer muitas solicitações de previsão de uma só vez. A previsão em lote é assíncrona, indicando que o modelo aguardará o processamento de todas as solicitações de previsão antes de gerar resultados em um arquivo CSV ou uma Tabela do BigQuery com os valores de previsão.
Previsão on-line
Implante seu modelo para disponibilizá-lo para pedidos de previsão com uma API REST. A predição on-line é síncrona (em tempo real), o que significa que ela retornará rapidamente uma previsão. No entanto, ela aceita apenas uma solicitação por chamada de API. A previsão on-line será útil quando o modelo fizer parte de um aplicativo e houver elementos do sistema que dependam do retorno rápido das previsões.
Para evitar cobranças indesejadas, lembre-se de cancelar a implantação do modelo quando ele não estiver em uso.