Cette page explique comment utiliser l'importance des caractéristiques pour obtenir une visibilité sur la façon dont le modèle effectue ses prédictions.
Pour plus d'informations sur AI Explanations, consultez la présentation d'AI Explanations pour AI Platform.
Introduction
Lorsque vous utilisez un modèle de machine learning pour prendre des décisions commerciales, il est important de comprendre comment vos données d'entraînement ont contribué au modèle final et comment celui-ci est arrivé à des prédictions individuelles. Cette compréhension vous aide à garantir l'équité et la justesse de votre modèle.
AutoML Tables fournit l'importance des caractéristiques, parfois appelée attributions de caractéristiques, qui vous permet d'identifier les caractéristiques qui ont le plus contribué à l'entraînement du modèle (importance des caractéristiques du modèle) et aux prédictions individuelles (importance des caractéristiques locales).
AutoML Tables calcule l'importance des caractéristiques à l'aide de la méthode par échantillonnage de Shapley. Pour plus d'informations sur l'explicabilité des modèles, consultez la présentation de AI Explanations.
Importance des caractéristiques du modèle
L'importance des caractéristiques du modèle permet de vous assurer que les caractéristiques qui ont servi à entraîner le modèle sont cohérentes avec vos données et votre problématique métier. Toutes les caractéristiques associées à une valeur d'importance élevée doivent représenter un signal valide pour la prédiction et être incluses de manière cohérente dans vos requêtes de prédiction.
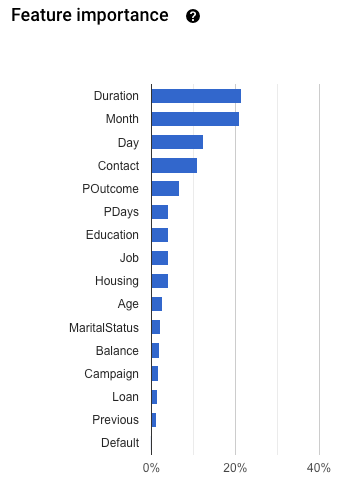
L'importance des caractéristiques du modèle est fournie en pourcentage pour chaque caractéristique : plus le pourcentage est élevé, plus la caractéristique d'entraînement du modèle est affectée.
Obtenir l'importance des caractéristiques du modèle
Console
Pour afficher les valeurs d'importance des caractéristiques de votre modèle à l'aide de la console Google Cloud:
Accédez à la page "AutoML Tables" dans la console Google Cloud.
Ouvrez l'onglet Modèles dans le volet de navigation de gauche, puis sélectionnez le modèle dont vous souhaitez afficher les métriques d'évaluation.
Ouvrez l'onglet Evaluate (Évaluation).
Faites défiler la page vers le bas pour afficher le graphique Importance des caractéristiques.
REST
Pour obtenir les valeurs d'importance des caractéristiques pour un modèle, utilisez la méthode model.get.
Avant d'utiliser les données de requête, effectuez les remplacements suivants:
-
endpoint:
automl.googleapis.compour la zone internationale eteu-automl.googleapis.compour la région UE. - project-id : ID de votre projet Google Cloud.
- location : emplacement de la ressource :
us-central1pour l'emplacement mondial oueupour l'Union européenne. -
model-id : ID du modèle pour lequel vous souhaitez obtenir des informations sur l'importance des caractéristiques.
Par exemple,
TBL543.
Méthode HTTP et URL :
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
exécutez la commande suivante :
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id"
PowerShell
exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id" | Select-Object -Expand Content
{
"name": "projects/292381/locations/us-central1/models/TBL543",
"displayName": "Quickstart_Model",
...
"tablesModelMetadata": {
"targetColumnSpec": {
...
},
"inputFeatureColumnSpecs": [
...
],
"optimizationObjective": "MAXIMIZE_AU_ROC",
"tablesModelColumnInfo": [
{
"columnSpecName": "projects/292381/locations/us-central1/datasets/TBL543/tableSpecs/246/columnSpecs/331",
"columnDisplayName": "Contact",
"featureImportance": 0.093201876
},
{
"columnSpecName": "projects/292381/locations/us-central1/datasets/TBL543/tableSpecs/246/columnSpecs/638",
"columnDisplayName": "Month",
"featureImportance": 0.215029223
},
...
],
"trainBudgetMilliNodeHours": "1000",
"trainCostMilliNodeHours": "1000",
"classificationType": "BINARY",
"predictionSampleRows": [
...
],
"splitPercentageConfig": {
...
}
},
"creationState": "CREATED",
"deployedModelSizeBytes": "1160941568"
}
Java
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Node.js
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Python
La bibliothèque cliente AutoML Tables comprend des méthodes Python supplémentaires qui simplifient l'utilisation de l'API AutoML Tables. Ces méthodes référencent les ensembles de données et les modèles par nom et non par identifiant. L'ensemble de données et les noms de modèles doivent être uniques. Pour plus d'informations, consultez la documentation de référence du client.
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Importance des caractéristiques locales
L'importance des caractéristiques locales vous permet de savoir comment les caractéristiques individuelles présentes dans une requête de prédiction spécifique ont affecté la prédiction obtenue.
Pour obtenir la valeur d'importance de chaque caractéristique locale, le score de prédiction de référence est d'abord calculé. Les valeurs de référence sont calculées à partir des données d'entraînement, en utilisant la valeur médiane pour les caractéristiques numériques et le mode pour les caractéristiques catégorielles. La prédiction générée à partir des valeurs de référence correspond au score de prédiction de référence.
Pour les modèles de classification, l'importance des caractéristiques locales indique dans quelle mesure chaque caractéristique a été ajoutée ou soustraite à la probabilité attribuée à la classe ayant le score le plus élevé, par rapport au score de prédiction de référence. Les scores étant compris entre 0,0 et 1,0, l'importance des caractéristiques locales pour les modèles de classification est toujours comprise entre -1,0 et 1,0 (inclus).
Pour les modèles de régression, l'importance des caractéristiques locales dans une prédiction indique dans quelle mesure chaque caractéristique a été ajoutée à ou soustraite du résultat par rapport au score de prédiction de base.
L'importance des caractéristiques locales est disponible pour les prédictions en ligne et par lot.
Obtenir l'importance des caractéristiques locales pour les prédictions en ligne
Console
Pour obtenir les valeurs d'importance des caractéristiques locales pour une prédiction en ligne à l'aide de la console Google Cloud, suivez les étapes de la section Obtenir une prédiction en ligne en veillant à cocher la case Générer l'importance des caractéristiques.
REST
Pour obtenir l'importance des caractéristiques locales pour une requête de prédiction en ligne, utilisez
la méthode model.predict en définissant
le paramètre feature_importance sur "true".
Avant d'utiliser les données de requête, effectuez les remplacements suivants:
-
endpoint:
automl.googleapis.compour la zone internationale eteu-automl.googleapis.compour la région UE. - project-id : ID de votre projet Google Cloud.
- location : emplacement de la ressource :
us-central1pour l'emplacement mondial oueupour l'Union européenne. - model-id : ID du modèle. Par exemple,
TBL543. - valueN : valeurs de chaque colonne, dans le bon ordre.
Méthode HTTP et URL :
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict
Corps JSON de la requête :
{
"payload": {
"row": {
"values": [
value1, value2,...
]
}
}
"params": {
"feature_importance": "true"
}
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json et exécutez la commande suivante:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json et exécutez la commande suivante:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict" | Select-Object -Expand Content
"tablesModelColumnInfo": [
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/4704",
"columnDisplayName": "Promo",
"featureImportance": 1626.5464
},
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/6800",
"columnDisplayName": "Open",
"featureImportance": -7496.5405
},
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/9824",
"columnDisplayName": "StateHoliday"
}
],
Lorsqu'une colonne contient une valeur d'importance des caractéristiques de 0, l'importance de la caractéristique en cause n'apparaît pas dans cette colonne.
Java
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Node.js
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Python
La bibliothèque cliente AutoML Tables comprend des méthodes Python supplémentaires qui simplifient l'utilisation de l'API AutoML Tables. Ces méthodes référencent les ensembles de données et les modèles par nom et non par identifiant. L'ensemble de données et les noms de modèles doivent être uniques. Pour plus d'informations, consultez la documentation de référence du client.
Si vos ressources sont situées dans la région UE, vous devez définir explicitement le point de terminaison. En savoir plus
Obtenir l'importance des caractéristiques locales pour les prédictions par lot
Console
Pour obtenir des valeurs d'importance des caractéristiques locales pour une prédiction par lot à l'aide de la console Google Cloud, suivez les étapes de la section Demander une prédiction par lot en veillant à cocher la case Générer l'importance des caractéristiques.

L'importance des caractéristiques est renvoyée en ajoutant une colonne nommée feature_importance.<feature_name>
pour chaque caractéristique.
REST
Pour obtenir l'importance des caractéristiques locales pour une requête de prédiction par lot, utilisez
la méthode model.batchPredict en définissant
le paramètre feature_importance sur "true".
L'exemple suivant utilise BigQuery pour les données de requête et les résultats. Utilisez le même paramètre supplémentaire pour les requêtes utilisant Cloud Storage.
Avant d'utiliser les données de requête, effectuez les remplacements suivants:
-
endpoint:
automl.googleapis.compour la zone internationale eteu-automl.googleapis.compour la région UE. - project-id : ID de votre projet Google Cloud.
- location : emplacement de la ressource :
us-central1pour l'emplacement mondial oueupour l'Union européenne. - model-id : ID du modèle. Par exemple,
TBL543. - dataset-id: ID de l'ensemble de données BigQuery où se trouvent les données de prédiction.
-
table-id : ID de la table BigQuery où se trouvent les données de prédiction.
AutoML Tables crée un sous-dossier pour les résultats de prédiction nommé
prediction-<model_name>-<timestamp>dans project-id.dataset-id.table-id.
Méthode HTTP et URL :
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Corps JSON de la requête :
{
"inputConfig": {
"bigquerySource": {
"inputUri": "bq://project-id.dataset-id.table-id"
},
},
"outputConfig": {
"bigqueryDestination": {
"outputUri": "bq://project-id"
},
},
"params": {"feature_importance": "true"}
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json et exécutez la commande suivante:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json et exécutez la commande suivante:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
L'importance des caractéristiques est renvoyée en ajoutant une colonne nommée feature_importance.<feature_name>
pour chaque caractéristique.
Points à prendre en compte dans l'utilisation de l'importance des caractéristiques locales :
Les résultats sur l'importance des caractéristiques locales ne sont disponibles que pour les modèles entraînés à partir du 15 novembre 2019.
Il n'est pas possible d'activer l'importance des caractéristiques locales sur une requête de prédiction par lot comportant plus de 1 000 000 de lignes ou 300 colonnes.
Chaque valeur d'importance des caractéristiques locales indique simplement dans quelle mesure la caractéristique en cause a affecté la prédiction pour cette ligne. Pour comprendre le comportement global du modèle, utilisez l'importance des caractéristiques du modèle.
Les valeurs d'importance des caractéristiques locales sont toujours en rapport avec la valeur de référence. Veillez à indiquer la valeur de référence lorsque vous évaluez les résultats de l'importance de vos caractéristiques locales. La valeur de référence n'est disponible que dans la console Google Cloud.
Les valeurs d'importance des caractéristiques locales dépendent entièrement du modèle et des données utilisées pour l'entraîner. Elles ne peuvent indiquer que les motifs trouvés par le modèle dans les données et ne détectent aucune relation fondamentale parmi celles-ci. Par conséquent, la présence d'une valeur d'importance élevée pour une caractéristique donnée n'indique pas l'existence d'une relation entre cette caractéristique et la cible, mais simplement que le modèle utilise cet élément dans ses prédictions.
Si une prédiction inclut des données complètement en dehors de la plage des données d'entraînement, l'importance des caractéristiques locales peut ne pas fournir de résultats significatifs.
Générer l'importance des caractéristiques augmente le temps et les ressources de calcul nécessaires pour réaliser la prédiction. En outre, votre requête utilise un quota différent de celui des requêtes de prédiction sans l'importance des caractéristiques. En savoir plus
Les valeurs d'importance des caractéristiques ne vous indiquent pas si votre modèle est équitable, impartial ou de bonne qualité. Un examen minutieux de votre ensemble de données d'entraînement, de vos procédures, de vos métriques d'évaluation et de l'importance des caractéristiques est donc essentiel.