このページでは、特徴量の重要度を使用してモデルが予測を行う方法を説明します。
AI Explanationsの詳細については、AI Platform のAI Explanations の概要をご覧ください。
概要
機械学習モデルを使用してビジネス上の意思決定を行う場合、トレーニング データが最終モデルにどのように貢献し、またモデルでどのように個々の予測に到達したかを把握することが重要です。この点を把握しておくと、モデルを公正かつ正確なものにするのに役立ちます。
AutoML Tables が提供する特徴量の重要度(特徴の属性とも呼ばれる)によって、モデルのトレーニングに最も寄与した特徴(モデル特徴量の重要度)と個々の予測に最も寄与した特徴(ローカル特徴量の重要度)を確認できます。
AutoML Tables は、サンプリングされた Shapley メソッドを使用して特徴量の重要度を計算します。モデルの説明可能性の詳細については、AI Explanations の概要をご覧ください。
モデル特徴量の重要度
モデル特徴量の重要度によって、モデルのトレーニングに影響を与えた特徴が、データとビジネスの問題にとって意味のあるものであることを確認できます。特徴量の重要度の値が高いすべての特徴は、予測の有効なシグナルを表し、予測リクエストに一貫して含めることができる必要があります。
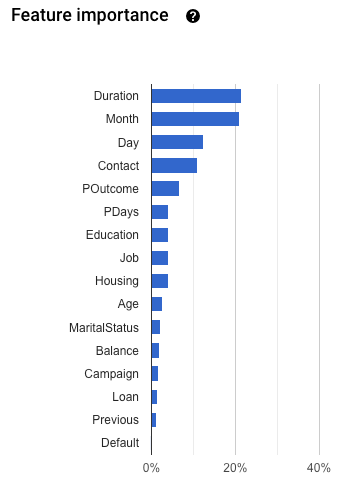
モデル特徴量の重要度は、各特徴量の割合で示されます。割合が高いほど、その特徴量がモデルトレーニングに強く影響します。
モデル特徴量の重要度を取得する
Console
Google Cloud Console を使用してモデルの特徴量の重要度の値を確認するには:
Google Cloud Console で [AutoML テーブル] ページに移動します。
左側のナビゲーション パネルで [モデル] タブを選択して、評価指標を取得したいモデルを選択します。
[評価] タブを開きます。
下にスクロールして [特徴量の重要度] グラフを表示します。
REST
モデルの特徴量の重要度の値を取得するには、model.getメソッドを使用します。
リクエストのデータを使用する前に、次のように置き換えます。
-
endpoint: グローバル ロケーションの場合は
automl.googleapis.com、EU リージョンの場合はeu-automl.googleapis.com。 - project-id: Google Cloud プロジェクト ID
- location:リソースのロケーション:グローバルの場合は
us-central1、EUの場合はeu。 -
model-id:特徴量の重要度情報を取得するモデルの ID。
例:
TBL543。
HTTP メソッドと URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
次のコマンドを実行します。
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id"
PowerShell
次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id" | Select-Object -Expand Content
{
"name": "projects/292381/locations/us-central1/models/TBL543",
"displayName": "Quickstart_Model",
...
"tablesModelMetadata": {
"targetColumnSpec": {
...
},
"inputFeatureColumnSpecs": [
...
],
"optimizationObjective": "MAXIMIZE_AU_ROC",
"tablesModelColumnInfo": [
{
"columnSpecName": "projects/292381/locations/us-central1/datasets/TBL543/tableSpecs/246/columnSpecs/331",
"columnDisplayName": "Contact",
"featureImportance": 0.093201876
},
{
"columnSpecName": "projects/292381/locations/us-central1/datasets/TBL543/tableSpecs/246/columnSpecs/638",
"columnDisplayName": "Month",
"featureImportance": 0.215029223
},
...
],
"trainBudgetMilliNodeHours": "1000",
"trainCostMilliNodeHours": "1000",
"classificationType": "BINARY",
"predictionSampleRows": [
...
],
"splitPercentageConfig": {
...
}
},
"creationState": "CREATED",
"deployedModelSizeBytes": "1160941568"
}
Java
リソースが EU リージョンにある場合は、エンドポイントを明示的に設定する必要があります。詳細
Node.js
リソースが EU リージョンにある場合は、エンドポイントを明示的に設定する必要があります。詳細
Python
AutoML Tables のクライアント ライブラリには、AutoML Tables API を簡単に使用できるようにする追加の Python メソッドが含まれています。これらのメソッドは、ID ではなく名前でデータセットとモデルを参照します。データセット名とモデル名は一意である必要があります。詳細については、クライアント リファレンスをご覧ください。
リソースが EU リージョンにある場合は、エンドポイントを明示的に設定する必要があります。詳細
ローカル特徴量の重要度
ローカル特徴量の重要度によって、特定の予測リクエスト内の個々の特徴が予測結果にどの程度影響を与えたかを把握できます。
各ローカル特徴量の重要度の値を算出するには、まずベースライン予測スコアを計算します。ベースライン値は、数値特徴の中央値とカテゴリ型の特徴のモードを使用して、トレーニング データから計算されます。ベースライン値から生成される予測が、ベースライン予測スコアです。
分類モデルの場合、ローカル特徴量の重要度は、ベースライン予測スコアと比較して、最も高いスコアを持つクラスに割り当てられた確率に各特徴によってどのくらいの加算または減算が生じたかを示します。スコアの値は 0.0~1.0 です。したがって、分類モデルのローカル特徴量の重要度は常に -1.0~1.0 です。
回帰モデルの場合、予測のローカル特徴量の重要度により、ベースラインの予測スコアと比較して、結果に各特徴によってどのくらいの加算または減算が生じたかを示します。
ローカル特徴量の重要度は、オンライン予測とバッチ予測の両方で使用できます。
オンライン予測のローカル特徴量の重要度を取得する
Console
Google Cloud Console を使用してオンライン予測のローカル特徴量の重要度の値を取得するには、オンライン予測の取得の手順に従い、[特徴量の重要度を生成する]チェックボックスをオンにします。
REST
オンライン予測リクエストのローカル特徴量の重要度を取得するには、feature_importanceパラメータを true に設定して、model.predictメソッドを使用します。
リクエストのデータを使用する前に、次のように置き換えます。
-
endpoint: グローバル ロケーションの場合は
automl.googleapis.com、EU リージョンの場合はeu-automl.googleapis.com。 - project-id: Google Cloud プロジェクト ID
- location:リソースのロケーション:グローバルの場合は
us-central1、EUの場合はeu。 - model-id:モデルの ID。例:
TBL543 - valueN: 正しい順序で並べ替えた各列の値。
HTTP メソッドと URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict
リクエストの本文(JSON):
{
"payload": {
"row": {
"values": [
value1, value2,...
]
}
}
"params": {
"feature_importance": "true"
}
}
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict"
PowerShell
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict" | Select-Object -Expand Content
"tablesModelColumnInfo": [
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/4704",
"columnDisplayName": "Promo",
"featureImportance": 1626.5464
},
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/6800",
"columnDisplayName": "Open",
"featureImportance": -7496.5405
},
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/9824",
"columnDisplayName": "StateHoliday"
}
],
列の特徴量の重要度の値が 0 の場合、その列の特徴量の重要度は表示されません。
Java
リソースが EU リージョンにある場合は、エンドポイントを明示的に設定する必要があります。詳細
Node.js
リソースが EU リージョンにある場合は、エンドポイントを明示的に設定する必要があります。詳細
Python
AutoML Tables のクライアント ライブラリには、AutoML Tables API を簡単に使用できるようにする追加の Python メソッドが含まれています。これらのメソッドは、ID ではなく名前でデータセットとモデルを参照します。データセット名とモデル名は一意である必要があります。詳細については、クライアント リファレンスをご覧ください。
リソースが EU リージョンにある場合は、エンドポイントを明示的に設定する必要があります。詳細
バッチ予測のローカル特徴量の重要度を取得する
Console
Google Cloud Console を使用してバッチ予測のローカル特徴量の重要度の値を取得するには、バッチ予測のリクエストの手順に従い、[特徴量の重要度を生成]チェックボックスをオンにします。
すべての特徴に feature_importance.<feature_name> という名前の新しい列を追加することで、特徴量の重要度が返されます。
REST
バッチ予測リクエストのローカル特徴量の重要度を取得するには、feature_importance パラメータを true に設定して、model.batchPredict メソッドを使用します。
次の例では、リクエストデータと結果に BigQuery を使用しています。Cloud Storage を使用するリクエストと同じ追加パラメータを使用します。
リクエストのデータを使用する前に、次のように置き換えます。
-
endpoint: グローバル ロケーションの場合は
automl.googleapis.com、EU リージョンの場合はeu-automl.googleapis.com。 - project-id: Google Cloud プロジェクト ID
- location:リソースのロケーション:グローバルの場合は
us-central1、EUの場合はeu。 - model-id:モデルの ID。例:
TBL543 - dataset-id: 予測データが配置されている BigQuery データセットの ID。
-
table-id: 予測データが存在する BigQuery テーブルの ID。
AutoML Tables は、
prediction-<model_name>-<timestamp>という名前の予測結果のサブフォルダをproject-id.dataset-id.table-idに作成します。
HTTP メソッドと URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
リクエストの本文(JSON):
{
"inputConfig": {
"bigquerySource": {
"inputUri": "bq://project-id.dataset-id.table-id"
},
},
"outputConfig": {
"bigqueryDestination": {
"outputUri": "bq://project-id"
},
},
"params": {"feature_importance": "true"}
}
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
すべての特徴に feature_importance.<feature_name> という名前の新しい列を追加することで、特徴量の重要度が返されます。
ローカル特徴量の重要度の使用に関する考慮事項:
ローカル特徴量の重要度の結果は、2019 年 11 月 15 日以降にトレーニングされたモデルでのみ使用できます。
1,000,000 行または 300 列を超えるバッチ予測リクエストでは、ローカル特徴量の重要度を有効にすることはできません。
各ローカル特徴量の重要度の値は、特徴がその行の予測にどの程度影響したかを示します。モデルの全体的な動作を理解するには、モデルの特徴量の重要度を使用します。
ローカル特徴量の重要度の値は、常にベースライン値に対して相対的です。ローカル特徴量の重要度の結果を評価する際は、必ずベースライン値を参照してください。ベースライン値は、Google Cloud コンソールからのみ使用できます。
ローカル特徴量の重要度の値は、モデルとモデルのトレーニングに使用されるデータに完全に依存します。データ内でモデルが検出したパターンのみを示すことができ、データ内の基本的な関係を検出することはできません。つまり、特定の特徴量の重要度が高い場合、その特徴と対象物の間の関係を示しているわけではなく、単にモデルがその予測で特徴を使用していることを示しています。
予測にトレーニング データから完全に外れたデータが含まれている場合、ローカル特徴量の重要度から意味のある結果が得られない可能性があります。
特徴量の重要度を生成すると、予測に必要な時間とコンピューティング リソースが増加します。また、リクエストで使用される割り当ては、特徴量の重要性を持たない予測リクエストとは異なります。詳細
特徴量の重要度の値だけでは、モデルが公平で偏りがなく、高品質であるかどうかはわかりません。特徴量の重要度に加えて、トレーニング データセット、手順、評価指標を慎重に評価する必要があります。