このページでは、モデルをトレーニングした後で評価指標を使用する方法について説明し、モデルのパフォーマンスが向上する方法についての基本的な提案を紹介します。
はじめに
モデルをトレーニングした後、AutoML Tables はテスト データセットを使用して新しいモデルの品質と正確性を評価し、モデルがテスト データセットに対してどの程度うまく機能したかを示す評価指標を提供します。
評価指標を使用したモデルの品質判定は、ビジネスニーズや、モデルをトレーニングして解決する問題によって異なります。たとえば、偽陰性より偽陽性のほうがコストが高くなる場合も、その逆の場合もあります。回帰モデルの場合は、予測と正解の間の差異は重要でしょうか。こうした種類の質問は、モデル評価指標についてどう考えるかに影響します。
トレーニング データに重み列を含めても、評価指標には影響しません。重みはトレーニング段階の間だけ考慮されます。
分類モデルの評価指標
分類モデルは、以下の指標を提供します。
AUC PR: 適合率 / 再現率(PR)曲線の下の面積。この値は範囲が 0~1 で、値が高いほど高品質のモデルであることを示します。
AUC ROC: 受信者操作特性(ROC)曲線の下の面積。この範囲は 0~1 で、値が高いほど高品質のモデルであることを示します。
精度: 正しいモデルによって生成された分類予測の割合。
ログ損失: モデル予測とターゲット値の間のクロス エントロピー。この範囲はゼロから無限大までで、値が低いほど高品質のモデルであることを示します。
F1 スコア: 適合率と再現率の調和平均。適合率と再現率のバランスを求めていて、クラス分布が不均一な場合、F1 は有用な指標となります。
適合率: 正しいモデルによって生成された肯定の予測の割合(肯定の予測は偽陽性と真陽性を組み合わせたものです)。
再現率: モデルによって正しく予測された、このラベルが付けられた行の割合。「真陽性率」とも呼ばれます。
偽陽性率: モデルによりターゲット ラベルと予測されたがそうでなかった(偽陽性)行の割合。
これらの指標は、ターゲット列の固有値ごとに返されます。マルチクラス分類モデルの場合、これらの指標はマイクロ平均化され、サマリー指標として返されます。バイナリ分類モデルの場合、少数派クラスの指標がサマリー指標として使用されます。マイクロ平均指標は、データセットのランダム サンプルの各指標の期待値です。
上記の指標に加えて、AutoML Tables には、分類モデル、混同行列、特徴量の重要度グラフを理解するための 2 つの方法があります。
混同行列: 混同行列は、誤分類がどこで発生したか(どのクラスが互いに「混同」されているか)を知るのに役立ちます。各行は特定のラベルの正解(グラウンド トゥルース)を表し、各列はモデルによって予測されたラベルを示します。
混同行列は、ターゲット列の値が 10 以下の分類モデルにのみ適用されます。

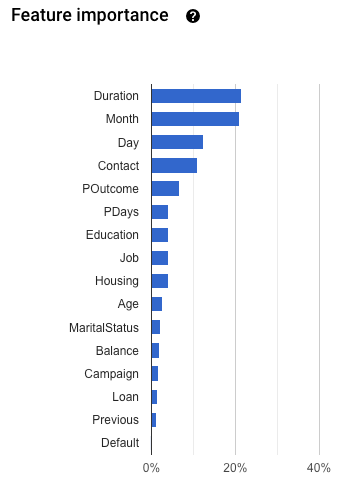
特徴量の重要度: AutoML Tables では、各特徴量がこのモデルに及ぼす影響が示されます。具体的には、特徴量の重要度グラフに表示されます。値は、各特徴量の割合で表します。割合が高いほど、その特徴量はモデルのトレーニングに大きく影響します。
この情報を確認して、特に重要な特徴量すべてがデータとビジネスの問題に対して適切であることを確認してください。詳しくは、説明可能性をご覧ください。
マイクロ平均適合率の計算方法
マイクロ平均適合率は、ターゲット列の各潜在値の真陽性(TP)の数を合計し、各潜在値の真陽性(TP)と真陰性(TN)の数で除算することで計算されます。
\[ precision_{micro} = \dfrac{TP_1 + \ldots + TP_n} {TP_1 + \ldots + TP_n + FP_1 + \ldots + FP_n} \]
それぞれの意味は次のとおりです。
- \(TP_1 + \ldots + TP_n\) は、n 個の各クラスの真陽性の合計です。
- \(FP_1 + \ldots + FP_n\) は、n 個の各クラスの偽陽性の合計です。
スコアしきい値
スコアしきい値は、0~1 の範囲の数値です。特定の予測値を真とする最小信頼レベルを指定する方法を提供します。たとえば、実際の値になる可能性が非常に低いクラスがある場合は、そのクラスのしきい値を下げる必要があります。.5 以上のしきい値を使用すると、そのクラスはほとんど(またはまったく)予測されなくなります。
しきい値を高くすると偽陽性が減少しますが、偽陰性は増えます。しきい値を低くすると偽陰性が減少しますが、偽陽性は増えます。
言い換えれば、スコアしきい値は適合率と再現率に影響します。しきい値を高くすると適合率が高くなります(モデルは非常に確かでない限り予測を行わないため)が、再現率(モデルが正しく判定できた陽性の例の割合)は低くなります。
回帰モデルの評価指標
回帰モデルは、以下の指標を提供します。
MAE: 平均絶対誤差(MAE)とは、ターゲット値と予測値との間の平均絶対差のことです。この指標の範囲はゼロから無限大までで、値が小さいほど高品質のモデルであることを示します。
RMSE: 二乗平均平方根誤差の指標は、モデルまたは Estimator によって予測された値と、観察された値との差を表すためによく使用される測定方法です。この指標の範囲はゼロから無限大までで、値が小さいほど高品質のモデルであることを示します。
RMSLE: 二乗平均対数平方誤差の指標は、RMSE と似ていますが、予測値と実測値に 1 を加えた自然対数を使用する点が異なります。RMSLE は、過剰予測よりも過小予測に重いペナルティを与えます。小さい予測値の差よりも大きい予測値の差のペナルティが重くならないようにする場合にも、この指標を使用することをおすすめします。この指標の範囲はゼロから無限大までで、値が小さいほど高品質のモデルであることを示します。RMSLE 評価指標は、すべてのラベルと予測値が負でない場合にのみ返されます。
r^2: r 2 乗(r^2)は、ラベルと予測値間のピアソン相関係数の 2 乗です。この指標の範囲は 0~1 で、値が高いほどモデルが高品質であることを示します。
MAPE: 平均絶対パーセント誤差(MAPE)とは、ラベルと予測値との平均絶対パーセント差です。この指標の範囲はゼロから無限大までで、値が低いほど高品質のモデルであることを示します。
ターゲット列に 0 の値が含まれている場合、MAPE は表示されません。この場合、MAPE は未定義です。
特徴量の重要度: AutoML Tables では、各特徴量がこのモデルに及ぼす影響が示されます。具体的には、特徴量の重要度グラフに表示されます。値は、各特徴量の割合で表します。割合が高いほど、その特徴量はモデルのトレーニングに大きく影響します。
この情報を確認して、特に重要な特徴量すべてがデータとビジネスの問題に対して適切であることを確認してください。詳しくは、説明可能性をご覧ください。
モデルの評価指標を取得する
モデルがテスト データセットに対してどの程度良好に機能したかを評価するには、モデルの評価指標を調べます。
Console
Google Cloud Console を使用してモデルの評価指標を確認するには:
Google Cloud Console で [AutoML テーブル] ページに移動します。
左側のナビゲーション パネルで [モデル] タブを選択して、評価指標を取得したいモデルを選択します。
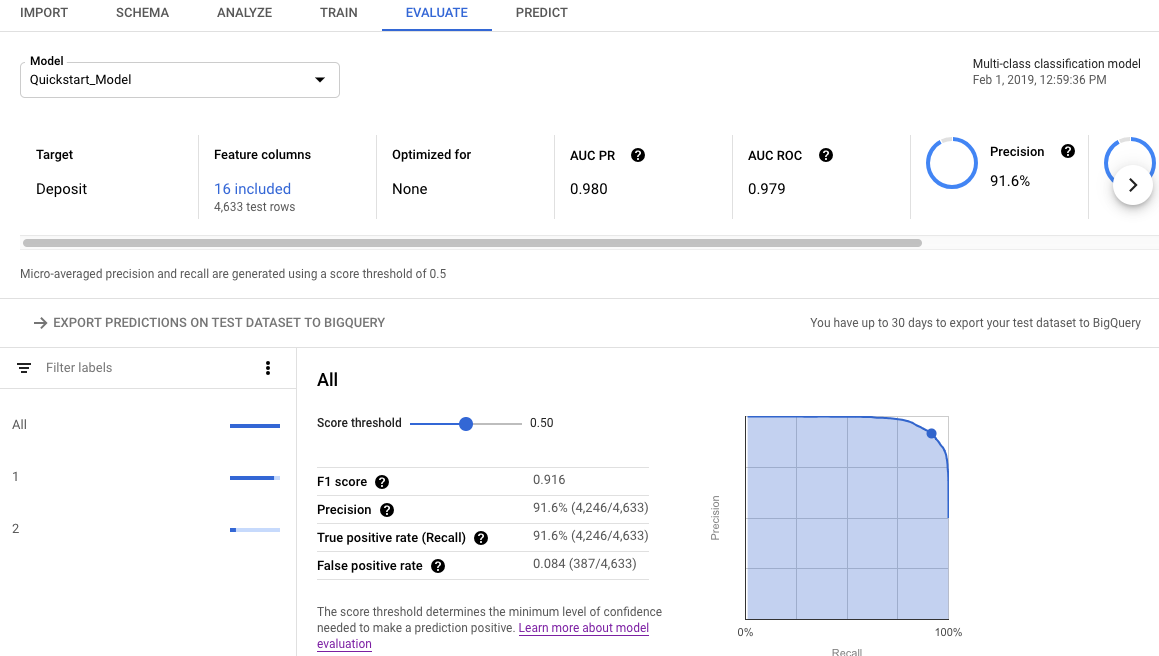
[評価] タブを開きます。
サマリー評価指標が画面の上部に表示されます。バイナリ分類モデルの場合、サマリー指標は少数派クラスの指標です。マルチクラス分類モデルの場合、サマリー指標はマイクロ平均指標です。
分類指標では、個々のターゲット値をクリックして、その値の指標を確認できます。
REST
Cloud AutoML API を使用してモデルの評価指標を取得するには、modelEvaluations.list メソッドを使用します。
リクエストのデータを使用する前に、次のように置き換えます。
-
endpoint: グローバル ロケーションの場合は
automl.googleapis.com、EU リージョンの場合はeu-automl.googleapis.com。 - project-id: Google Cloud プロジェクト ID
- location:リソースのロケーション:グローバルの場合は
us-central1、EUの場合はeu。 -
model-id: 評価するモデルの ID。例:
TBL543。
HTTP メソッドと URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
次のコマンドを実行します。
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/"
PowerShell
次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id/modelEvaluations/" | Select-Object -Expand Content
Java
リソースが EU リージョンにある場合は、エンドポイントを明示的に設定する必要があります。詳細
Node.js
リソースが EU リージョンにある場合は、エンドポイントを明示的に設定する必要があります。詳細
Python
AutoML Tables のクライアント ライブラリには、AutoML Tables API を簡単に使用できるようにする追加の Python メソッドが含まれています。これらのメソッドは、ID ではなく名前でデータセットとモデルを参照します。データセット名とモデル名は一意である必要があります。詳細については、クライアント リファレンスをご覧ください。
リソースが EU リージョンにある場合は、エンドポイントを明示的に設定する必要があります。詳細
API を使用した評価結果を把握する
Cloud AutoML API を使用してモデル評価指標を取得すると、大量の情報が返されます。指標の結果の構造を理解すると、結果を解釈してモデルの評価に使用できます。
分類の結果
分類モデルの場合、結果には複数の ModelEvaluation オブジェクトが含まれ、各オブジェクトには複数の ConfidenceMetricsEntry オブジェクトが含まれます。結果の構造を理解することで、モデルの評価に使用する適切なオブジェクトを選択できます。
トレーニング データに存在するターゲット列の個別の値ごとに、2 つの ModelEvaluation オブジェクトが返されます。さらに、2 つのサマリー ModelEvaluation オブジェクトと、無視できる 1 つの空の ModelEvaluation オブジェクトがあります。
特定のラベル値に対して返される 2 つの ModelEvaluation オブジェクトは、displayName フィールドにラベル値を表示します。これらは、1 および MAX_INT(可能な最大数)のそれぞれ異なる位置しきい値を使用します。位置しきい値は、予測で考慮される結果の数を決定します。分類問題では、入力ごとに 1 つのラベルしか選択されないため、ほとんどの場合、位置しきい値を 1 に設定するのが最適です。マルチラベルの問題では、入力ごとに複数のラベルを選択できるため、MAX_INT 位置しきい値に対して返される評価指標の方が便利な場合があります。モデルの特定のユースケースに基づいて、使用する指標を決定する必要があります。
2 つのサマリー ModelEvaluation オブジェクトには、混同行列の一部を除いて displayName フィールドは含まれません。また、evaluatedExampleCount フィールドの値はトレーニング データの行の合計数です。マルチクラス分類モデルの場合、サマリー オブジェクトは、ラベルごとのすべての指標に基づいてマイクロ平均指標を提供します。バイナリ分類モデルの場合、少数派クラスの指標がサマリー指標として使用されます。サマリー指標には、位置しきい値が 1 の ModelEvaluation オブジェクトを使用します。
各 ModelEvaluation オブジェクトには、トレーニング データに応じて最大 100 個の ConfidenceMetricsEntry オブジェクトが含まれます。各 ConfidenceMetricsEntry オブジェクトは、信頼度のしきい値(スコアしきい値とも呼ばれる)に異なる値を提供します。
サマリー ModelEvaluation オブジェクトは次の例のようになります。フィールドの表示順序は異なる場合があります。
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/18011"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 1013
classification_evaluation_metrics {
au_roc: 0.99749845
log_loss: 0.01784837
au_prc: 0.99498594
confidence_metrics_entry {
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
confidence_metrics_entry {
confidence_threshold: 0.0149591835
recall: 0.99506414
precision: 0.99506414
f1_score: 0.99506414
false_positive_rate: 0.002467917
true_positive_count: 1008
false_positive_count: 5
false_negative_count: 5
true_negative_count: 2021
position_threshold: 1
}
...
confusion_matrix {
row {
example_count: 519
example_count: 2
example_count: 0
}
row {
example_count: 3
example_count: 75
example_count: 0
}
row {
example_count: 0
example_count: 0
example_count: 414
}
display_name: "RED"
display_name: "BLUE"
display_name: "GREEN"
}
}
}
ラベル固有の ModelEvaluation オブジェクトは次の例のようになります。フィールドの表示順序は異なる場合があります。
model_evaluation {
name: "projects/8628/locations/us-central1/models/TBL328/modelEvaluations/21860"
annotation_spec_id: "not available"
create_time {
seconds: 1575513478
nanos: 163446000
}
evaluated_example_count: 521
classification_evaluation_metrics {
au_prc: 0.99933827
au_roc: 0.99889404
log_loss: 0.014250426
confidence_metrics_entry {
recall: 1.0
precision: 0.51431394
f1_score: 0.6792699
false_positive_rate: 1.0
true_positive_count: 521
false_positive_count: 492
position_threshold: 2147483647
}
confidence_metrics_entry {
confidence_threshold: 0.10562216
recall: 0.9980806
precision: 0.9904762
f1_score: 0.9942639
false_positive_rate: 0.010162601
true_positive_count: 520
false_positive_count: 5
false_negative_count: 1
true_negative_count: 487
position_threshold: 2147483647
}
...
}
display_name: "RED"
}
回帰の結果
回帰モデルの場合、次の例のような出力が表示されます。
{
"modelEvaluation": [
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/68066093",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418
},
{
"name": "projects/1234/locations/us-central1/models/TBL2345/modelEvaluations/852167724",
"createTime": "2019-05-15T22:33:06.471561Z",
"evaluatedExampleCount": 418,
"regressionEvaluationMetrics": {
"rootMeanSquaredError": 1.9845301,
"meanAbsoluteError": 1.48482,
"meanAbsolutePercentageError": 15.155516,
"rSquared": 0.6057632,
"rootMeanSquaredLogError": 0.16848126
}
}
]
}
モデルの問題のトラブルシューティング
モデル評価指標は問題ないはずですが、完璧ではありません。モデル パフォーマンスは低くても完璧でも、トレーニング プロセスで何か誤りがあったことを示しています。
低いパフォーマンス
モデルのパフォーマンスが期待ほど良好でなかった場合は、次の点を確認してください。
スキーマを見直す
すべての列の型が正しいこと、そして ID 列といった予測されない列をトレーニングから除外したことを確認してください。
データを見直す
null 値を許容しない列に値がないと、その行は無視されます。データ内のエラーが多すぎないようにしてください。
テスト データセットをエクスポートして調べる
データを検査して、モデルがいつ誤った予測を行っているかを分析することで、特定の結果に対してさらにトレーニング データが必要であるかや、トレーニング データに漏出が発生したかがわかる可能性があります。
トレーニング データの量を増やす
トレーニング データが十分でないと、モデルの品質が低下します。トレーニング データにできるだけ偏りがないようにしてください。
トレーニング時間を増やす
トレーニング時間が短かった場合は、より長い期間トレーニングできるようにすることで、より高品質のモデルが得られるかもしれません。
完璧なパフォーマンス
モデルがほぼ完璧な評価指標を返した場合は、トレーニング データで何かが間違っている場合があります。次の点を確認してください。
ターゲットの漏出
ターゲットの漏出は、トレーニング時には把握できない、結果に基づいた特徴がトレーニング データに含まれている場合に発生します。たとえば、初めて購入を行うユーザーが実際に購入するかどうかを判断できるようトレーニングするモデルに常連購入者番号を含めた場合、そのモデルの評価指標は非常に高くなります。しかし実際のデータでは常連購入者番号を含められないため、パフォーマンスが低くなります。
ターゲットの漏出がないか調べるには、モデルの [評価] タブで特徴量の重要度グラフを確認します。重要度の高い列が真に予測的で、ターゲットに関する情報を漏出していないことを確認してください。
時間列
データの時刻が重要な場合は、「時間」列または時間に基づく手動分割を使用していることを確認してください。そうしないと、評価指標が歪む可能性があります。詳細
テスト データセットを BigQuery にダウンロードする
テスト データセットを、ターゲット列も含めて、モデルの各行の結果と一緒にダウンロードできます。モデルが誤りを出した行を調べると、モデルを改善する方法についての手がかりが得られます。
Google Cloud コンソールで [AutoML Tables] を開きます。
左側のナビゲーション パネルで [モデル] を選択し、使用するモデルをクリックします。
[評価] タブを開いて、[テスト データセットの予測を BigQuery にエクスポート] をクリックします。
エクスポートが完了したら、[BigQuery で評価結果を表示] をクリックしてデータを確認します。
次のステップ
- モデルをデプロイしてオンライン予測を取得する。
- モデルからバッチ予測を取得する。