Introduction
Imagine you work in the marketing department for a digital retailer. You and your team are creating a personalized email program based on customer personas. You've created the personas and have the marketing emails ready to go. Now you need to create a system that buckets customers into each persona based on retail preferences and spending behavior, even if they're new. You also want to predict their spending habits so you can optimize when to send the emails to maximize engagement.

Because you're a digital retailer, you've got data on your customers and the purchases they've made. But what about new customers? Traditional approaches can calculate these values for existing customers with long purchase histories, but don't do well with customers with little historical data. What if you could create a system to predict these values and increase the speed at which you deliver personalized marketing programs to customers?
Fortunately, machine learning and AutoML Tables is well positioned to solve these problems. This guide walks you through how AutoML Tables works and the kinds of problems it's designed to solve.
How does AutoML Tables work?
 AutoML Tables is a supervised learning service. This means that you
train a machine learning model with example data. AutoML Tables uses
tabular (structured) data to train a machine learning model to make predictions
on new data. One column from your dataset, called the target, is what your
model will learn to predict. Some number of the other data columns are inputs
(called features) that the model will learn patterns from. You can use
the same input features to build multiple kinds of models just by changing the
target. From the email marketing example, this means you could build two models
with the same input features: One model could predict a customer's persona
(a categorical target), and one could predict their monthly spending (a numerical target).
AutoML Tables is a supervised learning service. This means that you
train a machine learning model with example data. AutoML Tables uses
tabular (structured) data to train a machine learning model to make predictions
on new data. One column from your dataset, called the target, is what your
model will learn to predict. Some number of the other data columns are inputs
(called features) that the model will learn patterns from. You can use
the same input features to build multiple kinds of models just by changing the
target. From the email marketing example, this means you could build two models
with the same input features: One model could predict a customer's persona
(a categorical target), and one could predict their monthly spending (a numerical target).

The AutoML Tables workflow
AutoML Tables uses a standard machine learning workflow:
- Gather your data: Determine the data you need for training and testing your model based on the outcome you want to achieve
- Prepare your data: Make sure your data is properly formatted before and after data import
- Train: Set parameters and build your model
- Evaluate: Review model metrics
- Test: Try your model on test data
- Deploy and predict: Make your model available to use
But before you start gathering your data, you'll want to think about the problem you're trying to solve, which will inform your data requirements.
Consider your use case

Start with your problem: What is the outcome you want to achieve? What kind of data is the target column? How much data do you have access to?
Depending on yours answers, AutoML Tables will create the necessary model to solve your use case:
A binary classification model predicts a binary outcome (one of two classes). Use this for yes or no questions, for example, predicting whether a customer would buy a subscription (or not). All else being equal, a binary classification problem requires less data than other model types.
A multi-class classification model predicts one class from three or more discrete classes. Use this to categorize things. For the retail example, you'd want to build a multi-class classification model to segment customers into different personas.
A regression model predicts a continuous value. For the retail example, you'd also want to build a regression model to forecast customer spending over the next month.
AutoML Tables will automatically define your problem and model to build based on the data type of your target column. So if your target column contains numerical data, then AutoML Tables will build a regression model. If your target column is categorical data, AutoML Tables will detect the number of classes and determine if you need to build a binary or multi-class model.
A note about fairness
Fairness is one of Google's responsible AI practices. The goal of fairness is to understand and prevent unjust or prejudicial treatment to people based on race, income, sexual orientation, religion, gender, and other characteristics historically associated with discrimination and marginalization, when and where they manifest in algorithmic systems or algorithmically aided decision-making. As you read this guide, you'll see "Fair-aware" notes that talk more about how to create a fairer machine learning model. Learn more
Gather your data
 After you've established your use case, you'll need to gather data to train your model.
Data sourcing and preparation are critical steps for building a machine learning
model. The data you have available will inform the kind of problems you can solve.
How much data do you have available? Are your data relevant to the questions you're
trying to answer? While gathering your data, keep in mind the following key considerations.
After you've established your use case, you'll need to gather data to train your model.
Data sourcing and preparation are critical steps for building a machine learning
model. The data you have available will inform the kind of problems you can solve.
How much data do you have available? Are your data relevant to the questions you're
trying to answer? While gathering your data, keep in mind the following key considerations.
Select relevant features
A feature is an input attribute used for model training. Features are how your model identifies patterns to make predictions, so they need to be relevant to your problem. For example, to build a model that predicts whether a credit card transaction is fraudulent or not, you'll need to build a dataset that contains transaction details like the buyer, seller, amount, date and time, and items purchased. Other helpful features could be historic information about the buyer and seller, and how often the item purchased has been involved in fraud. What other features might be relevant?
Let's consider the retail email marketing use case from the introduction. Here's some feature columns you might require:
- List of items purchased (including brands, categories, prices, discounts)
- Number of items purchased (last day, week, month, year)
- Sum of money spent (last day, week, month, year)
- Known demographic profile of shopper
Include enough data
 In general, the more training examples you have, the better your outcome. The
amount of example data required also scales with the complexity of the problem
you're trying to solve. You won't need as much data to get an accurate binary
classification model compared to a multi-class model because it's less complicated
to predict one class from two rather than many.
In general, the more training examples you have, the better your outcome. The
amount of example data required also scales with the complexity of the problem
you're trying to solve. You won't need as much data to get an accurate binary
classification model compared to a multi-class model because it's less complicated
to predict one class from two rather than many.
There's no perfect formula, but there are recommended minimum rows of example data:
- Classification problem: 50 x the number features
- Regression problem: 200 x the number of features
Capture variation
Your dataset should capture the diversity of your problem space. The more diverse examples a model sees during training, the more readily it can generalize to new or less common examples. Imagine if your retail model was trained only using purchase data from the winter. Would it be able to successfully predict summer clothing preferences or purchase behaviors?
Prepare your data

After you've identified your available data, you need to make sure it's ready for training. If your data is biased or contains missing or erroneous values, your model will reflect those in its training. Consider the following before you start training your model. Learn more
Prevent data leakage and training-serving skew
Data leakage is when you use input features during training that "leak" information about the target that you are trying to predict which is unavailable when the model is actually served. This can be detected when a feature that is highly correlated with the target column is included as one of the input features. For example, if you're building a model to predict whether a customer will sign up for a subscription in the next month and one of the input features is a future subscription payment from that customer. This can lead to strong model performance during testing, but not when deployed in production, since future subscription payment information isn't available at serving time.
Training-serving skew is when input features used during training time are different from the ones provided to the model at serving time, causing poor model quality in production. For example, building a model to predict hourly temperatures but training with data that only contains weekly temperatures. Another example: always providing a student's grades in the training data when predicting student dropout, but not providing this information at serving time.
Understanding your training data is important to preventing data leakage and training-serving skew:
- Before using any data, make sure you know what the data means and whether or not you should use it as a feature
- Check the correlation in the Train tab. High correlations should be flagged for review.
- Training-serving skew: make sure you only provide input features to the model that are available in the exact same form at serving time.
Clean up missing, incomplete, and inconsistent data
It's common to have missing and inaccurate values in your example data. Take time to review and, when possible, improve your data quality before using it for training. The more missing values, the less useful your data will be for training a machine learning model.
Check your data for missing values and correct them if possible, or leave the value blank if the column is set to be nullable. AutoML Tables can handle missing values, but you are more likely to get optimal results if all values are available.
Clean your data by correcting or deleting data errors or noise. Make your data consistent: Review spelling, abbreviations, and formatting.
Analyze your data after importing
AutoML Tables provides an overview of your dataset after it's been imported. Review your imported dataset to make sure each column has the correct variable type. AutoML Tables will automatically detect the variable type based on the columns values, but it's best to review each one. You should also review each column's nullability, which determines whether a column can have missing or NULL values.
Train your model
After your dataset is imported, the next step is to train a model. AutoML Tables will generate a reliable machine learning model with the training defaults, but you may want to adjust some of the parameters based on your use case.
Try to select as many feature columns as possible for training, but review each to make sure that it's appropriate for training. Keep in mind the following for feature selection:
- Don't select feature columns that will create noise, like randomly assigned identifier columns with a unique value for each row.
- Make sure you understand each feature column and its values.
- If you're creating multiple models from one dataset, remove target columns that aren't part of the current prediction problem.
- Recall the fairness principles: Are you training your model with a feature that could lead to biased or unfair decision-making for marginalized groups?
How AutoML Tables uses your dataset
Your dataset will be split into training, validation and testing sets. By default, AutoML Tables uses 80% of your data for training, 10% for validation, and 10% for testing, but you can manually edit those values if necessary.

Training Set
 The vast majority of your data should be in the training set. This is the data
your model "sees" during training: it's used to learn the parameters of the
model, namely the weights of the connections between nodes of the neural network.
The vast majority of your data should be in the training set. This is the data
your model "sees" during training: it's used to learn the parameters of the
model, namely the weights of the connections between nodes of the neural network.
Validation Set
 The validation set, sometimes also called the "dev" set, is also used during
the training process. After the model learning framework incorporates training
data during each iteration of the training process, it uses the model's performance
on the validation set to tune the model's hyperparameters, which are variables
that specify the model's structure. If you tried to use the training set to
tune the hyperparameters, it's quite likely the model would end up overly
focused on your training data, and have a hard time generalizing to examples
that don't exactly match it. Using a somewhat novel dataset to fine-tune model
structure means your model will generalize better.
The validation set, sometimes also called the "dev" set, is also used during
the training process. After the model learning framework incorporates training
data during each iteration of the training process, it uses the model's performance
on the validation set to tune the model's hyperparameters, which are variables
that specify the model's structure. If you tried to use the training set to
tune the hyperparameters, it's quite likely the model would end up overly
focused on your training data, and have a hard time generalizing to examples
that don't exactly match it. Using a somewhat novel dataset to fine-tune model
structure means your model will generalize better.
Test Set
 The test set is not involved in the training process at all. Once the model
has completed its training entirely, AutoML Tables uses the test set as an entirely new
challenge for your model. The performance of your model on the test set is
intended to give you a pretty good idea of how your model will perform on
real-world data.
The test set is not involved in the training process at all. Once the model
has completed its training entirely, AutoML Tables uses the test set as an entirely new
challenge for your model. The performance of your model on the test set is
intended to give you a pretty good idea of how your model will perform on
real-world data.
Evaluate your model
 After model training, you'll receive a summary of its performance. Model evaluation
metrics are based on how the model performed against a slice of your dataset
(the test dataset). There are a couple key metrics and concepts to consider
when determining whether your model is ready to be used in real data.
After model training, you'll receive a summary of its performance. Model evaluation
metrics are based on how the model performed against a slice of your dataset
(the test dataset). There are a couple key metrics and concepts to consider
when determining whether your model is ready to be used in real data.
Classification metrics
Score threshold
Consider a machine learning model that predicts whether a customer will buy a jacket in the next year. How sure does the model need to be before predicting that a given customer will buy a jacket? In classification models, each prediction is assigned a confidence score – a numeric assessment of the model's certainty that the predicted class is correct. The score threshold is the number that determines when a given score is converted into a yes or no decision; that is, the value at which your model says "yes, this confidence score is high enough to conclude that this customer will purchase a coat in the next year."
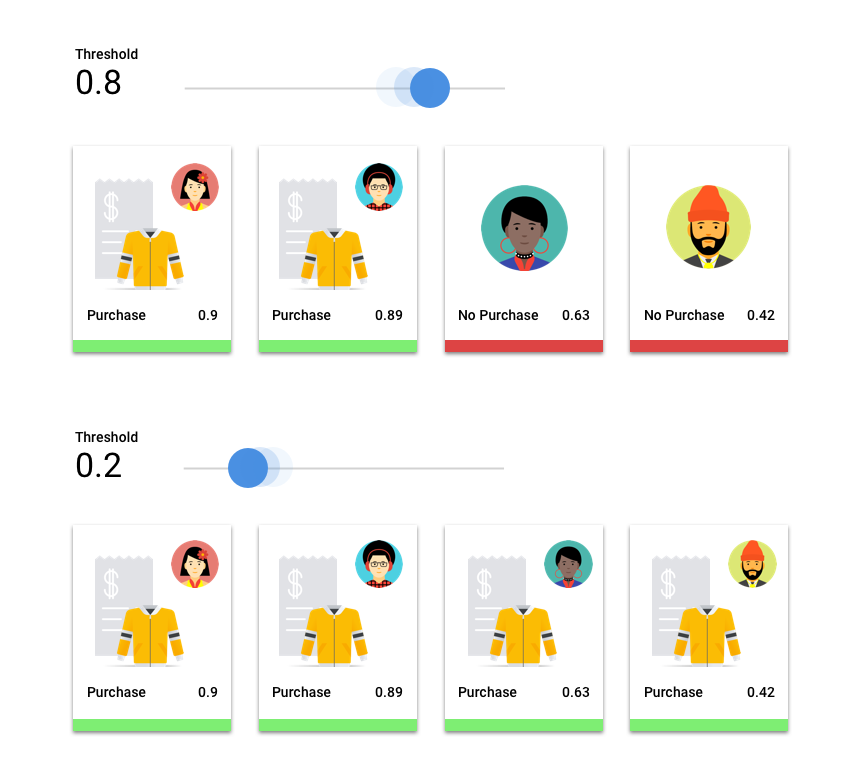
If your score threshold is low, your model will run the risk of misclassification. For that reason, the score threshold should be based on a given use case.
Prediction outcomes
After applying the score threshold, predictions made by your model will fall into one of four categories. To understand these categories, imagine again a jacket binary classification model. In this example, the positive class (what the model is attempting to predict) is that the customer will purchase a jacket in the next year.
- True positive: The model correctly predicts the positive class. The model correctly predicted that a customer purchased a jacket.
- False positive: The model incorrectly predicts the positive class. The model predicted that a customer purchased a jacket, but they didn't.
- True negative: The model correctly predicts the negative class. The model correctly predicted that a customer didn't purchase a jacket.
- False negative: The model incorrectly predicts a negative class. The model predicted that a customer didn't purchase a jacket, but they did.

Precision and recall
Precision and recall metrics help you understand how well your model is capturing information and what it's leaving out. Learn more about precision and recall.
- Precision is the fraction of the positive predictions that were correct. Of all the predictions of a customer purchase, what fraction were actual purchases?
- Recall is the fraction of rows with this label that the model correctly predicted. Of all the customer purchases that could have been identified, what fraction were?
Depending on your use case, you may need to optimize for either precision or recall.
Other classification metrics
AUC PR: The area under the precision-recall (PR) curve. This value ranges from zero to one, where a higher value indicates a higher-quality model.
AUC ROC: The area under the receiver operating characteristic (ROC) curve. This ranges from zero to one, where a higher value indicates a higher-quality model.
Accuracy: The fraction of classification predictions produced by the model that were correct.
Log loss: The cross-entropy between the model predictions and the target values. This ranges from zero to infinity, where a lower value indicates a higher-quality model.
F1 score: The harmonic mean of precision and recall. F1 is a useful metric if you're looking for a balance between precision and recall and there's an uneven class distribution.
Regression metrics
Once your model is built, AutoML Tables provides a variety of standard regression metrics for you to review. There's no perfect answer on how to evaluate your model; evaluation metrics should be considered in context with your problem type and what you want to achieve with your model. Here's an overview of some metrics you'll have available to you.
Mean absolute error (MAE)
MAE is the average absolute difference between the target and predicted values. It measures the average magnitude of the errors--the difference between a target and predicted value--in a set of predictions. And because it uses absolute values, MAE doesn't consider the relationship's direction, nor indicate underperformance or overperformance. When evaluating MAE, a smaller value indicates a higher quality model (0 represents a perfect predictor).
Root mean square error (RMSE)
RMSE is the square root of the average squared difference between the target and predicted values. RMSE is more sensitive to outliers than MAE,so if you're concerned about large errors, then RMSE can be a more useful metric to evaluate. Similar to MAE, a smaller value indicates a higher quality model (0 represents a perfect predictor).
Root mean squared logarithmic error (RMSLE)
RMSLE is RMSE in logarithmic scale. RMSLE is more sensitive to relative errors than absolute ones and cares more about underperformance than overperformance.
Test your model
Evaluating your model metrics is primarily how you can determine whether your model is ready to deploy, but you can also test it with new data. Try uploading new data to see if the model's predictions match your expectations. Based on the evaluation metrics or testing with new data, you may need to continue improving your model's performance. Learn more about troubleshooting your model
Deploy your model and make predictions
 When you're satisfied with your model's performance, it's time to use your
model. Perhaps that means production-scale usage, or maybe it's a one-time
prediction request. Depending on your use case, you can use your model in
different ways.
When you're satisfied with your model's performance, it's time to use your
model. Perhaps that means production-scale usage, or maybe it's a one-time
prediction request. Depending on your use case, you can use your model in
different ways.
Batch prediction
Batch prediction is useful for making many prediction requests at once. Batch prediction is asynchronous, meaning that the model will wait until it processes all of the prediction requests before returning a CSV file or BigQuery Table with prediction values.
Online prediction
Deploy your model to make it available for prediction requests using a REST API. Online prediction is synchronous (real-time), meaning that it will quickly return a prediction, but only accepts one prediction request per API call. Online prediction is useful if your model is part of an application and parts of your system are dependent on a quick prediction turnaround.
To avoid undesired charges, remember to undeploy your model when it's not in use.