Ao otimizar o desempenho de um aplicativo, pense no uso que ele faz do NDB. Por exemplo, se um aplicativo ler um valor que não esteja no cache, essa leitura demorará um pouco. Você pode acelerar seu aplicativo executando ações do Datastore em paralelo com outras coisas ou realizando algumas ações do Datastore em paralelo umas com as outras.
A biblioteca de cliente do NDB fornece muitas funções assíncronas ("async").
Cada uma delas permite que um aplicativo envie uma solicitação ao Datastore. A função retorna
imediatamente com um
objeto
Future. O aplicativo pode fazer outras coisas enquanto o Datastore gerencia
a solicitação.
Depois que o Datastore gerencia a solicitação, o aplicativo pode receber os resultados
do objeto Future.
Introdução
Suponha que um dos gerenciadores de solicitação do seu aplicativo precise usar o NDB para gravar algo ou para registrar a solicitação. Ele também precisa executar algumas outras operações do NDB, talvez para buscar alguns dados.
Ao substituir a chamada para put() por uma chamada para o
equivalente assíncrono put_async(), o aplicativo
pode fazer outras tarefas imediatamente, em vez de ficar bloqueado em put().
Isso permite que as outras funções do NDB e a renderização de modelos ocorram enquanto o Datastore grava os dados. O Datastore não fica bloqueado pelo aplicativo até que este receba os dados dele.
Neste exemplo, não é conveniente chamar future.get_result:
o aplicativo nunca usa o resultado do NDB. Esse código serve
apenas para garantir que o gerenciador de solicitações não seja encerrado antes
que o NDB put seja concluído. Se o gerenciador de solicitações for encerrado muito cedo,
talvez o "put" não aconteça. Por questões de conveniência, decore o gerenciador
de solicitações com @ndb.toplevel. Isso faz com que o gerenciador não seja encerrado até que as solicitações assíncronas tenham sido concluídas. Por outro lado, permite que você envie a solicitação e não se preocupe com o resultado.
É possível especificar um WSGIApplication inteiro como
ndb.toplevel. Isso faz com que cada um dos gerenciadores do
WSGIApplication aguarde todas as solicitações
assíncronas antes de retornar.
Ele não aplica a categoria "toplevel" a todos os gerenciadores do WSGIApplication.
Usar um aplicativo toplevel é mais conveniente do que
todas as funções de gerenciador dele. Porém, se um método de gerenciador usar yield,
esse método ainda precisará ser unido a outro decorador,
@ndb.synctasklet. Caso contrário, ele deixará de ser executado em
yield e não será concluído.
Como usar as APIs assíncronas e os Futures
Quase todas as funções síncronas do NDB têm uma contraparte _async. Por
exemplo, put() tem put_async().
Os argumentos da função assíncrona são sempre os mesmos da versão síncrona.
O valor de retorno de um método assíncrono é sempre
Future ou, nas funções "multi", uma lista de
Futures.
Um Future é um objeto que mantém o estado de uma operação
que foi iniciada, mas que ainda não foi concluída. Todas as APIs assíncronas
retornam um ou mais Futures.
É possível chamar a função get_result() de Future
para solicitar o resultado da operação.
Em seguida, o Future fica bloqueado, se necessário, até que o resultado seja disponibilizado.
Depois disso, entrega o resultado a você.
get_result() retorna o valor que seria retornado
pela versão síncrona da API.
Observação: se você já usou Futures em outras linguagens de programação, pode pensar que é possível usar um Future diretamente como resultado. Isso não funciona neste caso.
Essas linguagens usam
futures implícitos. O NDB usa futures explícitos.
Chame get_result() para receber o resultado Future
de um NDB.
E se a operação gerar uma exceção? Isso depende de quando a exceção ocorre. Se o NDB perceber um problema ao fazer uma solicitação
(talvez um argumento do tipo incorreto), o método _async()
gerará uma exceção. No entanto, se a exceção for detectada pelo
servidor do Datastore, o método _async() retornará um
Future, e a exceção será gerada quando o aplicativo
chamar o get_result() dele. Não se preocupe muito com isso, tudo acaba se comportando de maneira bastante natural. Talvez a maior diferença seja que, se um rastreio for impresso, você verá algumas partes expostas do maquinário assíncrono de baixo nível.
Por exemplo, digamos que você esteja desenvolvendo um aplicativo de livro de visitas. Se o usuário tiver feito login, você quer apresentar uma página mostrando as postagens mais recentes do livro de visitas. Essa página também deve mostrar ao usuário o apelido dele. O aplicativo precisa de dois tipos de informações: as informações da conta do usuário que fez login e o conteúdo das postagens do livro de visitas. A versão "síncrona" desse aplicativo pode ser semelhante a:
Aqui há duas ações independentes de E/S: receber a entidade
Account e buscar entidades Guestbook
recentes. Usando a API síncrona, isso acontece sequencialmente. Esperamos receber as informações da conta antes de buscar as entidades do livro de visitas. Mas o aplicativo não precisa das informações da conta imediatamente. Podemos aproveitar isso e usar APIs assíncronas:
Primeiro, essa versão do código cria dois Futures
(acct_future e recent_entries_future),
e depois os aguarda. O servidor funciona nas duas solicitações em paralelo.
Cada chamada de função _async() cria um objeto Future
e envia uma solicitação ao servidor do Datastore. O servidor pode começar a trabalhar na solicitação imediatamente. As respostas do servidor podem voltar em qualquer ordem arbitrária. O link do objeto Future responde às próprias solicitações correspondentes.
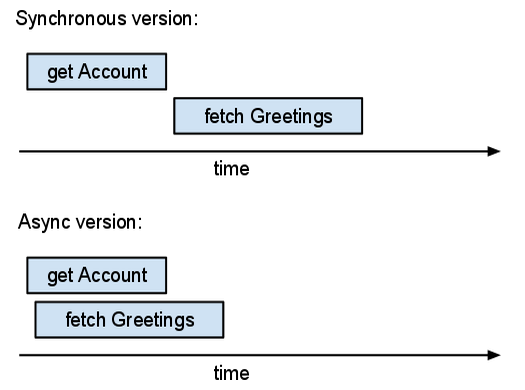
O tempo total (real) gasto na versão assíncrona é aproximadamente igual ao tempo máximo entre as operações. O tempo total gasto na versão síncrona excede à soma dos tempos de operação. Se você puder executar mais operações em paralelo, as operações assíncronas ajudarão mais.
Para ver quanto tempo as consultas do aplicativo demoram ou quantas operações de E/S ele realiza por solicitação, avalie a possibilidade de usar o Appstats. Essa ferramenta pode mostrar gráficos semelhantes ao desenho acima, com base na instrumentação de um aplicativo ativo.
Como usar os tasklets
Um tasklet do NDB é um trecho de código que pode ser executado simultaneamente com outro código. Se você gravar um tasklet, o aplicativo poderá usá-lo da mesma forma
que usa uma função NDB assíncrona. Primeiro, ele chama o tasklet, que retorna um
Future. Depois, chamar o método get_result()
do Future acessa o resultado.
Tasklets são uma maneira de gravar funções simultâneas sem linhas de execução. Eles são executados por um loop de eventos e podem se suspender bloqueando para E/S ou alguma outra operação usando uma instrução "yield". A noção de uma operação de bloqueio é abstraída na classe
Future,
mas um tasklet também pode produzir (yield) uma
RPC para aguardar a conclusão dessa RPC.
Quando o tasklet tem um resultado, ele gera (raise) uma
exceção ndb.Return. Em seguida, o NDB associa o resultado
ao Future produzido (yield) anteriormente.
Ao gravar um tasklet do NDB, você usa yield e
raise de maneira incomum. Portanto, se você procurar exemplos de como usá-los, provavelmente não encontrará um código como um tasklet do NDB.
Para transformar uma função em um tasklet do NDB:
- decore a função com
@ndb.tasklet; - substitua todas as chamadas de armazenamento de dados síncrono por
yields de chamadas de armazenamento de dados assíncrono; - faça a função "retornar" o valor de retorno com
raise ndb.Return(retval)(não será necessário se a função não retornar nada).
Um aplicativo pode usar tasklets para controlar melhor as APIs assíncronas. Por exemplo, pense no seguinte esquema:
...
Ao exibir uma mensagem, faz sentido mostrar o apelido do autor. A maneira "síncrona" de buscar os dados para mostrar uma lista de mensagens pode ter esta aparência:
Infelizmente, essa abordagem é ineficiente. Se você olhar para ela no Appstats, verá que as solicitações "Get" estão em série. Você pode ver o seguinte padrão "escada".
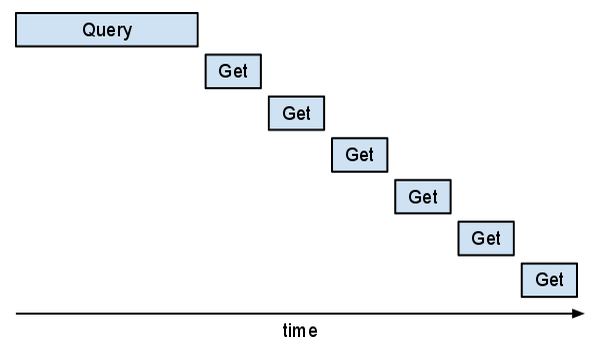
Essa parte do programa será mais rápida se for possível sobrepor esses "Gets".
Você pode reescrever o código para usar get_async, mas é
complicado controlar quais solicitações assíncronas e mensagens são correspondentes.
O aplicativo pode definir sua própria função "assíncrona", tornando-a um tasklet. Isso permite organizar o código de maneira menos confusa.
Além disso, em vez de usar
acct = key.get() ou
acct = key.get_async().get_result(),
a função precisa usar
acct = yield key.get_async().
Esse yield informa ao NDB que é um bom momento para suspender esse
tasklet e permitir que outros sejam executados.
Decorar uma função de gerador com @ndb.tasklet
faz com que a função retorne um Future em vez de um
objeto gerador. Dentro do tasklet, qualquer yield de um
Future aguarda e retorna o resultado do Future.
Exemplo:
Embora get_async() retorne um
Future, o framework do tasklet faz com que a expressão yield
retorne o resultado do Future para a variável
acct.
O map() chama callback() várias vezes.
Porém, o yield ..._async() em callback()
permite que o programador do NDB envie muitas solicitações assíncronas antes de aguardar a
conclusão de qualquer uma delas.
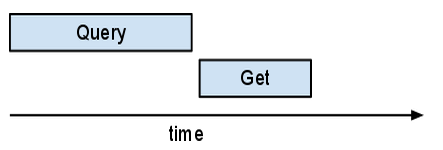
Se você olhar isso no Appstats, poderá se surpreender ao ver que esses vários Gets não se sobrepõem. Todos eles passam pela mesma solicitação. O NDB implementa um "autobatcher". O autobatcher agrupa várias solicitações em uma única RPC em lote para o servidor. Ele faz isso de tal maneira que, desde que haja mais trabalho a fazer (outro callback pode ser executado), ele coletará chaves. Assim que um dos resultados for necessário, o autobatcher enviará a RPC em lote. Ao contrário da maioria das solicitações, as consultas não são "em lote".
Quando um tasklet é executado, ele extrai o namespace padrão do que era o padrão no momento da geração dele ou de qualquer alteração feita nele durante a execução. Em outras palavras, o namespace padrão não está associado ou armazenado no Contexto, e a alteração do namespace padrão em um tasklet não afeta o namespace padrão em outros tasklets, exceto aqueles gerados por ele.
Tasklets, consultas paralelas, rendimento paralelo
Você pode usar tasklets para que várias consultas busquem registros ao mesmo tempo. Por exemplo, suponha que seu aplicativo tenha uma página que exiba o conteúdo de um carrinho de compras e uma lista de ofertas especiais. O esquema pode ser assim:
Uma função "síncrona" que obtém itens e ofertas especiais do carrinho de compras pode se parecer com o seguinte:
Esse exemplo usa consultas para buscar listas de itens e ofertas de carrinho de compras. Em seguida,
busca detalhes sobre os itens de inventário com get_multi().
Essa função não usa o
valor de retorno de get_multi() diretamente. Ela chama
get_multi() para buscar todos os detalhes do inventário no
cache para que possam ser lidos rapidamente mais tarde. O get_multi
combina muitos Gets em uma solicitação. Porém, as buscas de consulta acontecem uma
após a outra. Para fazer essas buscas acontecerem ao mesmo tempo, sobreponha as duas consultas:
A chamada get_multi()
ainda está separada: ela depende dos resultados da consulta, por isso
não é possível combiná-la com as consultas.
Suponha que esse aplicativo às vezes precise do carrinho, às vezes das ofertas e, às vezes, de ambos. Você quer organizar seu código para que haja uma função para apresentar o carrinho e uma função para apresentar as ofertas. Se o aplicativo chamar essas funções juntas, o ideal será que as consultas se "sobreponham". Para fazer isso, crie estes tasklets:
Esse yield x, y é importante,
mas pode passar despercebido com facilidade. Se fossem duas instruções yield
separadas, elas ocorreriam em série. Porém, produzir (yield) uma tupla
de tasklets é uma produção paralela: os tasklets podem ser executados em paralelo
e a produção (yield) aguarda a conclusão de todos eles e retorna
os resultados. Em algumas linguagens de programação, isso é conhecido como
barreira.
Se você transformar um fragmento de código em um tasklet, provavelmente vai querer fazer mais em breve. Se você observar um código "síncrono" que possa ser executado em paralelo com um tasklet, provavelmente é uma boa ideia torná-lo um tasklet também.
Em seguida, paralelize-o com um yield paralelo.
Se você escrever uma função de solicitação, como uma função de solicitação webapp2 ou uma função de visualização do Django, para ser um tasklet, ela não fará o que você quer: ela é gerada, mas depois sua execução é interrompida. Nessa situação, decore a função com
@ndb.synctasklet.
@ndb.synctasklet é como @ndb.tasklet, mas
foi alterado para chamar get_result() no tasklet.
Isso transforma seu tasklet em uma função que retorna seu resultado da maneira usual.
Iteradores de consulta em tasklets
Para iterar resultados de consulta em um tasklet, use o seguinte padrão:
Esse é o equivalente compatível com tasklet do seguinte código:
As três linhas em negrito na primeira versão são o equivalente a um tasklet da linha única em negrito na segunda versão.
Os tasklets só podem ser suspensos em uma palavra-chave yield.
O loop sem yield não permite que outros tasklets sejam executados.
Mas por que esse código usa um iterador de consulta em vez de
buscar todas as entidades usando qry.fetch_async()?
O aplicativo pode ter tantas entidades que não cabem na RAM.
Talvez você esteja procurando uma entidade e interrompa a iteração depois de
encontrá-la, mas não é possível expressar os critérios de pesquisa apenas com a linguagem
de consulta. Você pode usar um iterador a fim de carregar entidades para verificar e, em seguida, sair do loop quando encontrar o que quer.
Urlfetch assíncrono com NDB
Um NDB Context tem uma função assíncrona
urlfetch() que paraleliza bem com tasklets NDB. Por exemplo:
O serviço de busca de URL tem a própria API de solicitação assíncrona. Isso não é um problema, mas nem sempre é fácil usá-la com os tasklets do NDB.
Como usar transações assíncronas
As transações também podem ser feitas de maneira assíncrona. É possível passar uma função
para ndb.transaction_async() ou usar o decorador
@ndb.transactional_async.
Como as outras funções assíncronas, ela retornará um NDB Future:
As transações também funcionam com tasklets. Por exemplo, podemos alterar nosso código
update_counter para yield enquanto aguardamos o bloqueio de
RPCs:
Como usar o Future.wait_any()
Às vezes, você quer fazer várias solicitações assíncronas e retornar sempre que a primeira for concluída.
Para isso, use o método de classe ndb.Future.wait_any():
Infelizmente, não há um modo conveniente de transformar isso em um tasklet.
Um yield paralelo aguarda a conclusão de todos os Futures,
incluindo aqueles que você não quer esperar.