このドキュメントでは、VMware の Google Distributed Cloud(ソフトウェアのみ)でシステム コンポーネントのロギングとモニタリングを構成する方法について説明します。
デフォルトでは、Cloud Logging、Cloud Monitoring、Google Cloud Managed Service for Prometheus が有効になっています。
オプションの詳細については、Logging と Monitoring の概要をご覧ください。
モニタリング対象リソース
モニタリング対象リソースとは、Google がクラスタ、ノード、Pod、コンテナなどのリソースを表す方法です。詳細は、Cloud Monitoring のモニタリング対象リソースタイプのドキュメントをご覧ください。
ログと指標のクエリを行うには、少なくとも次のリソースラベルを理解する必要があります。
project_id: クラスタの logging-monitoring プロジェクトのプロジェクト ID。この値は、クラスタ構成ファイルのstackdriver.projectIDフィールドで指定した値です。location: Cloud Monitoring の指標を転送して保存する Google Cloud リージョン。リージョンは、インストール時にクラスタ構成ファイルのstackdriver.clusterLocationフィールドで指定します。オンプレミス データセンターの近くのリージョンを選択することをおすすめします。Cloud Logging ログを転送および保存するロケーションは、ログルーターの構成で指定します。ログの転送の詳細については、転送とストレージの概要をご覧ください。
cluster_name: クラスタの作成時に選択したクラスタ名。Stackdriver カスタム リソースを調べることで、管理クラスタまたはユーザー クラスタの
cluster_nameの値を取得できます。kubectl get stackdriver stackdriver --namespace kube-system \ --kubeconfig CLUSTER_KUBECONFIG --output yaml | grep 'clusterName:'
ここで
CLUSTER_KUBECONFIGは、クラスタ名が必要な管理クラスタまたはユーザー クラスタの kubeconfig ファイルのパスです。
ログと指標の転送
Stackdriver Log Forwarder(stackdriver-log-forwarder)は、各ノードマシンから Cloud Logging にログを送信します。同様に、GKE 指標エージェント(gke-metrics-agent)は、各ノードマシンから Cloud Monitoring に指標を送信します。ログと指標が送信される前に、Stackdriver Operator(stackdriver-operator)は、stackdriver カスタム リソースの clusterLocation フィールドの値を各ログエントリと指標に関連付けてから Google Cloudに転送します。また、ログと指標は、stackdriver カスタム リソース仕様(spec.projectID)で指定された Google Cloud プロジェクトに関連付けられます。stackdriver リソースは、クラスタの作成時に Cluster リソースの clusterOperations セクションの stackdriver.clusterLocation フィールドと stackdriver.projectID フィールドから clusterLocation フィールドと projectID フィールドの値を取得します。
Stackdriver エージェントによって送信されたすべての指標とログエントリは、グローバル取り込みエンドポイントに転送されます。そこから、データ転送の信頼性を確保するために、最も近い到達可能なリージョン Google Cloud エンドポイントにデータが転送されます。
グローバル エンドポイントが指標またはログエントリを受信した後の処理は、サービスによって異なります。
ログの転送の構成方法: ロギング エンドポイントがログメッセージを受信すると、Cloud Logging はログルーターを介してメッセージを渡します。ログルーター構成のシンクとフィルタによって、メッセージの転送方法が決まります。ログエントリは、ログエントリを保存するリージョン Logging バケットなどの宛先や、Pub/Sub に転送できます。ログの転送の仕組みと構成方法の詳細については、転送とストレージの概要をご覧ください。
この転送プロセスでは、
stackdriverカスタム リソースのclusterLocationフィールドと Cluster 仕様のclusterOperations.locationフィールドは考慮されません。ログの場合、clusterLocationはログエントリのラベル付けにのみ使用されます。これは、ログ エクスプローラでのフィルタリングに役立ちます。指標の転送の構成方法: 指標エンドポイントが指標エントリを受信すると、Cloud Monitoring は指標で指定されたロケーションにエントリを自動的に転送します。指標のロケーションは、
stackdriverカスタム リソースのclusterLocationフィールドから取得されたものです。構成を計画する: Cloud Logging と Cloud Monitoring を構成するときに、ログルーターを構成し、
clusterLocationをニーズに最適なロケーションに指定します。たとえば、ログと指標を同じロケーションに送信する場合は、ログルーターが Google Cloud プロジェクトで使用しているのと同じ Google Cloud リージョンにclusterLocationを設定します。必要に応じて構成を更新する: 災害復旧計画などのビジネス要件により、ログと指標の宛先設定はいつでも変更できます。 Google Cloud のログルーター構成と
stackdriverカスタム リソースのclusterLocationフィールドの変更は、すぐに有効になります。
Cloud Logging の使用
クラスタで Cloud Logging を有効にするための操作は必要ありません。ただし、ログを表示する Google Cloud プロジェクトを指定する必要があります。クラスタ構成ファイルの stackdriver セクションで Google Cloud プロジェクトを指定します。
ログには、 Google Cloud コンソールでログ エクスプローラを使用してアクセスできます。たとえば、コンテナのログにアクセスするには、次のようにします。
- Google Cloud コンソールで、プロジェクトのログ エクスプローラを開きます。
- 次の方法でコンテナのログを表示します。
- 左上のカタログ プルダウン ボックスをクリックし、[Kubernetes コンテナ] を選択します。
- 階層からクラスタ名、Namespace、コンテナの順に選択します。
ブートストラップ クラスタのコントローラのログを表示する
-
Google Cloud コンソールで、[ログ エクスプローラ] ページに移動します。
検索バーを使用してこのページを検索する場合は、小見出しが「Logging」の結果を選択します。
ブートストラップ クラスタのコントローラのログをすべて表示するには、クエリエディタで次のクエリを実行します。
"ADMIN_CLUSTER_NAME" resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster"
特定の Pod のログを表示するには、その Pod の名前を含むようにクエリを編集します。
resource.type="k8s_container" resource.labels.cluster_name="gkectl-bootstrap-cluster" resource.labels.pod_name="POD_NAME"
Cloud Monitoring の使用
クラスタで Cloud Monitoring を有効にするための操作は必要ありません。ただし、指標を表示する Google Cloud プロジェクトを指定する必要があります。クラスタ構成ファイルの stackdriver セクションで Google Cloud プロジェクトを指定します。
Metrics Explorer では 1,500 以上の指標を選択できます。Metrics Explorer にアクセスするには、次のようにします。
Google Cloud コンソールで、[Monitoring] を選択するか、次のボタンを使用します。
[リソース] > [Metrics Explorer] を選択します。
Google Cloud コンソールのダッシュボードで指標を表示することもできます。ダッシュボードの作成と指標の表示については、ダッシュボードの作成をご覧ください。
フリートレベルのモニタリング データを表示する
Cloud Monitoring データ(Google Distributed Cloud クラスタを含む)を使用してフリート全体のリソースの使用状況を表示するには、 Google Cloud コンソールで Google Kubernetes Engine の概要を使用します。詳細については、 Google Cloud コンソールからクラスタを管理するをご覧ください。
デフォルトの Cloud Monitoring 割り当て上限
Google Distributed Cloud モニタリングには、プロジェクトごとに 1 分あたり 6,000 回の API 呼び出しというデフォルトの上限が設定されています。この上限を超えると、指標が表示されない場合があります。モニタリングの上限を引き上げる必要がある場合は、 Google Cloud コンソールからリクエストしてください。
Managed Service for Prometheus の使用
Google Cloud Managed Service for Prometheus は Cloud Monitoring の一部であり、デフォルトで使用できます。Managed Service for Prometheus のメリットは次のとおりです。
アラートや Grafana ダッシュボードを変更することなく、既存の Prometheus ベースのモニタリングを引き続き使用できます。
GKE と Google Distributed Cloud の両方を使用する場合、すべてのクラスタの指標に同じ PromQL を使用できます。 Google Cloud コンソールの Metrics Explorer で、[PROMQL] タブを使用することもできます。
Managed Service for Prometheus を有効および無効にする
Google Distributed Cloud リリース 1.30.0-gke.1930 以降では、Managed Service for Prometheus は常に有効になっています。それより前のバージョンでは、Stackdriver リソース stackdriver を編集して、Managed Service for Prometheus を有効または無効にできます。1.30.0-gke.1930 より前のクラスタ バージョンで Managed Service for Prometheus を無効にするには、stackdriver リソースの spec.featureGates.enableGMPForSystemMetrics を false に設定します。
指標データを表示する
Managed Service for Prometheus が有効になっている場合、次のコンポーネントの指標は、Cloud Monitoring で保存と照会を行う形式が異なります。
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet と cadvisor
- kube-state-metrics
- node-exporter
新しい形式では、Prometheus Query Language(PromQL)を使用して、前述の指標をクエリできます。
次に PromQL の例を示します。
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
Managed Service for Prometheus を使用した Grafana ダッシュボードの構成
Managed Service for Prometheus の指標データで Grafana を使用するには、Grafana を使用したクエリの手順に沿って、Managed Service for Prometheus のデータをクエリするように Grafana データソースを認証および構成します。
サンプルの Grafana ダッシュボードは、GitHub の anthos-samples リポジトリで提供されています。サンプル ダッシュボードをインストールする手順は次のとおりです。
サンプルの
.jsonファイルをダウンロードします。git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Grafana データソースを
Managed Service for Prometheusと異なる名前で作成している場合は、すべての.jsonファイルのdatasourceフィールドを変更します。sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
[DATASOURCE_NAME] は、Prometheus
frontendサービスを指す Grafana のデータソースの名前に置き換えます。ブラウザから Grafana UI にアクセスし、[Dashboards] メニューの [+ Import] を選択します。
.jsonファイルをアップロードするか、ファイルの内容をコピーして貼り付けて、[読み込む] を選択します。ファイルの内容が正常に読み込まれたら、[インポートする] を選択します。必要に応じて、インポートする前にダッシュボード名と UID を変更することもできます。
Google Distributed Cloud とデータソースが正しく構成されていれば、インポートされたダッシュボードは正常に読み込まれます。たとえば、次のスクリーンショットでは、
cluster-capacity.jsonによって構成されたダッシュボードを示します。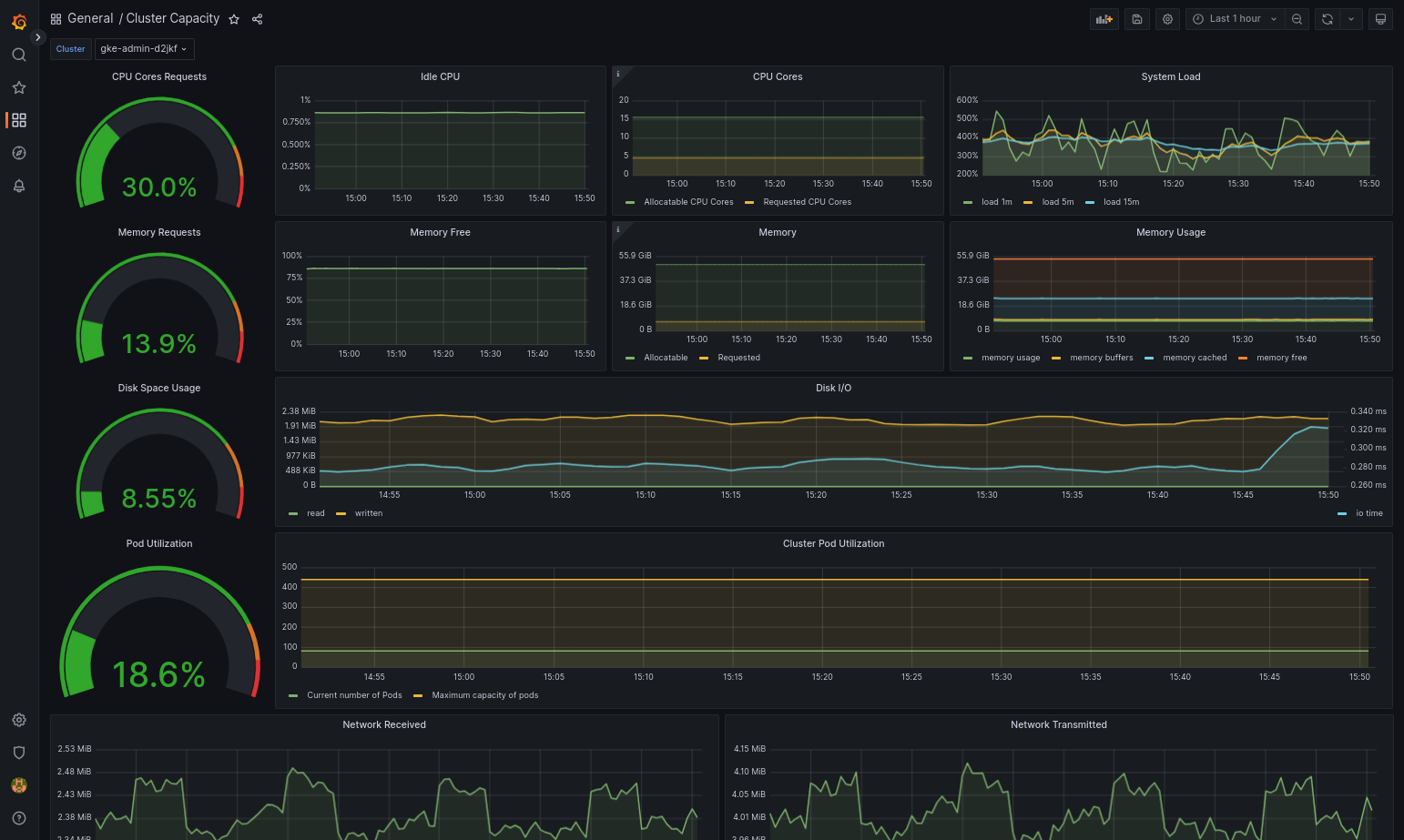
参考情報
Managed Service for Prometheus の詳細については、以下をご覧ください。
Prometheus と Grafana の使用
バージョン 1.16 以降では、新しく作成されたクラスタで Prometheus と Grafana を使用できません。クラスタ内モニタリングの代わりに、Managed Service for Prometheus を使用することをおすすめします。
Prometheus と Grafana が有効になっている 1.15 クラスタを 1.16 にアップグレードした場合、Prometheus と Grafana は引き続き動作しますが、更新されることや、セキュリティ パッチが提供されることはありません。
1.16 にアップグレードした後に Prometheus リソースと Grafana リソースをすべて削除する場合は、次のコマンドを実行します。
kubectl --kubeconfig KUBECONFIG delete -n kube-system \
statefulsets,services,configmaps,secrets,serviceaccounts,clusterroles,clusterrolebindings,certificates,deployments \
-l addons.gke.io/legacy-pg=true
以前のバージョンの Google Distributed Cloud に含まれる Prometheus コンポーネントと Grafana コンポーネントを使用する代わりに、Prometheus と Grafana のオープンソース コミュニティ バージョンに切り替えることもできます。
既知の問題
ユーザー クラスタでは、アップグレード中に Prometheus と Grafana は自動的に無効になります。ただし、構成データと指標データは失われません。
この問題を回避するには、アップグレード後に monitoring-sample を編集用に開いて enablePrometheus を true に設定します。
Grafana ダッシュボードからモニタリング指標にアクセスする
Grafana は、クラスタから収集された指標を表示します。これらの指標を表示するには、次の手順で Grafana のダッシュボードにアクセスする必要があります。
ユーザー クラスタの
kube-systemNamespace で実行されている Grafana Pod の名前を取得します。kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system get pods
[USER_CLUSTER_KUBECONFIG] は、ユーザー クラスタの kubeconfig ファイルです。
Grafana Pod には、TCP localhost ポート 3000 をリッスンする HTTP サーバーがあります。ローカルポートを Pod のポート 3000 に転送すると、ウェブブラウザで Grafana のダッシュボードを表示できます。
たとえば、Pod の名前が
grafana-0であるとします。ポート 50000 を Pod のポート 3000 に転送するには、次のコマンドを入力します。kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system port-forward grafana-0 50000:3000
ウェブブラウザで
http://localhost:50000に移動します。ログインページで、ユーザー名とパスに「
admin」と入力します。ログインに成功すると、パスワードを変更するように求められます。デフォルトのパスワードを変更すると、ユーザー クラスタの Grafana ホーム ダッシュボードが読み込まれます。
他のダッシュボードにアクセスするには、ページの左上にあるホーム プルダウン メニューをクリックします。
Grafana の使用例については、Grafana ダッシュボードを作成するをご覧ください。
アラートにアクセスする
Prometheus Alertmanager は、Prometheus サーバーからアラートを収集します。これらのアラートは Grafana ダッシュボードに表示できます。アラートを表示するには、次の手順でダッシュボードにアクセスする必要があります。
alertmanager-0Pod のコンテナは、TCP ポート 9093 をリッスンします。ローカルポートを Pod のポート 9093 に転送します。kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward \ -n kube-system alertmanager-0 50001:9093
ウェブブラウザで
http://localhost:50001に移動します。
Prometheus Alertmanager の構成を変更する
ユーザー クラスタの monitoring.yaml ファイルを編集して、Prometheus Alertmanager のデフォルト構成を変更できます。これは、アラートをダッシュボードに保存するのではなく、特定の宛先に転送したい場合に行います。Prometheus で AlertManager を構成する方法については、構成ドキュメントをご覧ください。
Alertmanagerager の構成を変更するには、次の手順を行います。
ユーザー クラスタの
monitoring.yamlマニフェスト ファイルのコピーを作成します。kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system \ get monitoring monitoring-sample -o yaml > monitoring.yaml
Alertmanager を構成するには、
spec.alertmanager.ymlのフィールドを変更します。完了したら、変更したマニフェストを保存します。マニフェストをクラスタに適用します。
kubectl apply --kubeconfig [USER_CLUSTER_KUBECONIFG] -f monitoring.yaml
Grafana ダッシュボードを作成する
これまでの手順で、指標を公開するアプリケーションをデプロイし、指標が公開されて Prometheus により取得されていることを確認しました。次は、アプリケーション レベルの指標をカスタムの Grafana ダッシュボードに追加します。
Gradfana ダッシュボードを作成するには、次の手順を行います。
- 必要に応じて、Grafana にアクセスします。
- Home Dashboard で、ページの左上隅にあるホーム プルダウン メニューをクリックします。
- 右側のメニューで [New dashboard] をクリックします。
- [New panel] セクションで [Graph] をクリックします。空のグラフ ダッシュボードが表示されます。
- [Panel title] をクリックし、[Edit] をクリックします。下部の [Graph] パネルの [Metrics] タブが開きます。
- [Data Source] プルダウン メニューから [user] を選択します。[Add query] をクリックし、検索フィールドに
fooと入力します。 - 画面右上の [Back to dashboard] ボタンをクリックします。ダッシュボードが表示されます。
- ダッシュボードを保存するには、画面右上の [Save dashboard] をクリックします。ダッシュボードの名前を選択して、[Save] をクリックします。
Prometheus と Grafana の無効化
バージョン 1.16 以降、Prometheus と Grafana は、monitoring-sample オブジェクトの enablePrometheus フィールドで制御されなくなりました。詳しくは、Prometheus と Grafana の使用をご覧ください。
例: アプリケーション レベルの指標の Grafana ダッシュボードへの追加
以下では、アプリケーションの指標を追加する方法について説明します。このセクションでは、次のタスクを行います。
fooという指標を公開するサンプル アプリケーションをデプロイします。- Prometheus が指標を公開、取得していることを確認します。
- カスタム Grafana ダッシュボードを作成します。
サンプル アプリケーションをデプロイする
サンプル アプリケーションは 1 つの Pod で実行します。Pod のコンテナは定数値 40 で指標 foo を公開します。
次の Pod マニフェスト pro-pod.yaml を作成します。
apiVersion: v1
kind: Pod
metadata:
name: prometheus-example
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '8080'
prometheus.io/path: '/metrics'
spec:
containers:
- image: registry.k8s.io/prometheus-dummy-exporter:v0.1.0
name: prometheus-example
command:
- /bin/sh
- -c
- ./prometheus_dummy_exporter --metric-name=foo --metric-value=40 --port=8080
続いて、この Pod マニフェストをユーザー クラスタに適用します。
kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] apply -f pro-pod.yaml
指標が公開、取得されていることを確認する
prometheus-examplePod のコンテナは、TCP ポート 8080 をリッスンします。ローカルポートを Pod のポート 8080 に転送します。kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-example 50002:8080
アプリケーションが指標を公開していることを確認するには、次のコマンドを実行します。
curl localhost:50002/metrics | grep fooこのコマンドは、次の出力を返します。
# HELP foo Custom metric # TYPE foo gauge foo 40
prometheus-0Pod のコンテナは、TCP ポート 9090 をリッスンします。ローカルポートを Pod のポート 9090 に転送します。kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-0 50003:9090
Prometheus が指標をスクレイピングしていることを確認するには、http://localhost:50003/targets に移動します。これにより、
prometheus-io-podsターゲット グループのprometheus-0Pod にアクセスできます。Prometheus で指標を表示するには、http://localhost:50003/graph に移動します。検索フィールドに「
foo」と入力し、[Execute] をクリックします。ページに指標が表示されます。
Stackdriver カスタム リソースの構成
クラスタを作成すると、Google Distributed Cloud が Stackdriver カスタム リソースを自動的に作成します。カスタム リソースの仕様を編集して、Stackdriver コンポーネントの CPU リクエストとメモリ リクエストのデフォルト値と上限をオーバーライドできます。また、デフォルトのストレージ サイズとストレージ クラスを個別にオーバーライドすることもできます。
CPU とメモリのリクエストと上限のデフォルト値をオーバーライドする
これらのデフォルトをオーバーライドする手順は次のとおりです。
コマンドライン エディタで Stackdriver カスタム リソースを開きます。
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
ここで、KUBECONFIG はクラスタの kubeconfig ファイルのパスです。これは、管理クラスタまたはユーザー クラスタのいずれかです。
Stackdriver カスタム リソースで、
specセクションの下にresourceAttrOverrideフィールドを追加します。resourceAttrOverride: POD_NAME_WITHOUT_RANDOM_SUFFIX/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYresourceAttrOverrideフィールドは、指定したコンポーネントの既存のデフォルトの制限とリクエストをすべてオーバーライドします。次のコンポーネントは、resourceAttrOverrideによってサポートされています。- gke-metrics-agent/gke-metrics-agent
- stackdriver-log-forwarder/stackdriver-log-forwarder
- stackdriver-metadata-agent-cluster-level/metadata-agent
- node-exporter/node-exporter
- kube-state-metrics/kube-state-metrics
サンプル ファイルは次のようになります。
apiVersion: addons.gke.io/v1alpha1
kind: Stackdriver
metadata:
name: stackdriver
namespace: kube-system
spec:
projectID: my-project
clusterName: my-cluster
clusterLocation: us-west-1a
resourceAttrOverride:
gke-metrics-agent/gke-metrics-agent:
requests:
cpu: 110m
memory: 240Mi
limits:
cpu: 200m
memory: 4.5Gi変更を保存してコマンドライン エディタを終了します。
Pod のヘルスチェックを行います。
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep gke-metrics-agent
たとえば、正常な Pod では次のようになります。
gke-metrics-agent-4th8r 1/1 Running 0 5d19h
コンポーネントの Pod 仕様を確認して、リソースが正しく設定されていることを確認します。
kubectl --kubeconfig=KUBECONFIG -n kube-system describe pod POD_NAME
POD_NAMEは、先ほど変更した Pod の名前です。例:stackdriver-prometheus-k8s-0レスポンスは次のようになります。
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
ストレージ サイズのデフォルトをオーバーライドする
これらのデフォルトをオーバーライドする手順は次のとおりです。
コマンドライン エディタで Stackdriver カスタム リソースを開きます。
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
specセクションの下にstorageSizeOverrideフィールドを追加します。コンポーネントstackdriver-prometheus-k8sまたはstackdriver-prometheus-appを使用できます。このセクションの形式は次のとおりです。storageSizeOverride: STATEFULSET_NAME: SIZE
この例では、statefulset
stackdriver-prometheus-k8sとサイズ120Giを使用します。apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a storageSizeOverride: stackdriver-prometheus-k8s: 120Gi保存してコマンドライン エディタを終了します。
Pod のヘルスチェックを行います。
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
stackdriver-prometheus-k8s-0 2/2 Running 0 5d19h
コンポーネントの Pod 仕様を確認して、ストレージ サイズが正しくオーバーライドされていることを確認します。
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
レスポンスは次のようになります。
Volume Claims: Name: my-statefulset-persistent-volume-claim StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
ストレージ クラスのデフォルトをオーバーライドする
要件
まず、使用する StorageClass を作成する必要があります。
ロギングとモニタリングのコンポーネントによって要求される永続ボリュームのデフォルトのストレージ クラスをオーバーライドするには、次のようにします。
コマンドライン エディタで Stackdriver カスタム リソースを開きます。
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
ここで、KUBECONFIG はクラスタの kubeconfig ファイルのパスです。これは、管理クラスタまたはユーザー クラスタのいずれかです。
specセクションの下にstorageClassNameフィールドを追加します。storageClassName: STORAGECLASS_NAME
storageClassNameフィールドは、既存のデフォルトのストレージ クラスをオーバーライドし、要求される永続ボリュームですべてのロギングとモニタリングのコンポーネントに適用されます。サンプル ファイルは次のようになります。apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: true storageClassName: my-storage-class 変更を保存します。
Pod のヘルスチェックを行います。
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
たとえば、正常な Pod では次のようになります。
stackdriver-prometheus-k8s-0 1/1 Running 0 5d19h
コンポーネントの Pod 仕様を確認して、ストレージ クラスが正しく設定されていることを確認します。
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
たとえば、ステートフル セット
stackdriver-prometheus-k8sを使用すると、レスポンスは次のようになります。Volume Claims: Name: stackdriver-prometheus-data StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
最適化された指標を無効にする
デフォルトでは、クラスタで実行される指標エージェントは、コンテナ、kubelet、kube-state-metrics の最適化された一連の指標を収集して Stackdriver に報告します。追加の指標が必要な場合は、Google Distributed Cloud の指標のリストから代替指標を見つけることをおすすめします。
使用可能な代替措置の例を以下に示します。
| 無効な指標 | 代替措置 |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
最適化された kube-state-metrics 指標のデフォルト設定を無効にする(非推奨)には、次の手順を行います。
コマンドライン エディタで Stackdriver カスタム リソースを開きます。
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
ここで、KUBECONFIG はクラスタの kubeconfig ファイルのパスです。これは、管理クラスタまたはユーザー クラスタのいずれかです。
optimizedMetricsフィールドをfalseに設定します。apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: false storageClassName: my-storage-class 変更を保存してコマンドライン エディタを終了します。
既知の問題: Cloud Monitoring のエラー条件
(問題 ID 159761921)
特定の条件下で、新しい各クラスタにデフォルトでデプロイされたデフォルトの Cloud Monitoring Pod が応答しなくなる場合があります。たとえば、クラスタがアップグレードされた場合に、statefulset/prometheus-stackdriver-k8s 内の Pod が再起動されると、ストレージ データが破損する可能性があります。
具体的には、破損したデータによって、prometheus-stackdriver-sidecar がクラスタ ストレージ PersistentVolume に書き込むことができない場合、モニタリングを行っている Pod stackdriver-prometheus-k8s-0 がループ状態になる可能性があります。
エラーを手動で診断して復旧する手順は次のとおりです。
Cloud Monitoring の障害の診断
モニタリングを行っている Pod に障害が発生すると、次のログが報告されます。
{"log":"level=warn ts=2020-04-08T22:15:44.557Z caller=queue_manager.go:534 component=queue_manager msg=\"Unrecoverable error sending samples to remote storage\" err=\"rpc error: code = InvalidArgument desc = One or more TimeSeries could not be written: One or more points were written more frequently than the maximum sampling period configured for the metric.: timeSeries[0-114]; Unknown metric: kubernetes.io/anthos/scheduler_pending_pods: timeSeries[196-198]\"\n","stream":"stderr","time":"2020-04-08T22:15:44.558246866Z"}
{"log":"level=info ts=2020-04-08T22:15:44.656Z caller=queue_manager.go:229 component=queue_manager msg=\"Remote storage stopped.\"\n","stream":"stderr","time":"2020-04-08T22:15:44.656798666Z"}
{"log":"level=error ts=2020-04-08T22:15:44.663Z caller=main.go:603 err=\"corruption after 29032448 bytes: unexpected non-zero byte in padded page\"\n","stream":"stderr","time":"2020-04-08T22:15:44.663707748Z"}
{"log":"level=info ts=2020-04-08T22:15:44.663Z caller=main.go:605 msg=\"See you next time!\"\n","stream":"stderr","time":"2020-04-08T22:15:44.664000941Z"}
Cloud Monitoring のエラーからの復旧
Cloud Monitoring を手動で復旧するには:
クラスタのモニタリングを停止します。モニタリングの調整を防ぐため、
stackdriverOperator をスケールダウンします。kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas 0
モニタリング パイプライン ワークロードを削除します。
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete statefulset stackdriver-prometheus-k8s
モニタリング パイプラインの PersistentVolumeClaim(PVC)を削除します。
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete pvc -l app=stackdriver-prometheus-k8s
クラスタ モニタリングを再開します。Stackdriver Operator をスケールアップして、新しいモニタリング パイプラインを再インストールし、調整を再開します。
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas=1