Nesta página, explicamos como usar o Cloud Logging e o Cloud Monitoring, além do Prometheus e do Grafana para a geração de registros e o monitoramento da sua implementação de clusters do Anthos no VMware (GKE On-Prem). Para um resumo das opções de configuração disponíveis, consulte Visão geral de geração de registros e monitoramento.
Como usar o Cloud Logging e o Cloud Monitoring
As seções a seguir explicam como usar o Logging e o Monitoring com clusters do Anthos em clusters do VMware (GKE On-Prem).
Recursos monitorados
Os recursos monitorados são a forma como o Google representa recursos, como clusters, nós, pods e contêineres. Para saber mais, consulte a documentação dos tipos de recursos monitorados do Cloud Monitoring.
Para consultar registros e métricas, você precisa conhecer pelo menos estes rótulos de recursos:
project_id: ID do projeto do projeto logging-monitoring do ID do cluster. Você forneceu esse valor no campostackdriver.projectIDdo arquivo de configuração do cluster.location: uma região do Google Cloud em que você quer armazenar registros do Cloud Logging e métricas do Cloud Monitoring. É recomendável escolher uma região próxima ao seu data center local. Você forneceu esse valor durante a instalação no campostackdriver.clusterLocationdo arquivo de configuração do cluster.cluster_name: nome que você escolheu quando criou o cluster.É possível recuperar o valor
cluster_namedo cluster de administrador ou de usuário inspecionando o recurso personalizado do Stackdriver:kubectl -n kube-system get stackdrivers stackdriver -o yaml | grep 'clusterName:'
Como acessar dados de registro
É possível acessar registros usando o Explorador de registros no console do Google Cloud. Por exemplo, para acessar os registros de um contêiner:
- Abra o Visualizador de registros do seu projeto no console do Google Cloud.
- Encontre registros de um contêiner da seguinte maneira:
- Clique na caixa suspensa do catálogo de registros no canto superior esquerdo e selecione Contêiner do Kubernetes.
- Selecione o nome do cluster, o namespace e um contêiner da hierarquia.
Como criar painéis para monitorar a integridade do cluster
Por padrão, os clusters do Anthos nos clusters do VMware são configurados para monitorar as métricas do sistema e do contêiner. Depois de criar um cluster (administrador ou usuário), uma prática recomendada é criar os seguintes painéis com o Cloud Monitoring para permitir que a equipe de operações dos clusters do Anthos no VMware monitorem a integridade do cluster:
- Painel de status do plano de controle
- Painel de status do pod
- Painel de status do nó
- Painel de status de integridade da VM
Os painéis serão criados automaticamente durante a instalação do cluster de administrador se o Cloud Monitoring estiver ativado.
Nesta seção, você verá como criar esses painéis. Para mais informações sobre o processo de criação de painéis descrito nas seções a seguir, consulte Como gerenciar painéis por API.
Pré-requisitos
Sua Conta do Google precisa ter as seguintes permissões para criar painéis:
monitoring.dashboards.createmonitoring.dashboards.deletemonitoring.dashboards.update
Você terá essas permissões se sua conta tiver um dos papéis a seguir. É possível verificar suas permissões (no console do Google Cloud):
monitoring.dashboardEditormonitoring.editor- Projeto
editor - Projeto
owner
Além disso, para usar a gcloud (gcloud CLI) para criar painéis, a Conta do Google precisa ter a permissão serviceusage.services.use.
Sua conta terá essa permissão se tiver um dos seguintes papéis:
roles/serviceusage.serviceUsageConsumerroles/serviceusage.serviceUsageAdminroles/ownerroles/editor- Projeto
editor - Projeto
owner
Criar um painel de status do plano de controle
Os clusters do Anthos no plano de controle da VMware consistem no servidor de API, no programador, no gerenciador do controlador e em etcd. Para monitorar o status do plano de controle, crie um painel que monitore o estado desses componentes.
Faça o download da configuração do painel:
control-plane-status.json.Crie um painel personalizado com o arquivo de configuração executando o seguinte comando:
gcloud monitoring dashboards create --config-from-file=control-plane-status.json
No Console do Google Cloud, selecione Monitoring ou use o seguinte botão:
Selecione Recursos > Painéis e veja o painel chamado Status do plano de controle do GKE On-Prem. O status do plano de controle de cada cluster de usuário é coletado de namespaces separados no cluster de administrador. O campo namespace_name é o nome do cluster de usuário.
Um limite de objetivo de nível de serviço (SLO) de 0,999 é definido em cada gráfico.
Como opção, crie políticas de alertas.
Clique para ver um painel de exemplo.

Criar um painel de status do pod
Para criar um painel que inclua a fase de cada pod, além dos tempos de reinicialização e do uso de recursos de cada contêiner, execute as etapas a seguir.
Faça o download da configuração do painel:
pod-status.json.Crie um painel personalizado com o arquivo de configuração executando o seguinte comando:
gcloud monitoring dashboards create --config-from-file=pod-status.json
No Console do Google Cloud, selecione Monitoring ou use o seguinte botão:
Selecione Recursos > Painéis e veja o painel chamado Status do pod do GKE On-Prem.
Como opção, crie políticas de alertas.
Clique para ver um painel de exemplo.
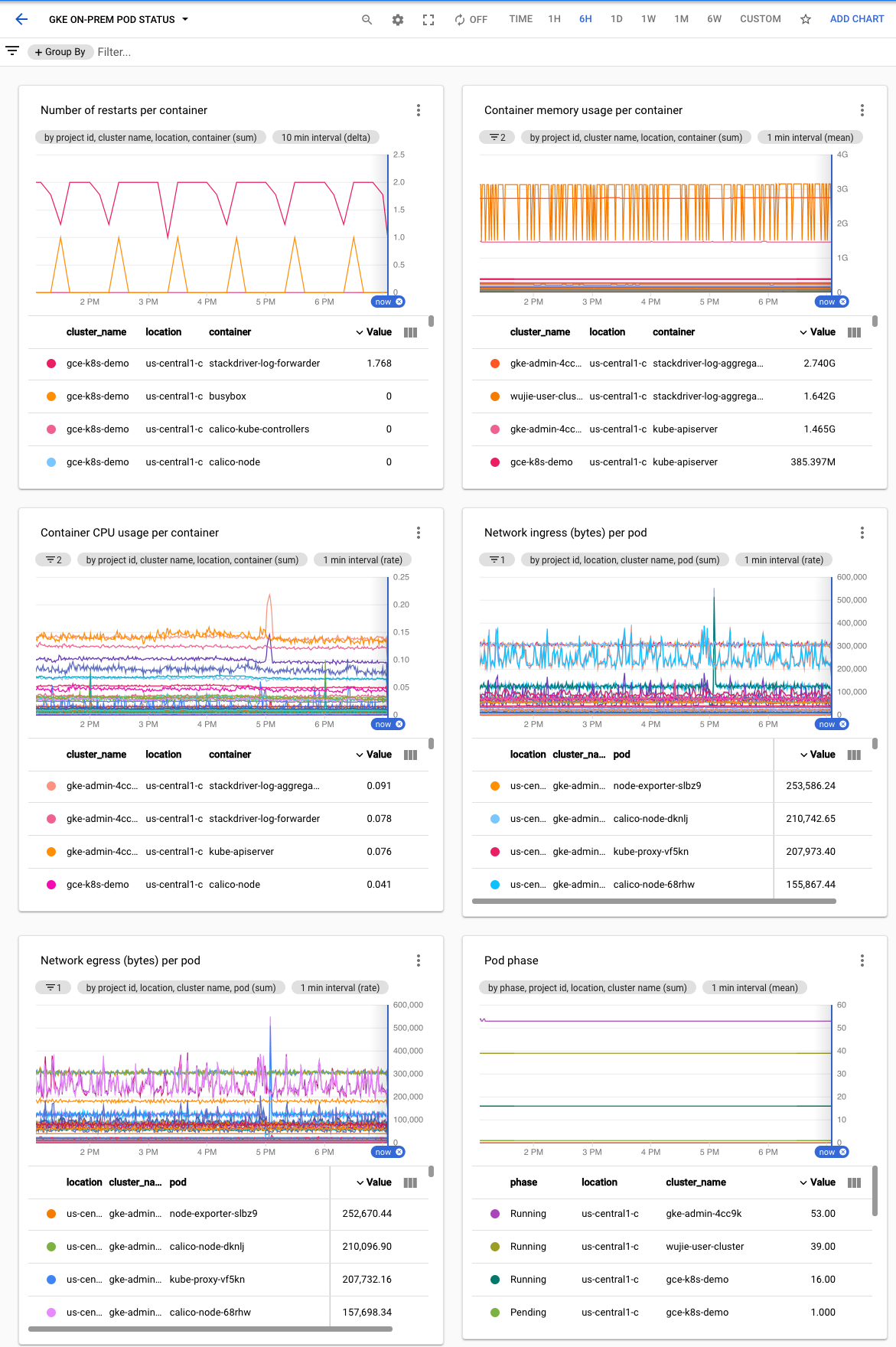
Criar um painel de status do nó
Para criar um painel de status do nó para monitorar a condição do nó, a CPU, a memória e o uso do disco, execute as seguintes etapas:
Faça o download da configuração do painel:
node-status.json.Crie um painel personalizado com o arquivo de configuração executando o seguinte comando:
gcloud monitoring dashboards create --config-from-file=node-status.json
No Console do Google Cloud, selecione Monitoring ou use o seguinte botão:
Selecione Recursos > Painéis e veja o painel chamado Status do nó do GKE On-Prem.
Como opção, crie políticas de alertas.
Clique para ver um painel de exemplo.

Crie um painel de status de integridade da VM
Um painel de status de integridade da VM monitora sinais de contenção de recursos de CPU, memória e disco para VMs no cluster de administrador e em clusters de usuário.
Para criar um painel de status de integridade da VM:
Verifique se
stackdriver.disableVsphereResourceMetricsestá definido como falso. Consulte Arquivo de configuração do cluster do usuário.Faça o download da configuração do painel:
vm-health-status.json.Crie um painel personalizado com o arquivo de configuração executando o seguinte comando:
gcloud monitoring dashboards create --config-from-file=vm-health-status.json
No Console do Google Cloud, selecione Monitoring ou use o seguinte botão:
Selecione Recursos > Painéis e veja o painel chamado Status de integridade da VM do GKE On-Prem.
Como opção, crie políticas de alertas.
Clique para ver um painel de exemplo.

Como configurar recursos do componente Stackdriver
Quando você cria um cluster, o cluster do Anthos no VMware cria automaticamente um recurso personalizado do Stackdriver. É possível editar a especificação no recurso personalizado para substituir os valores padrão das solicitações e limites de CPU e memória de um componente do Stackdriver, além de substituir separadamente o tamanho de armazenamento e a classe de armazenamento padrão.
Substituir valores padrão para solicitações e limites para CPU e memória
Para substituir esses padrões, faça o seguinte:
Abra o recurso personalizado do Stackdriver em um editor de linha de comando:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
KUBECONFIG é o caminho para o arquivo kubeconfig do cluster. Pode ser um cluster de administrador ou um cluster de usuário.
No recurso personalizado do Stackdriver, adicione o campo
resourceAttrOverridena seçãospec:resourceAttrOverride: POD_NAME_WITHOUT_RANDOM_SUFFIX/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYObserve que o campo
resourceAttrOverridesubstitui todos os limites e solicitações padrão existentes do componente que você especificar. Um arquivo de exemplo será parecido com o seguinte:apiVersion: addons.sigs.k8s.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a resourceAttrOverride: stackdriver-prometheus-k8s/prometheus-server: limits: cpu: 500m memory: 3000Mi requests: cpu: 300m memory: 2500MiSalve as alterações e saia do editor da linha de comando.
Verifique a integridade dos pods:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
Por exemplo, um pod íntegro se parece com o seguinte:
stackdriver-prometheus-k8s-0 2/2 Running 0 5d19h
Para verificar a especificação do pod do componente para garantir que os recursos estão configurados corretamente:
kubectl --kubeconfig=KUBECONFIG -n kube-system describe pod POD_NAME
em que
POD_NAMEé o nome do pod que você acabou de alterar. Por exemplo,stackdriver-prometheus-k8s-0A resposta é semelhante a esta:
Name: stackdriver-prometheus-k8s-0 Namespace: kube-system ... Containers: prometheus-server: Limits: cpu: 500m memory: 3000Mi Requests: cpu: 300m memory: 2500Mi ...
Modificar padrões de tamanho do armazenamento
Para substituir esses padrões, faça o seguinte:
Abra o recurso personalizado do Stackdriver em um editor de linha de comando:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
Adicione o campo
storageSizeOverridena seçãospec. É possível usar o componentestackdriver-prometheus-k8soustackdriver-prometheus-app. A seção tem este formato:storageSizeOverride: STATEFULSET_NAME: SIZE
Este exemplo usa o statefulset
stackdriver-prometheus-k8se o tamanho120Gi.apiVersion: addons.sigs.k8s.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a storageSizeOverride: stackdriver-prometheus-k8s: 120GiSalve e saia do editor da linha de comando.
Verifique a integridade dos pods:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
Por exemplo, um pod íntegro se parece com o seguinte:
stackdriver-prometheus-k8s-0 2/2 Running 0 5d19h
Verifique a especificação do pod do componente para garantir que o tamanho do armazenamento seja modificado corretamente.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
A resposta é semelhante a esta:
Volume Claims: Name: my-statefulset-persistent-volume-claim StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
Substituir os padrões da classe de armazenamento
Pré-requisito
Primeiro, é preciso criar um StorageClass que você queira usar.
Para modificar a classe de armazenamento padrão nos volumes permanentes reivindicados pelos componentes do Logging e do Monitoring:
Abra o recurso personalizado do Stackdriver em um editor de linha de comando:
kubectl --kubeconfig=KUBECONFIG -n kube-system edit stackdriver stackdriver
KUBECONFIG é o caminho para o arquivo kubeconfig do cluster. Pode ser um cluster de administrador ou um cluster de usuário.
Adicione o campo
storageClassNameà seçãospec:storageClassName: STORAGECLASS_NAME
O campo
storageClassNamemodifica a classe de armazenamento padrão atual e se aplica a todos os componentes do Logging e do Monitoring com volumes permanentes reivindicados. Um arquivo de exemplo será parecido com o seguinte:apiVersion: addons.sigs.k8s.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a proxyConfigSecretName: my-secret-name enableVPC:
optimizedMetrics: true storageClassName: my-storage-class Salve as alterações.
Verifique a integridade dos pods:
kubectl --kubeconfig=KUBECONFIG -n kube-system get pods | grep stackdriver
Por exemplo, um pod íntegro se parece com o seguinte:
stackdriver-prometheus-k8s-0 1/1 Running 0 5d19h
Verifique a especificação do pod de um componente para garantir que a classe de armazenamento esteja definida corretamente.
kubectl --kubeconfig=KUBECONFIG -n kube-system describe statefulset STATEFULSET_NAME
Por exemplo, usando o conjunto com estado
stackdriver-prometheus-k8s, a resposta será assim:Volume Claims: Name: stackdriver-prometheus-data StorageClass: my-storage-class Labels: Annotations: Capacity: 120Gi Access Modes: [ReadWriteOnce]
Como acessar dados de métricas
É possível escolher entre mais de 1.500 métricas usando o Metrics Explorer. Para acessar o Metrics Explorer, faça o seguinte:
No Console do Google Cloud, selecione Monitoring ou use o seguinte botão:
Selecione Recursos > Metrics Explorer.
Como acessar os metadados do Monitoring
Os metadados são usados indiretamente por meio de métricas. Ao filtrar métricas no
Metrics Explorer do Monitoring, você verá opções para filtrar métricas por
metadata.systemLabels e metadata.userLabels. Os rótulos do sistema são rótulos como
o nome do nó e o nome do serviço para os pods. Os rótulos de usuário são atribuídos a pods
nos arquivos YAML do Kubernetes na seção "metadados" da especificação do pod.
Limites de cota padrão do Cloud Monitoring
Os clusters do Anthos no monitoramento do VMware têm um limite padrão de 6.000 chamadas de API por minuto para cada projeto. Se você exceder esse limite, suas métricas poderão não ser exibidas. Se você precisar de um limite de monitoramento maior, solicite um por meio do Console do Google Cloud.
Problema conhecido: condição de erro do Cloud Monitoring
(ID do problema 159761921)
Em determinadas condições, o pod padrão do Cloud Monitoring,
implantado por padrão em cada novo cluster, pode não responder.
Quando os clusters são atualizados, por exemplo, os dados de armazenamento podem ser
corrompidos quando os pods em statefulset/prometheus-stackdriver-k8s forem reiniciados.
Especificamente, o pod de monitoramento stackdriver-prometheus-k8s-0 pode ser
ativado em um loop quando dados corrompidos impedem a gravação de prometheus-stackdriver-sidecar
no armazenamento do cluster PersistentVolume.
É possível diagnosticar e recuperar manualmente o erro seguindo as etapas abaixo.
Como diagnosticar o erro do Cloud Monitoring
Quando o pod de monitoramento falha, os registros informam o seguinte:
{"log":"level=warn ts=2020-04-08T22:15:44.557Z caller=queue_manager.go:534 component=queue_manager msg=\"Unrecoverable error sending samples to remote storage\" err=\"rpc error: code = InvalidArgument desc = One or more TimeSeries could not be written: One or more points were written more frequently than the maximum sampling period configured for the metric.: timeSeries[0-114]; Unknown metric: kubernetes.io/anthos/scheduler_pending_pods: timeSeries[196-198]\"\n","stream":"stderr","time":"2020-04-08T22:15:44.558246866Z"}
{"log":"level=info ts=2020-04-08T22:15:44.656Z caller=queue_manager.go:229 component=queue_manager msg=\"Remote storage stopped.\"\n","stream":"stderr","time":"2020-04-08T22:15:44.656798666Z"}
{"log":"level=error ts=2020-04-08T22:15:44.663Z caller=main.go:603 err=\"corruption after 29032448 bytes: unexpected non-zero byte in padded page\"\n","stream":"stderr","time":"2020-04-08T22:15:44.663707748Z"}
{"log":"level=info ts=2020-04-08T22:15:44.663Z caller=main.go:605 msg=\"See you next time!\"\n","stream":"stderr","time":"2020-04-08T22:15:44.664000941Z"}
Como se recuperar do erro do Cloud Monitoring
Para recuperar o Cloud Monitoring manualmente:
Interrompa o monitoramento do cluster. Reduza o operador
stackdriverpara evitar a reconciliação do monitoramento:kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas 0
Exclua as cargas de trabalho do pipeline de monitoramento:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete statefulset stackdriver-prometheus-k8s
Exclua o pipeline de monitoramento PersistentVolumeClaims (PVCs):
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system delete pvc -l app=stackdriver-prometheus-k8s
Reinicie o monitoramento do cluster. Aumente o operador do Stackdriver para reinstalar um novo pipeline de monitoramento e retomar a reconciliação:
kubectl --kubeconfig /ADMIN_CLUSTER_KUBCONFIG --namespace kube-system scale deployment stackdriver-operator --replicas=1
Prometheus e Grafana
As seções a seguir explicam como usar o Prometheus e o Grafana com clusters do Anthos em clusters do VMware.
Como ativar o Prometheus e o Grafana
A partir dos clusters do Anthos no VMware versão 1.2, escolha se quer ativar ou desativar o Prometheus e o Grafana. Em novos clusters de usuários, o Prometheus e o Grafana são desativados por padrão.
Seu cluster de usuário tem um objeto do Monitoring chamado
monitoring-sample. Abra o objeto para edição:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] edit \ monitoring monitoring-sample --namespace kube-system
em que [USER_CLUSTER_KUBECONFIG] é o arquivo kubeconfig do cluster de usuário.
Para ativar o Prometheus e o Grafana, defina
enablePrometheuscomotrue. Para desativar o Prometheus e o Grafana, definaenablePrometheuscomofalse:apiVersion: addons.k8s.io/v1alpha1 kind: Monitoring metadata: labels: k8s-app: monitoring-operator name: monitoring-sample namespace: kube-system spec: channel: stable ... enablePrometheus: true
Salve as alterações fechando a sessão de edição.
Problema conhecido
Nos clusters do usuário, o Prometheus e o Grafana são desativados automaticamente durante o upgrade. No entanto, os dados de configuração e métricas não são perdidos.
Para contornar esse problema, depois do upgrade, abra monitoring-sample para
edição e defina enablePrometheus como true.
Como acessar métricas de monitoramento nos painéis do Grafana
O Grafana exibe métricas coletadas dos clusters. Para visualizar essas métricas, acesse os painéis do Grafana:
Receba o nome do pod do Grafana em execução no namespace
kube-systemde um cluster de usuário:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system get pods
em que [USER_CLUSTER_KUBECONFIG] é o arquivo kubeconfig do cluster de usuário.
O pod do Grafana tem um servidor HTTP usando a porta TCP localhost 3000. Encaminhe uma porta local para a porta 3000 no pod a fim de visualizar os painéis do Grafana em um navegador da Web.
Por exemplo, suponha que o nome do pod seja
grafana-0. Para encaminhar a porta 50000 para a porta 3000 no pod, digite este comando:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system port-forward grafana-0 50000:3000
Em um navegador da Web, acesse
http://localhost:50000.Na página de login, digite
adminpara nome de usuário e senha.Se o login for concluído, você verá uma solicitação para alterar a senha. Depois de alterar a senha padrão, o painel inicial do Grafana do cluster de usuário será carregado.
Para acessar outros painéis, clique no menu suspenso Página inicial no canto superior esquerdo da página.
Para um exemplo de uso do Grafana, consulte Criar um painel do Grafana.
Como acessar alertas
O Prometheus Alertmanager coleta alertas do servidor do Prometheus. É possível ver esses alertas em um painel do Grafana. Para ver os alertas, acesse o painel:
O contêiner no pod
alertmanager-0detecta atividade na porta TCP 9093. Encaminhe uma porta local para a porta 9093 no pod:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward \ -n kube-system alertmanager-0 50001:9093
Em um navegador da Web, acesse
http://localhost:50001.
Como alterar a configuração do Prometheus Alertmanager
É possível alterar a configuração padrão do Prometheus Alertmanager editando o
arquivo monitoring.yaml do cluster de usuário. Faça isso se quiser direcionar
alertas para um destino específico, em vez de mantê-los no painel. Saiba
como configurar o Alertmanager na documentação
de Configuração do Prometheus.
Para alterar a configuração do Alertmanager, execute as seguintes etapas:
Faça uma cópia do arquivo de manifesto
monitoring.yamldo cluster de usuário:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system \ get monitoring monitoring-sample -o yaml > monitoring.yaml
Para configurar o Alertmanager, faça alterações nos campos em
spec.alertmanager.yml. Quando terminar, salve o manifesto alterado.Aplique o manifesto ao cluster:
kubectl apply --kubeconfig [USER_CLUSTER_KUBECONIFG] -f monitoring.yaml
Como escalonar recursos do Prometheus
A configuração de monitoramento padrão é compatível com até cinco nós. Para clusters maiores, é possível ajustar os recursos do servidor do Prometheus. A recomendação é de 50 milhões de núcleos de CPU e 500 Mi de memória por nó de cluster. Verifique se o cluster contém dois nós, cada um com recursos suficientes para caber no Prometheus. Para mais informações, consulte Como redimensionar um cluster de usuário.
Para alterar os recursos do servidor do Prometheus, execute as seguintes etapas:
Faça uma cópia do arquivo de manifesto
monitoring.yamldo cluster de usuário:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] -n kube-system get monitoring monitoring-sample -o yaml > monitoring.yaml
Para modificar recursos, faça alterações nos campos em
spec.resourceOverride. Quando terminar, salve o manifesto alterado. Exemplo:spec: resourceOverride: - component: Prometheus resources: requests: cpu: 300m memory: 3000Mi limits: cpu: 300m memory: 3000MiAplique o manifesto ao cluster:
kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] apply -f monitoring.yaml
Criar um painel do Grafana
Você implantou um aplicativo que expõe uma métrica, verificou se ela foi exposta e verificou se o Prometheus extrai a métrica. Agora é possível adicionar a métrica no nível do aplicativo a um painel personalizado do Grafana.
Para criar um painel do Grafana, siga estas etapas:
- Se necessário, tenha acesso ao Grafana.
- No painel inicial, clique no menu suspenso Início no canto superior esquerdo da página.
- No menu lateral direito, clique em Novo painel.
- Na seção Novo painel, clique em Gráfico. Um painel de gráfico vazio é exibido.
- Clique em Título do painel e, depois, em Editar. O painel inferior Gráfico é aberto na guia Métricas.
- No menu suspenso Fonte de dados, selecione usuário. Clique em Adicionar
consulta e insira
foono campo pesquisa. - Clique no botão Voltar para o painel no canto superior direito da tela. O painel é exibido.
- Para salvar o painel, clique em Salvar painel no canto superior direito da tela. Escolha um nome para o painel e clique em Salvar.
Como desativar o monitoramento no cluster
Para desativar o monitoramento no cluster, reverta as alterações feitas no
objeto monitoring-sample:
Abra o objeto
monitoring-samplepara edição:kubectl --kubeconfig USER_CLUSTER_KUBECONFIG edit \ monitoring monitoring-sample --namespace kube-system
Substitua USER_CLUSTER_KUBECONFIG pelo arquivo kubeconfig do cluster de usuário.
Para desativar o Prometheus e o Grafana, defina
enablePrometheuscomofalse:apiVersion: addons.k8s.io/v1alpha1 kind: Monitoring metadata: labels: k8s-app: monitoring-operator name: monitoring-sample namespace: kube-system spec: channel: stable ... enablePrometheus: falseSalve as alterações fechando a sessão de edição.
Confirme se os statefulsets
prometheus-0,prometheus-1egrafana-0foram excluídos:kubectl --kubeconfig USER_CLUSTER_KUBECONFIG get pods --namespace kube-system
Exemplo: como adicionar métricas no nível do aplicativo a um painel do Grafana
As seções a seguir explicam como adicionar métricas em um aplicativo. Nesta seção, você concluirá as seguintes tarefas:
- Implantar um aplicativo de exemplo que exponha uma métrica chamada
foo. - Verificar se o Prometheus expõe e extrai a métrica.
- Criar um painel personalizado do Grafana.
Implantar o aplicativo de exemplo
O aplicativo de exemplo é executado em um único pod. O contêiner do pod expõe uma
métrica, foo, com um valor constante de 40.
Crie o seguinte manifesto do pod, pro-pod.yaml:
apiVersion: v1
kind: Pod
metadata:
name: prometheus-example
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '8080'
prometheus.io/path: '/metrics'
spec:
containers:
- image: registry.k8s.io/prometheus-dummy-exporter:v0.1.0
name: prometheus-example
command:
- /bin/sh
- -c
- ./prometheus_dummy_exporter --metric-name=foo --metric-value=40 --port=8080
Em seguida, aplique o manifesto do pod ao cluster de usuário:
kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] apply -f pro-pod.yaml
Verificar se a métrica foi exposta e extraída
O contêiner no pod
prometheus-exampledetecta atividade na porta TCP 8080. Encaminhe uma porta local para a porta 8080 no pod:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-example 50002:8080
Para verificar se o aplicativo expõe a métrica, execute o seguinte comando:
curl localhost:50002/metrics | grep fooO comando retorna a seguinte saída:
# HELP foo Custom metric # TYPE foo gauge foo 40
O contêiner no pod
prometheus-0detecta atividade na porta TCP 9090. Encaminhe uma porta local para a porta 9090 no pod:kubectl --kubeconfig [USER_CLUSTER_KUBECONFIG] port-forward prometheus-0 50003:9090
Para verificar se o Prometheus está extraindo a métrica, acesse http://localhost:50003/targets, que levará você ao pod
prometheus-0no grupo de destino .prometheus-io-podsPara visualizar métricas no Prometheus, acesse http://localhost:50003/graph. No campo pesquisa, digite
fooe clique em Executar. A página deve exibir a métrica.