This page describes your high availability (HA) options in Google Distributed Cloud, how to set up certain Google Distributed Cloud components for HA, and how to recover from disasters.
Core functionality
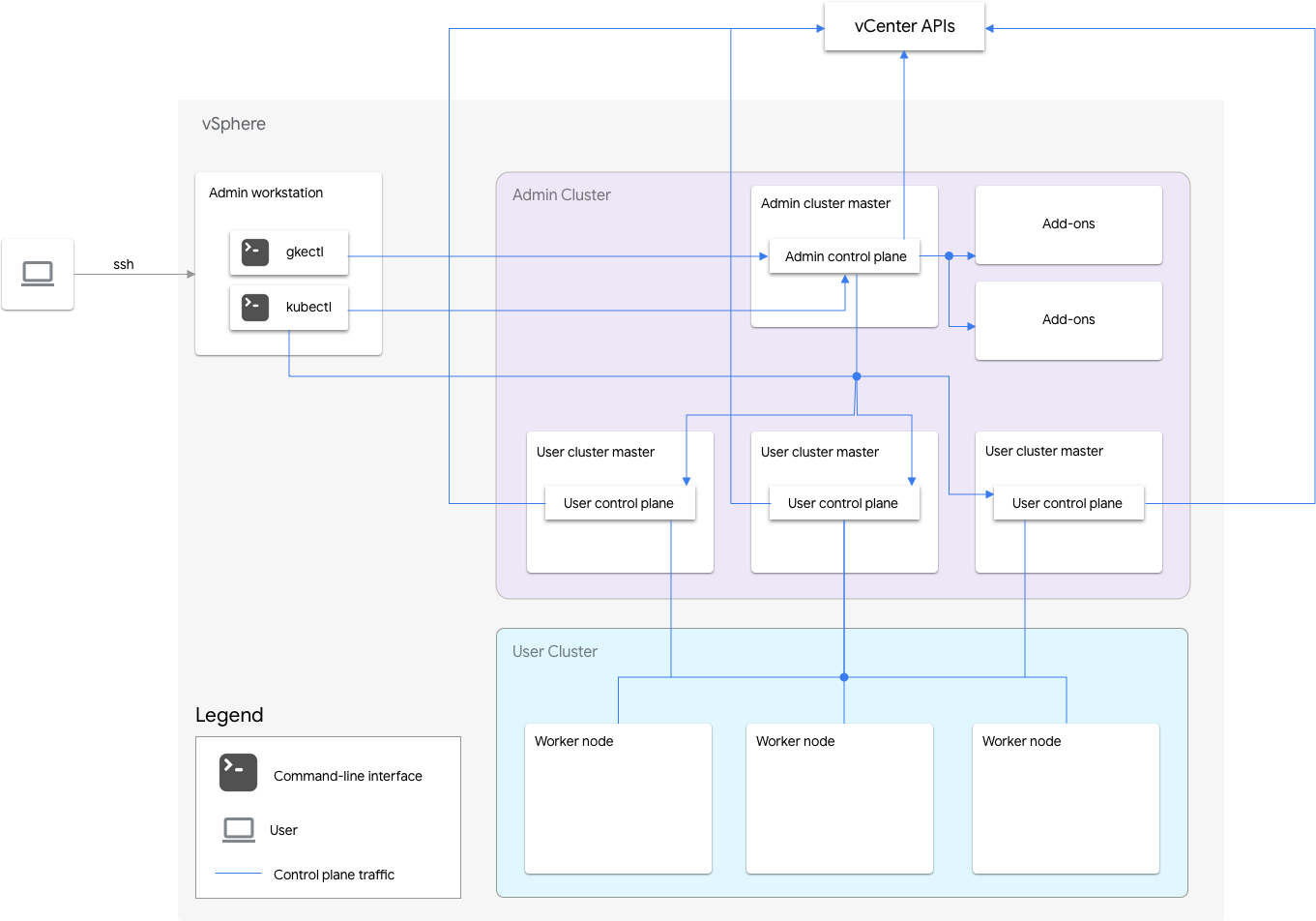
Google Distributed Cloud includes an admin cluster and one or more user clusters.
The admin cluster manages the lifecycle of the user clusters, including user cluster creation, updates, upgrades, and deletion. In the admin cluster, the admin master manages the admin worker nodes, which include user masters (nodes running the control plane of the managed user clusters) and addon nodes (nodes running the addon components supporting the admin cluster's functionality).
For each user cluster, the admin cluster has one non-HA node or three HA nodes that run the control plane. The control plane includes the Kubernetes API server, the Kubernetes scheduler, the Kubernetes controller manager, and several critical controllers for the user cluster.
The user cluster's control plane availability is critical to workload operations such as workload creation, scaling up and down, and termination. In other words, a control plane outage does not interfere with the running workloads, but the existing workloads lose management capabilities from the Kubernetes API server if its control plane is absent.
Containerized workloads and services are deployed in the user cluster worker nodes. Any single worker node should not be critical to application availability as long as the application is deployed with redundant pods scheduled across multiple worker nodes.
Google Distributed Cloud is designed to ensure that failures are isolated to a functional area as much as possible and to prioritize functionality that's critical to business continuity.
The core functionality of Google Distributed Cloud includes the following categories:
Application lifecycle
Existing workloads can run continuously. This is the most important functionality to ensure business continuity.
You can create, update, and delete workloads. This is the second most important functionality because Google Distributed Cloud needs to scale workloads when traffic increases.
User cluster lifecycle
You can add, update, upgrade, and delete user clusters. This is less important because the inability to modify user clusters doesn't affect user workloads.
Admin cluster lifecycle
You can update and upgrade the admin cluster. This is the least important because the admin cluster does not host any user workloads.
Failure modes
The following types of failures can affect the performance of Google Distributed Cloud clusters.
ESXi host failure
An ESXi host that runs virtual machine (VM) instances hosting Kubernetes nodes might stop functioning or become network partitioned.
| Existing workloads | Creating, updating, and deleting workloads | User cluster lifecycle | Admin cluster lifecycle |
|---|---|---|---|
| Possible disruption + automatic recovery |
Possible disruption + automatic recovery |
Disruption + automatic recovery |
Disruption + automatic recovery |
The Pods running on the VMs hosted by the failed host are disrupted, and are automatically rescheduled onto other healthy VMs. If user applications have spare workload capacity and are spread across multiple nodes, the disruption is not observable by clients that implement retries. |
If the host failure affects the control-plane VM in a non-HA user cluster or more than one control-plane VM in an HA user cluster, there is disruption. | If the host failure affects the control-plane VM or the worker VMs in the admin cluster, there is disruption. | If the host failure affects the control-plane VM in the admin cluster, there is disruption. |
| vSphere HA automatically restarts the VMs on healthy hosts. | vSphere HA automatically restarts the VMs on healthy hosts. | vSphere HA automatically restarts the VMs on healthy hosts. | vSphere HA automatically restarts the VMs on healthy hosts. |
| Deploy workloads in an HA way to minimize the possibility of disruption. | Use HA user clusters to minimize the possibility of disruption. |
VM failure
A VM might get deleted unexpectedly, or a boot disk might become corrupted. Also, a VM might be compromised because of operating system issues.
| Existing workloads | Creating, updating, and deleting workloads | User cluster lifecycle | Admin cluster lifecycle |
|---|---|---|---|
| Possible disruption + automatic recovery |
Possible disruption + automatic recovery |
Disruption + automatic/manual recovery |
Disruption + manual recovery |
The Pods running on the failed worker VMs are disrupted, and they are automatically rescheduled onto other healthy VMs by Kubernetes. If user applications have spare workload capacity and are spread across multiple nodes, the disruption is not observable by clients that implement retries. |
If the control-plane VM in a non-HA user cluster or more than one control-plane VM in an HA user cluster fails, there is disruption. | If the control-plane VM or the worker VMs in the admin cluster fail, there is disruption. | If the control-plane VM in the admin cluster fails, there is disruption. |
| The failed VM is automatically recovered if node auto-repair is enabled in the user cluster. | The failed VM is automatically recovered if node auto-repair is enabled in the admin cluster. | The failed worker VM in the admin cluster is automatically recovered if node auto-repair is enabled in the admin cluster. To recover the admin cluster's control-plane VM, see Repairing the admin cluster's control-plane VM. |
To recover the admin cluster's control-plane VM, see Repairing the admin cluster's control-plane VM. |
| Deploy workloads in an HA way to minimize the possibility of disruption. | Use HA user clusters to minimize the possibility of disruption. |
Storage failure
The content in a VMDK file might be corrupted due to ungraceful power down of a VM, or a datastore failure might cause etcd data and PersistentVolumes (PVs) to be lost.
etcd failure
| Existing workloads | Creating, updating, and deleting workloads | User cluster lifecycle | Admin cluster lifecycle |
|---|---|---|---|
| No disruption | Possible disruption + Manual recovery |
Disruption + Manual recovery |
Disruption + Manual recovery |
| If the etcd store in a non-HA user cluster or more than one etcd replica in an HA user cluster fails, there is disruption. | If the etcd store in a non-HA user cluster or more than one etcd replica in an HA user cluster fails, there is disruption. If the etcd replica in an admin cluster fails, there is disruption. |
If the etcd replica in an admin cluster fails, there is disruption. | |
| Google Distributed Cloud provides a manual process to recover from the failure. | Google Distributed Cloud provides a manual process to recover from the failure. | Google Distributed Cloud provides a manual process to recover from the failure. |
User application PV failure
| Existing workloads | Creating, updating, and deleting workloads | User cluster lifecycle | Admin cluster lifecycle |
|---|---|---|---|
| Possible disruption | No disruption | No disruption | No disruption |
The workloads using the failed PV are affected. Deploy workloads in the HA way to minimize the possibility of disruption. |
Load balancer failure
A load balancer failure might affect user workloads that expose Services of
type LoadBalancer.
| Existing workloads | Creating, updating, and deleting workloads | User cluster lifecycle | Admin cluster lifecycle |
|---|---|---|---|
| Disruption + Manual recovery |
|||
|
There are a few seconds of disruption until the standby load balancer recovers the admin control plane VIP connection. The service disruption might be up to 2 seconds when using Seesaw, and up to 300 seconds when using F5. Seesaw HA automatically detects the failure and fails over to using the backup instance. Google Distributed Cloud provides a manual process to recover from a Seesaw failure. |
|||
Enabling high availability
vSphere and Google Distributed Cloud provide a number of features that contribute to high availability (HA).
vSphere HA and vMotion
We recommend enabling the following two features in the vCenter cluster that hosts your Google Distributed Cloud clusters:
These features enhance availability and recovery in case an ESXi host fails.
vCenter HA uses multiple ESXi hosts configured as a cluster to provide rapid
recovery from outages and cost-effective HA for applications
running in virtual machines. We recommend that you provision your vCenter
cluster with extra hosts and
enable vSphere HA Host Monitoring
with Host Failure Response set to Restart VMs. Your VMs can then be
automatically restarted on other available hosts in case of an ESXi host failure.
vMotion allows zero-downtime live migration of VMs from one ESXi host to another. For planned host maintenance, you can use vMotion live migration to avoid application downtime entirely and ensure business continuity.
Admin cluster
Google Distributed Cloud doesn't support running multiple control planes for the admin cluster. However, unavailability of the admin control plane doesn't affect existing user cluster functionality or any workloads running in user clusters.
There are two add-on nodes in an admin cluster. If one is down, the other one
can still serve the admin cluster operations. For redundancy,
Google Distributed Cloud spreads critical add-on Services, such as kube-dns,
across both of the add-on nodes.
If you set antiAffinityGroups.enabled to true in the admin cluster
configuration file, Google Distributed Cloud automatically creates
vSphere DRS
anti-affinity rules for the add-on nodes, which causes them to be spread across
two physical hosts for HA.
User cluster
You can enable HA for a user cluster by setting masterNode.replicas to 3 in
the user cluster configuration file. This results in three nodes in the admin
cluster, each of which runs a control plane for the user cluster. Each
of those nodes also runs an etcd replica. The user cluster continues to work
as long as there is one control plane running and an etcd quorum. An etcd
quorum requires that two of the three etcd replicas are functioning.
If you set antiAffinityGroups.enabled to true in the admin cluster
configuration file, Google Distributed Cloud automatically creates vSphere DRS
anti-affinity rules for the three nodes that run the user cluster control plane.
This causes those VMs to be spread across three physical hosts.
Google Distributed Cloud also creates vSphere DRS anti-affinity rules for the worker nodes in your user cluster, which causes those nodes to be spread across at least three physical hosts. Multiple DRS anti-affinity rules are used per user cluster node-pool based on the number of nodes. This ensures that the worker nodes can find hosts to run on, even when the number of hosts is less than the number of VMs in the user cluster node-pool. We recommend that you include extra physical hosts in your vCenter cluster. Also configure DRS to be fully automated so that in case a host becomes unavailable, DRS can automatically restart VMs on other available hosts without violating the VMs' anti-affinity rules.
Google Distributed Cloud maintains a special node label,
onprem.gke.io/failure-domain-name, whose value is set to the underlying ESXi
host name. User applications that want high availability can set up
podAntiAffinity rules with this label as the topologyKey to ensure that
their application Pods are spread across different VMs as well as physical hosts.
You can also configure multiple node pools for a user cluster with different
datastores and special node labels. Similarly, you can set up podAntiAffinity
rules with that special node label as the topologyKey to achieve higher
availability upon datastore failures.
To have HA for user workloads, ensure that the user cluster has a sufficient number
of replicas under nodePools.replicas, which ensures the desired number of user
cluster worker nodes in running condition.
You can use separate datastores for admin clusters and user clusters to isolate their failures.
Load balancer
There are two types of load balancers that you can use for high availability.
Bundled Seesaw load balancer
For the
bundled Seesaw load balancer,
you can enable HA by setting
loadBalancer.seesaw.enableHA to true in the cluster configuration file.
You must also enable a combination of MAC learning, forged transmits,
and promiscuous mode on your load balancer port group.
With HA, two load balancers are set up in active-passive mode. If the active load balancer has a problem, the traffic fails over to the passive load balancer.
During an upgrade of a load balancer, there is some downtime. If HA is enabled for the load balancer, the maximum downtime is two seconds.
Integrated F5 BIG-IP load balancer
The F5 BIG-IP platform provides various Services to help you enhance the security, availability, and performance of your applications. For Google Distributed Cloud, BIG-IP provides external access and L3/4 load balancing Services.
Recovering a broken cluster
The following sections describe how to recover a broken cluster.
Recovery from ESXi host failures
Google Distributed Cloud relies on vSphere HA to provide recovery from an ESXi host failure. vSphere HA can continuously monitor ESXi hosts and automatically restart the VMs on other hosts when needed. This is transparent to Google Distributed Cloud users.
Recovery from VM failures
VM failures can include the following:
Unexpected deletion of a VM.
VM boot disk corruption; for example, a boot disk became read-only due to spam journal logs.
VM boot failure due to low performance disk or network setup issues; for example, a VM cannot boot because an IP address cannot be allocated to it for some reason.
Docker overlay file system corruption.
Loss of admin control-plane VM due to an upgrade failure.
Operating system issues.
The VM failures discussed in this section do not include data corruption or loss on the PV or etcd data disks attached to the VM. For that, see Recovery from storage failures.
Google Distributed Cloud provides an automatic recovery mechanism for the admin add-on nodes, user control planes, and user nodes. This node auto-repair feature can be enabled per admin cluster and user cluster.
The admin control-plane VM is special in the sense that it's not managed by a Kubernetes cluster, and its availability does not affect business continuity. For the recovery of admin control-plane VM failures, contact Google Support.
Recovery from storage failures
Some of the storage failures can be mitigated by vSphere HA and vSAN without affecting Google Distributed Cloud. However, certain storage failures might surface from the vSphere level causing data corruption or loss on various Google Distributed Cloud components.
The stateful information of a cluster and user workloads is stored in the following places:
etcd
Each cluster (admin cluster and user cluster) has an etcd database that stores the state (Kubernetes objects) of the cluster.
PersistentVolumes
Used by both system components and user workloads.
Recovery from etcd data corruption or loss
etcd is the database used by Kubernetes to store all cluster state, including user application manifests. The application lifecycle operations would stop functioning if the etcd database of the user cluster is corrupted or lost. The user cluster lifecycle operations would stop functioning if the etcd database of the admin cluster is corrupted or lost.
etcd doesn't provide a reliable built-in mechanism for detecting data corruption. You need to look at the logs of the etcd Pods if you suspect that the etcd data is corrupted or lost.
A pending/error/crash-looping etcd Pod doesn't always mean that the etcd data is corrupted or lost. It could be due to the errors on the VMs that host the etcd Pods. You should perform the following etcd recovery only for data corruption or loss.
To be able to recover (to a recent cluster state) from etcd data corruption or loss, the etcd data must be backed up after any lifecycle operation in the cluster (for example, creating, updating, or upgrading). To back up the etcd data, see Backing up an admin cluster and Backing up a user cluster.
Restoring etcd data takes the cluster into a previous state. In other words, if a backup is taken before an application is deployed and then that backup is used to restore the cluster, the application will not be running in the restored cluster. For example, if you use the etcd snapshot of an admin cluster that's snapshotted before creating a user cluster, then the restored admin cluster has the user cluster control plane removed. Therefore, we recommend that you back up the cluster after each critical cluster operation.
The etcd data corruption/loss failure can happen in the following scenarios:
A single node of a three-node etcd cluster (HA user cluster) is permanently broken due to data corruption or loss. In this case, only a single node is broken and the etcd quorum still exists. This might happen in an HA cluster, where the data of one of the etcd replicas is corrupted or lost. The problem can be fixed without any data loss by replacing the failed etcd replica with a new one in the clean state. For more information, see Replacing a failed etcd replica.
Two nodes of a three-node etcd cluster (HA user cluster) are permanently broken due to data corruption or loss. The quorum is lost, so replacing the failed etcd replicas with new ones does not help. The cluster state must be restored from backup data. For more information, see Restoring a user cluster from a backup (HA).
A single-node etcd cluster (admin cluster or non-HA user cluster) is permanently broken due to data corruption or loss. The quorum is lost, so you must create a new cluster from the backup. For more information, see Restoring a user cluster from a backup (non-HA).
Recovery from user application PV corruption or loss
Google Distributed Cloud customers can use certain partner storage solutions to back up and restore user application PersistentVolumes.
For the list of storage partners that have been qualified for Google Distributed Cloud, see Anthos Ready Storage Partners.
Recovery from load balancer failures
For bundled load balancing (Seesaw), you can recover from failures by recreating the load balancer. To recreate the load balancer, upgrade Seesaw to the same version as shown in Upgrading the load balancer for your admin cluster.
In the case of admin cluster load balancer failures, the control plane might be out of reach. As a result, you need to run the upgrade on the admin control-plane VM where there is control plane access.
For integrated load balancers (F5), consult with F5 Support.
Using multiple clusters for disaster recovery
Deploying applications in multiple clusters across multiple vCenters or GKE Enterprise platforms can provide higher global availability and limit the blast radius during outages.
This setup uses the existing GKE Enterprise cluster in the secondary data center for disaster recovery rather than setting up a new cluster. Following is a high-level summary to achieve this:
Create another admin cluster and user cluster in the secondary data center. In this multi-cluster architecture, we require users to have two admin clusters in each data center, and each admin cluster runs a user cluster.
The secondary user cluster has a minimal number of worker nodes (three) and is a hot standby (always running).
Application deployments can be replicated across the two vCenters by using Config Management, or the preferred approach is to use an existing application DevOps (CI/CD, Spinnaker) toolchain.
In the event of a disaster, the user cluster can be resized to the number of nodes.
Additionally, a DNS switchover is required to route traffic between the clusters to the secondary data center.