このページでは、Config Sync リソースのモニタリングに使用できる OpenTelemetry の指標について説明します。
料金
Config Sync の指標は、Google Cloud Managed Service for Prometheus を使用して、Cloud Monitoring に指標を読み込みます。Cloud Monitoring では、取り込まれたサンプルの数に基づいて、これらの指標の取り込みに対して課金されます。
詳細については、Cloud Monitoring の料金をご覧ください。
Config Sync が指標を収集する仕組み
Config Sync は、指標の作成と記録に OpenCensus を使用します。また、その指標を Prometheus または Cloud Monitoring にエクスポートするために OpenTelemetry を使用します。以下のガイドでは、指標をエクスポートする方法について説明します。
OpenTelemetry Collector を構成するために、Config Sync はデフォルトで otel-collector という名前の ConfigMap を作成します。otel-collector Deployment は config-management-monitoring Namespace で実行されます。
otel-collector ConfigMap を作成すると、Prometheus がスキャンする指標エンドポイントを公開する prometheus エクスポータが構成されます。
Config Sync を GKE で実行するか、 Google Cloud 認証情報で構成された別の Kubernetes 環境で実行する場合、Config Sync は otel-collector-google-cloud という名前の ConfigMap を作成します。otel-collector-google-cloud は、otel-collector ConfigMap の構成をオーバーライドします。Config Sync は、otel-collector または otel-collector-google-cloud ConfigMap の変更を元に戻します。
otel-collector-google-cloud ConfigMap を作成すると、Cloud Monitoring にエクスポートする cloudmonitoring エクスポータと、Google の内部指標サービスにエクスポートする kubernetes エクスポータも追加されます。kubernetes エクスポータは、Config Sync の改善に役立てるため、一部の匿名化された指標を Google に送信します。
Cloud Monitoring は、送信された指標をGoogle Cloud プロジェクトに保存します。cloudmonitoring エクスポータと kubernetes エクスポータは同じGoogle Cloud サービス アカウントを使用します。このサービス アカウントには、Cloud Monitoring に書き込みをする IAM 権限が必要です。これらの権限を構成するには、Cloud Monitoring に指標書き込み権限を付与するをご覧ください。
OpenTelemetry の指標
Config Sync と Resource Group Controller は OpenCensus を使用して以下の指標を収集し、OpenTelemetry Collector を通じて利用できるようにします。[タグ] 列には、各指標に適用される Config Sync 固有のタグが記載されています。タグのある指標はタグ値の組み合わせごとに 1 つずつ、つまり複数の測定を表します。
Config Sync の指標
| 名前 | タイプ | タグ | 説明 |
|---|---|---|---|
| api_duration_seconds | 分布 | オペレーション、ステータス | API サーバー呼び出しのレイテンシの分布。 |
| apply_duration_seconds | 分布 | status | 信頼できる情報源から宣言されたリソースをクラスタに適用するレイテンシの分布。 |
| apply_operations_total | カウント | operation、status、controller | リソースを信頼できる情報源からクラスタに同期するために実行されたオペレーションの総数。 |
| declared_resources | 前回の値 | 解析された、Git 内で宣言されているリソースの数。 | |
| internal_errors_total | カウント | source | Config Sync によって検出された内部エラーの総数。内部エラーが発生していない場合、指標がクエリ結果に表示されないことがあります。 |
| last_sync_timestamp | 前回の値 | status | Git から最後に同期が行われた時刻のタイムスタンプ。 |
| parser_duration_seconds | 分布 | status、trigger、source | 信頼できる情報源からクラスタと同期する際のさまざまなステージのレイテンシの分布。 |
| pipeline_error_observed | 前回の値 | name、reconciler、component | RootSync と RepoSync のカスタム リソースのステータス。値が 1 の場合は、失敗であることを示します。 |
| reconcile_duration_seconds | 分布 | ステータス | 調整ツール マネージャーによって処理される調整イベントのレイテンシの分布。 |
| reconciler_errors | 前回の値 | component、errorclass | 信頼できる情報源からクラスタにリソースを同期するときに発生したエラーの数。 |
| remediate_duration_seconds | 分布 | status | リメディエーター調整イベントのレイテンシの分布。 |
| resource_conflicts_total | カウント | キャッシュに保存されたリソースとクラスタ リソースの不一致が原因で発生したリソース競合の総数。リソースの競合が発生していない場合、指標がクエリ結果に表示されないことがあります。 | |
| resource_fights_total | カウント | 同期の頻度が高すぎるリソースの総数。結果が 0 より大きい場合は、問題があることを示します。詳細については、KNV2005: ResourceFightWarning をご覧ください。リソースの競合が発生していない場合、指標がクエリ結果に表示されないことがあります。 |
Resource Group Controller の指標
Resource Group Controller は Config Sync のコンポーネントです。マネージド リソースを追跡し、各リソースの準備状況や調整状況をチェックします。以下の指標を選択できます。
| 名前 | タイプ | タグ | 説明 |
|---|---|---|---|
| rg_reconcile_duration_seconds | 分布 | stallreason | ResourceGroup CR の調整にかかった時間の分布 |
| resource_group_total | 前回の値 | ResourceGroup CR の現在の数 | |
| resource_count | 前回の値 | resourcegroup | ResourceGroup で追跡されるリソースの総数 |
| ready_resource_count | 前回の値 | resourcegroup | ResourceGroup の準備完了リソースの総数 |
| resource_ns_count | 前回の値 | resourcegroup | ResourceGroup のリソースで使用される名前空間の数 |
| cluster_scoped_resource_count | 前回の値 | resourcegroup | ResourceGroup 内のクラスタ スコープのリソース数 |
| crd_count | 前回の値 | resourcegroup | ResourceGroup の CRD の数 |
| kcc_resource_count | 前回の値 | resourcegroup | ResourceGroup の KCC リソースの総数 |
| pipeline_error_observed | 前回の値 | name、reconciler、component | RootSync と RepoSync のカスタム リソースのステータス。値が 1 の場合は、失敗であることを示します。 |
Config Sync の指標ラベル
指標ラベルは、Cloud Monitoring と Prometheus で指標データを集計するために使用できます。これは、Monitoring コンソールの [グループ条件] プルダウン リストから選択できます。
Cloud Monitoring のラベルと Prometheus の指標ラベルの詳細については、指標モデルのコンポーネントと Prometheus データモデルをご覧ください。
指標ラベル
Config Sync と Resource Group Controller の指標では次のラベルが使用されます。これらは、Cloud Monitoring と Prometheus でモニタリングする際に使用できます。
| 名前 | 値 | 説明 |
|---|---|---|
operation |
create、patch、update、delete | 実行されたオペレーションのタイプ |
status |
success、error | オペレーションの実行ステータス |
reconciler |
rootsync、reposync | Reconciler のタイプ |
source |
parser、differ、remediator | 内部エラーのソース |
trigger |
try、watchUpdate、managementConflict、resync、reimport | 調整イベントのトリガー |
name |
Reconciler の名前 | Reconciler の名前 |
component |
parsing、source、sync、rendering、readiness | 調整の現在のコンポーネント / ステージの名前。 |
container |
reconciler、git-sync | コンテナの名前 |
resource |
cpu、memory | リソースのタイプ |
controller |
applier、remediator | ルートまたは Namespace Reconciler のコントローラの名前 |
type |
任意の Kubernetes リソース(例: ClusterRole、Namespace、NetworkPolicy)。 | Kubernetes API の種類 |
commit |
---- | 同期された最新の commit のハッシュ |
リソースラベル
Prometheus と Cloud Monitoring に送信される Config Sync の指標には、ソース Pod を識別するために次の指標ラベルが設定されています。
| 名前 | 説明 |
|---|---|
k8s.node.name |
Kubernetes Pod をホストしているノードの名前 |
k8s.pod.namespace |
Pod の Namespace |
k8s.pod.uid |
Pod の UID |
k8s.pod.ip |
Pod の IP |
k8s.deployment.name |
Pod を所有する Deployment の名前 |
reconciler Pod から Prometheus と Cloud Monitoring に送信される Config Sync の指標には、Reconciler の構成に使用する RootSync または RepoSync を識別する次の指標ラベルも設定されます。
| 名前 | 説明 |
|---|---|
configsync.sync.kind |
この Reconciler を構成するリソースの種類: RootSync または RepoSync |
configsync.sync.name |
この Reconciler を構成する RootSync または RepoSync の名前 |
configsync.sync.namespace |
この Reconciler を構成する RootSync または RepoSync の Namespace |
Cloud Monitoring のリソースラベル
Cloud Monitoring のリソースラベルは、ストレージ内の指標をインデックス登録するために使用されます。つまり、カーディナリティがパフォーマンスの重要な要素である指標ラベルと異なり、カーディナリティによる影響はほとんどありません。詳しくは、モニタリング対象リソースタイプをご覧ください。
k8s_container リソースタイプでは、ソースコンテナを識別するために次のリソースラベルを設定します。
| 名前 | 説明 |
|---|---|
container_name |
コンテナの名前 |
pod_name |
Pod の名前 |
namespace_name |
Pod の Namespace |
location |
ノードをホストするクラスタのリージョンまたはゾーン |
cluster_name |
ノードをホストするクラスタの名前 |
project |
クラスタをホストしているプロジェクトの ID |
カスタム指標のフィルタリングを構成する
Config Sync が Prometheus、Cloud Monitoring、Google の内部モニタリング サービスにエクスポートするカスタム指標を調整できます。カスタム指標を調整して、含まれる指標を微調整したり、別のバックエンドを構成したりします。
カスタム指標を変更するには、otel-collector-custom という名前の ConfigMap を作成して編集します。この ConfigMap を使用すると、Config Sync が変更を元に戻すことはありません。otel-collector または otel-collector-google-cloud ConfigMap を変更すると、Config Sync は変更を元に戻します。
この ConfigMap を調整する方法の例については、オープンソースの Config Sync ドキュメントのカスタム指標のフィルタリングをご覧ください。
pipeline_error_observ 指標を理解する
pipeline_error_observed 指標は、同期されていないか、目的の状態に調整されていないリソースが含まれている RepoSync または RootSync の CR を迅速に識別するために役立つ指標です。
RootSync または RepoSync による同期が正常に完了すると、すべてのコンポーネント(
rendering、source、sync、readiness)の指標が値 0 になります。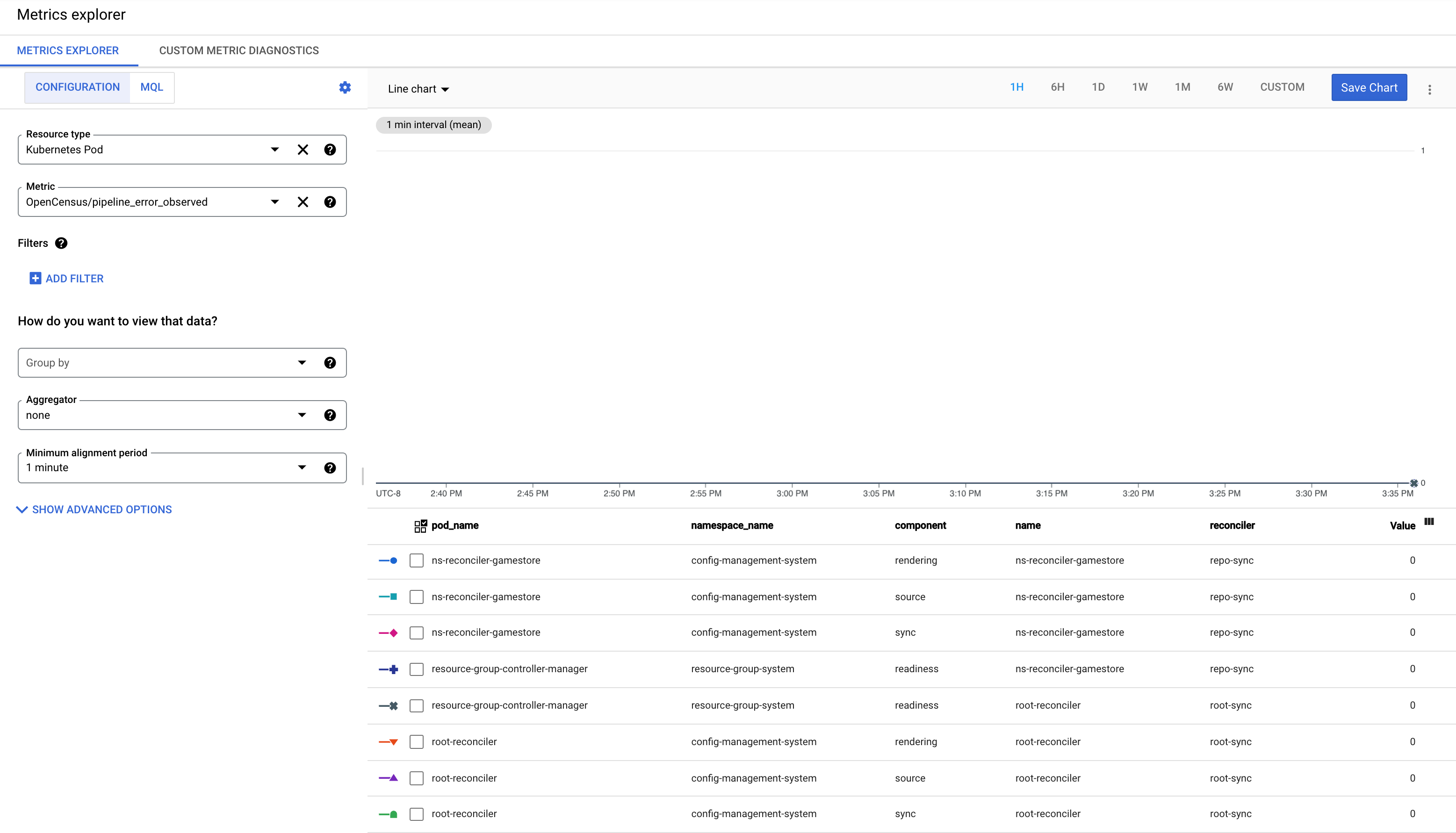
最新の commit が自動レンダリングに失敗した場合、コンポーネント
renderingの指標は値 1 になります。最新の commit でエラーが発生するか、最新の commit に無効な構成が含まれている場合、コンポーネント
sourceの指標は値 1 になります。リソースをクラスタに適用できない場合、コンポーネント
syncを含む指標が値 1 で観測されます。リソースが適用されたものの、目的の状態に到達できない場合、コンポーネント
readinessの指標は 1 の値で観測されます。たとえば、クラスタに Deployment が適用されたものの、対応する Pod が正常に作成されなかった場合などです。
次のステップ
- RootSync オブジェクトと RepoSync オブジェクトを監視する方法を学習する。
- Config Sync SLI の使用方法を学習する。