The page describes the OpenTelemetry metrics available to monitor your Config Sync resources.
Pricing
Config Sync metrics use Google Cloud Managed Service for Prometheus to load metrics into Cloud Monitoring. Cloud Monitoring charges for the ingestion of these metrics are based on the number of samples ingested.
For more information, see Cloud Monitoring pricing.
How Config Sync collects metrics
Config Sync uses OpenCensus to create and record metrics and OpenTelemetry to export its metrics to Prometheus and Cloud Monitoring. The following guides explain how to export metrics:
- Cloud Monitoring
- Prometheus
- Custom monitoring system (not recommended)
To configure the OpenTelemetry Collector, by default, Config Sync creates a
ConfigMap named otel-collector. The otel-collector Deployment runs
in the config-management-monitoring namespace.
The creation of the otel-collector ConfigMap configures the prometheus
exporter, which exposes a metrics endpoint for Prometheus to scan.
When you run Config Sync on GKE, or in another Kubernetes
environment that's configured with Google Cloud credentials, Config Sync
creates a ConfigMap named otel-collector-google-cloud. The
otel-collector-google-cloud overrides the configuration in the
otel-collector ConfigMap. Config Sync reverts any changes to the
otel-collector or otel-collector-google-cloud ConfigMaps.
The creation of the otel-collector-google-cloud ConfigMap also adds the
cloudmonitoring exporter, which exports to Cloud Monitoring, and the
kubernetes exporter, which exports to Google's internal metric service. The
kubernetes exporter sends select, anonymized metrics to Google to help improve
Config Sync.
Cloud Monitoring stores the metrics that you send to it in your
Google Cloud project. The cloudmonitoring and kubernetes exporters use the same
Google Cloud service account, which needs IAM permission to write
to Cloud Monitoring. To configure these permissions, see
Grant metric-writing permission for Cloud Monitoring.
OpenTelemetry metrics
Config Sync and the Resource Group Controller collect the following metrics with OpenCensus and make them available through OpenTelemetry Collector . The Tags column lists Config Sync specific tags that are applicable to each metric. Metrics with tags represent multiple measurements, one for each combination of tag values.
Config Sync metrics
| Name | Type | Tags | Description |
|---|---|---|---|
| api_duration_seconds | Distribution | operation, status | The latency distribution of API server calls. |
| apply_duration_seconds | Distribution | status | The latency distribution of applying resources declared from source of truth to a cluster. |
| apply_operations_total | Count | operation, status, controller | The total number of operations that have been performed to sync resources from source of truth to a cluster. |
| declared_resources | Last Value | The number of declared resources parsed from Git. | |
| internal_errors_total | Count | source | The total number of internal errors encountered by Config Sync. Metric might not appear in query results if no internal error has happened. |
| last_sync_timestamp | Last Value | status | The timestamp of the most recent sync from Git. |
| parser_duration_seconds | Distribution | status, trigger, source | The latency distribution of different stages involved in syncing from source of truth to a cluster. |
| pipeline_error_observed | Last Value | name, reconciler, component | The status of RootSync and RepoSync custom resources. A value of 1 indicates a failure. |
| reconcile_duration_seconds | Distribution | status | The latency distribution of reconcile events handled by the reconciler manager. |
| reconciler_errors | Last Value | component, errorclass | The number of errors encountered while syncing resources from the source of the truth to a cluster. |
| remediate_duration_seconds | Distribution | status | The latency distribution of remediator reconciliation events. |
| resource_conflicts_total | Count | The total number of resource conflicts resulting from a mismatch between the cached resources and cluster resources. Metric might not appear in query results if no resource conflict has happened. | |
| resource_fights_total | Count | The total number of resources that are being synced too frequently. Any result higher than zero indicates a problem. For more information, see KNV2005: ResourceFightWarning. Metric might not appear in query results if no resource fight has happened. |
Resource Group Controller metrics
The Resource Group Controller is a component in Config Sync that keeps track of the managed resources and checks if each individual resource is ready or reconciled. The following metrics are available.
| Name | Type | Tags | Description |
|---|---|---|---|
| rg_reconcile_duration_seconds | Distribution | stallreason | The distribution of time taken to reconcile a ResourceGroup CR |
| resource_group_total | Last Value | The current number of ResourceGroup CRs | |
| resource_count | Last Value | resourcegroup | The total number of resources tracked by a ResourceGroup |
| ready_resource_count | Last Value | resourcegroup | The total number of ready resources in a ResourceGroup |
| resource_ns_count | Last Value | resourcegroup | The number of namespaces used by resources in a ResourceGroup |
| cluster_scoped_resource_count | Last Value | resourcegroup | The number of cluster scoped resources in a ResourceGroup |
| crd_count | Last Value | resourcegroup | The number of CRDs in a ResourceGroup |
| kcc_resource_count | Last Value | resourcegroup | The total number of KCC resources in a ResourceGroup |
| pipeline_error_observed | Last Value | name, reconciler, component | The status of RootSync and RepoSync custom resources. A value of 1 indicates a failure. |
Config Sync metric labels
Metric labels can be used to aggregate metric data in Cloud Monitoring and Prometheus. They are selectable from the "Group By" drop-down list in the Monitoring Console.
For more information about Cloud Monitoring label and Prometheus metric label, see the Components of the metric model and Prometheus data model.
Metric labels
The following labels are used by Config Sync and Resource Group Controller metrics, available when monitoring with Cloud Monitoring and Prometheus.
| Name | Values | Description |
|---|---|---|
operation |
create, patch, update, delete | The type of operation performed |
status |
success, error | The execution status of an operation |
reconciler |
rootsync, reposync | The type of the Reconciler |
source |
parser, differ, remediator | The source of the internal error |
trigger |
retry, watchUpdate, managementConflict, resync, reimport | The trigger of an reconciliation event |
name |
The name of reconciler | The name of the Reconciler |
component |
parsing, source, sync, rendering, readiness | The name of component / current stage of reconciliation |
container |
reconciler, git-sync | The name of the container |
resource |
cpu, memory | The type of the resource |
controller |
applier, remediator | The name of the controller in a root or namespace reconciler |
type |
Any Kubernetes resource, for example ClusterRole, Namespace, NetworkPolicy, Role, and so on. | The kind of Kubernetes API |
commit |
---- | The hash of the latest synced commit |
Resource labels
Config Sync metrics sent to Prometheus and Cloud Monitoring have the following metric labels set to identify the source Pod:
| Name | Description |
|---|---|
k8s.node.name |
The name of the Node hosting a Kubernetes Pod |
k8s.pod.namespace |
The namespace of the Pod |
k8s.pod.uid |
The UID of the Pod |
k8s.pod.ip |
The IP of the Pod |
k8s.deployment.name |
The name of the Deployment that owns the Pod |
Config Sync metrics sent to Prometheus and Cloud Monitoring from reconciler Pods also have the
following metric labels set to identify the RootSync or RepoSync used to configure
the reconciler:
| Name | Description |
|---|---|
configsync.sync.kind |
The kind of resource that configures this reconciler: RootSync or RepoSync |
configsync.sync.name |
The name of the RootSync or RepoSync that configures this reconciler |
configsync.sync.namespace |
The namespace of the RootSync or RepoSync that configures this reconciler |
Cloud Monitoring resource labels
Cloud Monitoring Resource labels are used for indexing metrics in storage, which means they have negligible effect on cardinality, unlike metric labels, where cardinality is a significant performance concern. See Monitored Resource Types for more information.
The k8s_container resource type sets the following resource labels to identify the source Container:
| Name | Description |
|---|---|
container_name |
The name of the Container |
pod_name |
The name of the Pod |
namespace_name |
The namespace of the Pod |
location |
The region or zone of the cluster hosting the node |
cluster_name |
The name of the cluster hosting the node |
project |
The ID of the project hosting the cluster |
Configure custom metric filtering
You can adjust the custom metrics that Config Sync exports to Prometheus, Cloud Monitoring, and Google's internal monitoring service. Adjust custom metrics to fine-tune the included metrics or configure different backends.
To modify custom metrics, create and then edit a ConfigMap named
otel-collector-custom. Using this ConfigMap ensures that Config Sync
doesn't revert any of the modifications that you make. If you modify the
otel-collector or otel-collector-google-cloud ConfigMaps, Config Sync
reverts any changes.
For examples of how to adjust this ConfigMap, see Custom Metric Filtering in the open source Config Sync documentation.
Understand the pipeline_error_observed metric
The pipeline_error_observed metric is a metric that can help you quickly identify
RepoSync or RootSync CRs that are not in sync or contain resources that are not
reconciled to the desired state.
For a successful sync by a RootSync or RepoSync, the metrics with all components (
rendering,source,sync,readiness) are observed with value 0.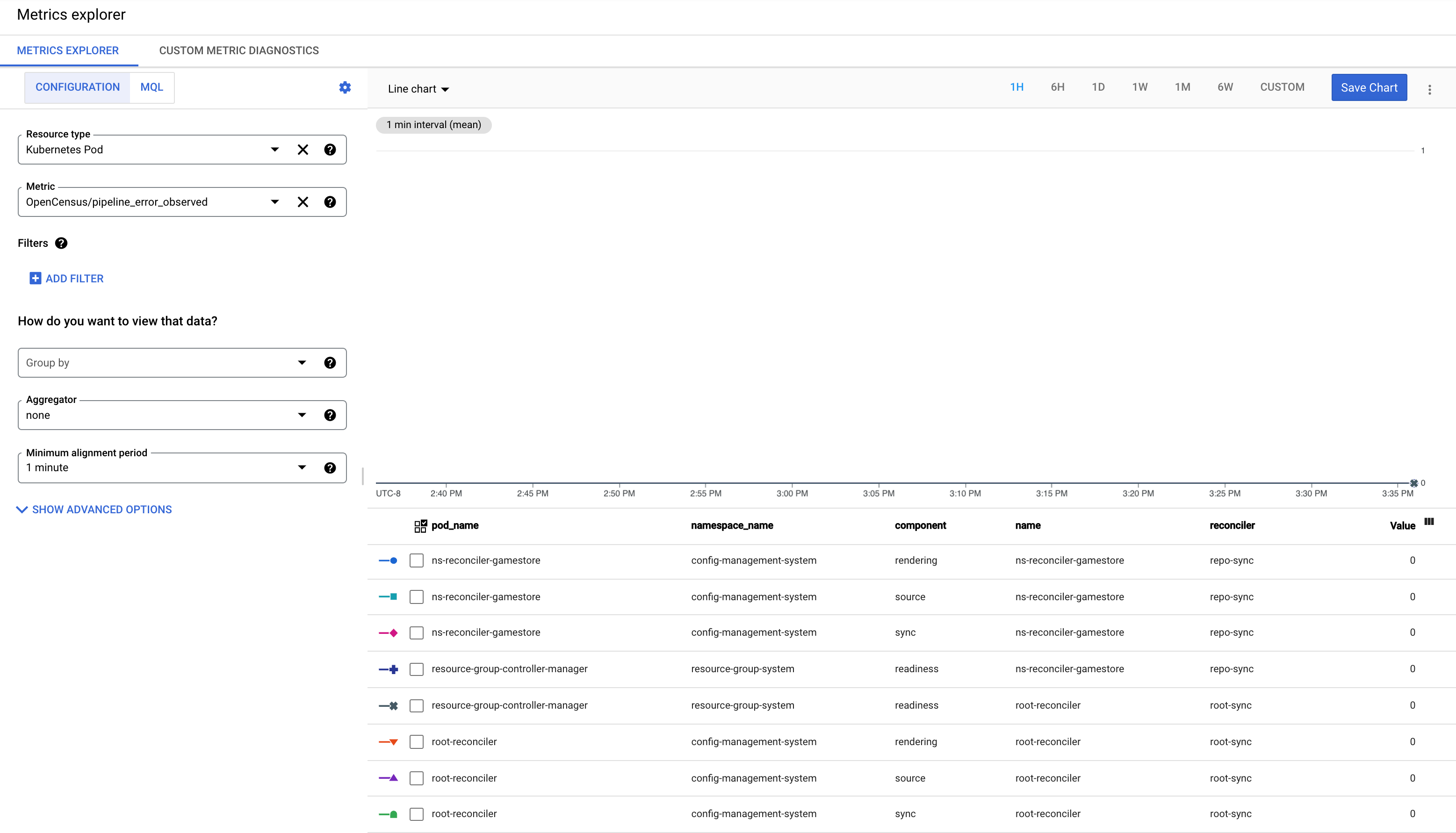
When the latest commit fails the automated rendering, the metric with the component
renderingis observed with value 1.When checking out the latest commit encounters error or the latest commit contains invalid configuration, the metric with the component
sourceis observed with value 1.When a resource fails to be applied to the cluster, the metric with the component
syncis observed with value 1.When a resource is applied, but fails to reach its desired state, the metric with the component
readinessis observed with value 1. For example, a Deployment is applied to the cluster, but the corresponding Pods are not created successfully.
What's next
- Learn more about how to monitor RootSync and RepoSync objects.
- Learn how to use the Config Sync SLIs.