AlloyDB Omni est un package logiciel de base de données téléchargeable qui vous permet de déployer une version simplifiée d'AlloyDB pour PostgreSQL dans votre propre environnement de calcul. AlloyDB Omni et le service AlloyDB pour PostgreSQL entièrement géré sur Google Cloud partagent les mêmes composants de base. AlloyDB pour PostgreSQL utilise une couche de stockage cloud native qui optimise les performances WAL, tandis qu'AlloyDB Omni utilise la même interface de système de fichiers standard que PostgreSQL.
La portabilité d'AlloyDB Omni vous permet de l'exécuter dans de nombreux environnements, y compris les suivants :
- Centres de données
- Ordinateurs portables
- Instances de VM dans le cloud
Cas d'utilisation d'AlloyDB Omni
AlloyDB Omni est particulièrement adapté aux scénarios suivants :
- Vous avez besoin d'une version évolutive et performante de PostgreSQL, mais vous ne pouvez pas exécuter de base de données dans le cloud en raison d'exigences réglementaires ou de souveraineté des données.
- Vous avez besoin d'une base de données qui continue de fonctionner même lorsqu'elle est déconnectée d'Internet.
- Pour minimiser la latence, vous devez placer votre base de données aussi près que possible de vos utilisateurs.
- Vous souhaitez migrer depuis une ancienne base de données, mais sans vous engager dans une migration complète vers le cloud.
AlloyDB Omni n'inclut pas les fonctionnalités d'AlloyDB pour PostgreSQL qui reposent sur le fonctionnement dans Google Cloud. Si vous souhaitez mettre à niveau votre projet pour profiter des fonctionnalités d'évolutivité, de sécurité et de disponibilité entièrement gérées d'AlloyDB pour PostgreSQL, vous pouvez migrer vos données AlloyDB Omni vers un cluster AlloyDB pour PostgreSQL, comme vous le feriez pour toute autre importation de données initiale.
Principales fonctionnalités
- Un serveur de base de données compatible avec PostgreSQL.
- Prise en charge d'AlloyDB AI, qui vous aide à créer des applications d'IA générative de niveau entreprise à l'aide de vos données opérationnelles.
- Intégrations avec l'écosystème d'IA Google Cloud , y compris Vertex AI Model Garden et les outils d'IA générative Open Source.
Prise en charge des fonctionnalités autopilot d'AlloyDB pour PostgreSQL dansGoogle Cloud . Cela permet à AlloyDB Omni de s'autogérer et de s'autorégler.
Par exemple, AlloyDB Omni est compatible avec la gestion automatique de la mémoire et l'autovacuum adaptatif des données obsolètes.
Un conseiller d'index qui analyse les requêtes fréquemment exécutées et recommande de nouveaux index pour améliorer les performances des requêtes.
Le moteur de données en colonnes AlloyDB Omni, qui stocke en mémoire les données fréquemment interrogées dans un format en colonnes. Il accélère les opérations sur l'informatique décisionnelle, la création de rapports, ainsi que le traitement les charges de travail de traitement transactionnel et analytique hybride (HTAP).
Nos tests de performances ont permis de démontrer que les charges de travail transactionnelles dans AlloyDB Omni sont plus de deux fois plus rapides et que les requêtes analytiques sont jusqu'à 100 fois plus rapides que dans PostgreSQL standard.
Fonctionnement d'AlloyDB Omni
Vous pouvez installer AlloyDB Omni en tant que serveur autonome ou dans un environnement Kubernetes.
AlloyDB Omni s'exécute dans un conteneur Docker que vous installez dans votre propre environnement. Nous vous recommandons d'exécuter AlloyDB Omni sur un système Linux avec un stockage SSD et au moins 8 Go de mémoire par processeur.
L'opérateur Kubernetes AlloyDB Omni est une extension de l'API Kubernetes qui vous permet d'exécuter AlloyDB Omni dans la plupart des environnements Kubernetes conformes à la norme CNCF. Pour en savoir plus, consultez Installer AlloyDB Omni sur Kubernetes.
Vos applications se connectent à votre installation AlloyDB Omni et communiquent avec elle, tout comme elles se connectent à un serveur de base de données PostgreSQL standard et communiquent avec lui. Le contrôle de l'accès des utilisateurs repose également sur les normes PostgreSQL.
Des journaux au moteur de données en colonnes en passant par le nettoyage, vous pouvez configurer le comportement de la base de données AlloyDB Omni à l'aide d'indicateurs de base de données.
Avantages de l'exécution d'AlloyDB Omni en tant que conteneur
Google distribue AlloyDB Omni sous la forme d'un conteneur que vous pouvez exécuter avec des environnements d'exécution de conteneur tels que Docker et Podman. D'un point de vue opérationnel, les conteneurs présentent les avantages suivants :
- Gestion transparente des dépendances : toutes les dépendances nécessaires sont regroupées dans le conteneur et testées par Google afin de garantir qu'elles sont entièrement compatibles avec AlloyDB Omni.
- Portabilité : vous pouvez vous attendre à ce qu'AlloyDB Omni fonctionne de manière cohérente dans tous les environnements.
- Isolation de sécurité : vous choisissez ce à quoi le conteneur AlloyDB Omni a accès sur la machine hôte.
- Gestion des ressources : vous pouvez définir la quantité de ressources de calcul que vous souhaitez rendre disponible pour le conteneur AlloyDB Omni.
- Mises à niveau et ajouts de correctifs simplifiés : pour appliquer un correctif à un conteneur, il vous suffit de remplacer l'image existante par une nouvelle.
Sauvegarde des données et reprise après sinistre
AlloyDB Omni dispose d'un système de sauvegarde et de récupération continues qui vous permet de créer un cluster de bases de données basé sur n'importe quel moment précis d'une période de conservation ajustable. Cela vous permet de récupérer rapidement vos données en cas de perte accidentelle.
De plus, AlloyDB Omni peut créer et stocker des sauvegardes complètes des données de votre cluster de bases de données, à la demande ou selon un calendrier régulier. À tout moment, vous pouvez restaurer dans un cluster de bases de données AlloyDB Omni une sauvegarde contenant toutes les données du cluster de bases de données d'origine (tel qu'il était au moment de la création de la sauvegarde).
Autre méthode de reprise après sinistre : vous pouvez obtenir une réplication entre centres de données en créant des clusters de bases de données secondaires dans des centres de données distincts. AlloyDB Omni diffuse de manière asynchrone les données d'un cluster de base de données principal désigné vers chacun de ses clusters secondaires. Si nécessaire, vous pouvez promouvoir un cluster de bases de données secondaire en cluster de bases de données AlloyDB Omni principal.
Composants de VM AlloyDB Omni
AlloyDB Omni sur VM se compose de deux ensembles de composants d'architecture : les composants PostgreSQL avec les améliorations AlloyDB pour PostgreSQL et les composants AlloyDB pour PostgreSQL. Le schéma suivant décrit les deux ensembles de composants, la couche d'infrastructure dans laquelle ils résident sur une VM ou un serveur, ainsi que les fonctionnalités associées auxquelles vous pouvez vous attendre pour chaque composant.
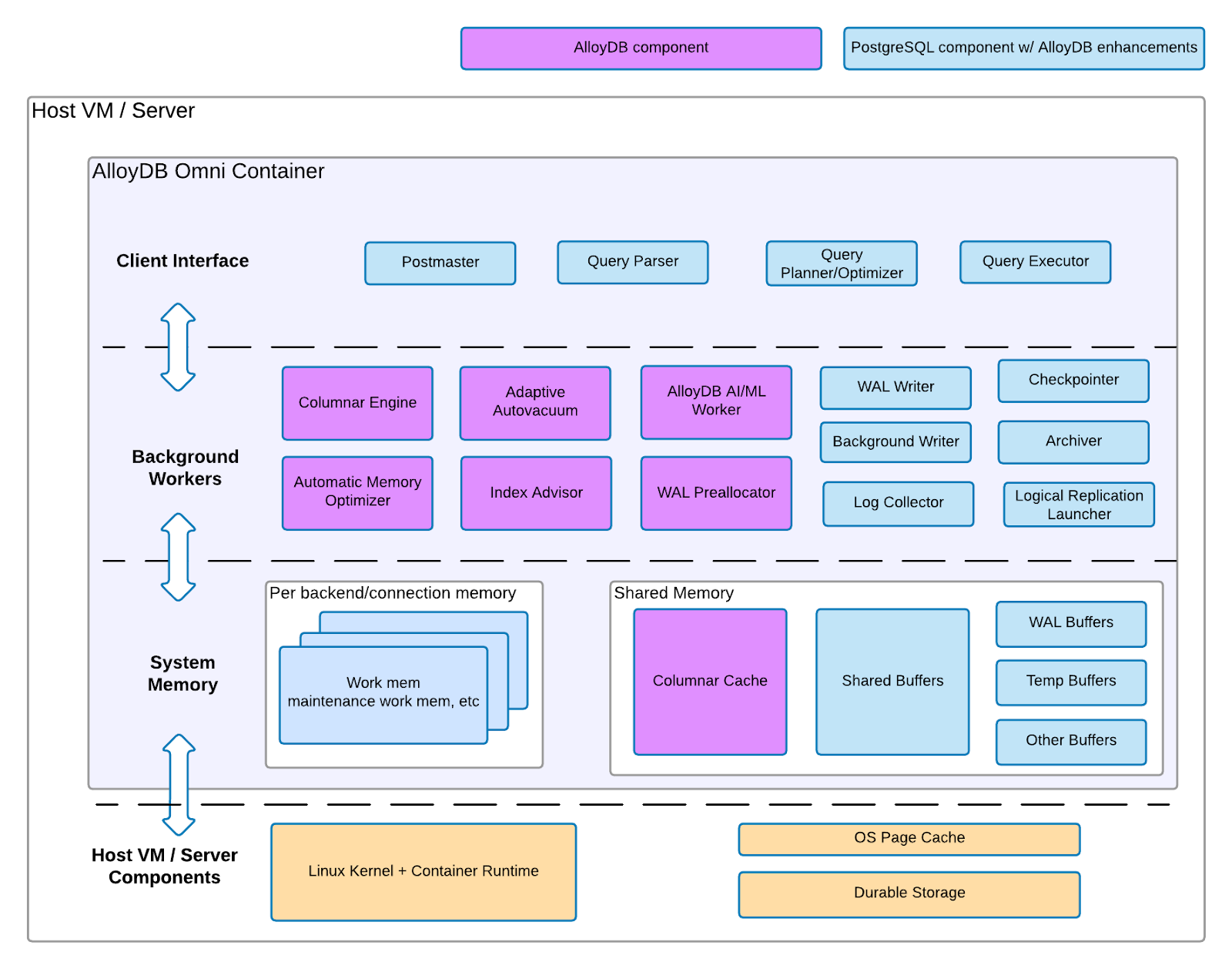
Figure 1 : Architecture d'AlloyDB Omni
Moteur de base de données
Ce document décrit l'architecture de base de données dans AlloyDB Omni au sein d'un conteneur. Dans ce document, nous partons du principe que vous connaissez bien PostgreSQL.
Un moteur de base de données effectue les tâches suivantes :
- Il traduit une requête d'un client en un plan exécutable.
- Il trouve les données nécessaires pour répondre à la requête.
- Il effectue les opérations de filtrage, de tri et d'agrégation nécessaires.
- Il renvoie les résultats au client.
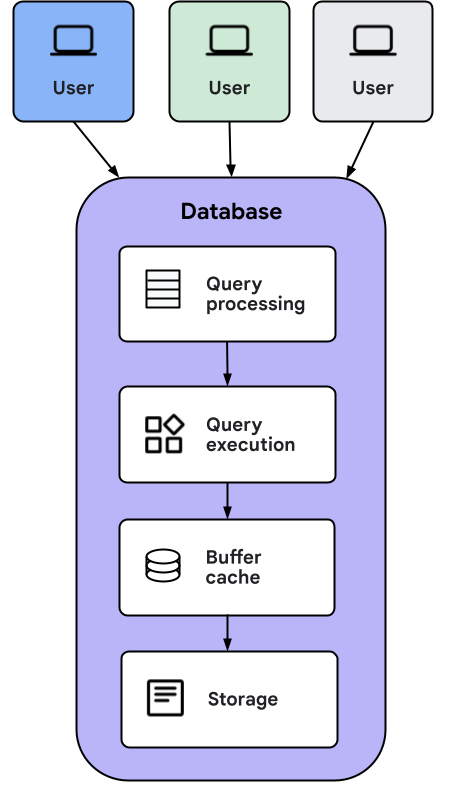
Lorsque l'application cliente envoie une requête à AlloyDB Omni, les opérations suivantes se produisent :
- La couche de traitement des requêtes convertit la requête en un plan d'exécution, lequel est transmis à la couche d'exécution des requêtes.
- La couche d'exécution des requêtes effectue les opérations nécessaires pour calculer la réponse à apporter à la requête.
- Lors de l'exécution, les données peuvent être chargées à partir du cache de mémoire tampon ou directement à partir du stockage. Si les données sont chargées à partir du stockage, elles sont stockées dans le cache pour une utilisation ultérieure.
Les ressources utilisées lors du traitement de la requête du client incluent le processeur, la mémoire, les E/S, le réseau et les primitives de synchronisation telles que les verrous de base de données. Le réglage des performances vise à optimiser l'utilisation des ressources à chaque étape de l'exécution des requêtes.
L'objectif d'un moteur de base de données performant est de répondre à une requête en utilisant le moins de ressources possible. Pour atteindre cet objectif, vous devez commencer par concevoir un modèle de données et des requêtes de qualité.
- Comment répondre aux requêtes en examinant le moins de données possible ?
- Quels index sont nécessaires pour réduire l'espace de recherche et les E/S ?
- Le tri des données nécessite l'accès au processeur et, souvent, l'accès au disque (pour les grands ensembles de données). Alors, comment éviter d'avoir à trier les données ?
Stockage de données
AlloyDB Omni stocke les données dans des pages de taille fixe qui sont stockées dans le système de fichiers sous-jacent. Lorsqu'une requête doit accéder à des données, AlloyDB Omni vérifie d'abord le pool de mémoire tampon. Si les pages contenant les données requises ne sont pas trouvées dans le pool de mémoire tampon, AlloyDB Omni lit les pages requises à partir du système de fichiers. L'accès aux données du pool de mémoire tampon est beaucoup plus rapide que la lecture à partir du système de fichiers. Il est donc important de maximiser la taille du pool de mémoire tampon pour la quantité de données à laquelle une application devra accéder.
Gestion des ressources
AlloyDB Omni utilise une gestion dynamique de la mémoire pour permettre au pool de mémoire tampon de croître et de diminuer de manière dynamique dans les limites configurées, en fonction des besoins en mémoire du système. Par conséquent, il n'est pas nécessaire d'ajuster la taille du pool de mémoire tampon. Lorsque vous diagnostiquez des problèmes de performances, les premières métriques à prendre en compte sont le taux de succès du pool de mémoire tampon et le taux de lecture. Vous devez déterminer si votre application bénéficie du pool de mémoire tampon. Si ce n'est pas le cas, cela signifie que l'ensemble de données de l'application ne tient pas dans le pool de mémoire tampon. Vous pouvez alors envisager un redimensionnement sur une machine de taille plus importante et offrant plus de mémoire.
Le processus de récupération, de filtrage, d'agrégation, de tri et de projection des données nécessite des ressources de processeur sur le serveur de base de données. Pour réduire la quantité de ressources de processeur requises pour ce processus, minimisez la quantité de données à manipuler. Surveillez l'utilisation du processeur sur le serveur de base de données pour vous assurer que l'utilisation à l'état stable est d'environ 70 %. Ce taux laisse suffisamment de marge sur le serveur pour les pics d'utilisation ou les changements dans les modèles d'accès dans le temps. Une utilisation proche de 100 % introduit une surcharge due à la planification des processus et au changement de contexte, ce qui peut créer des goulots d'étranglement dans d'autres parties du système. Une utilisation élevée du processeur est une autre métrique clé à utiliser pour prendre des décisions concernant les spécifications des machines.
Les opérations d'entrée/sortie par seconde (IOPS, Input/Output Operations Per Second) sont un facteur important des performances des applications de base de données. Elles correspondent au nombre d'opérations d'entrée ou de sortie par seconde que le dispositif de stockage sous-jacent peut fournir à la base de données. Pour éviter d'atteindre les limites d'IOPS du stockage de base de données, limitez le plus possible les lectures et les écritures dans le stockage en maximisant la quantité de données pouvant tenir dans le pool de mémoire tampon.
Moteur de données en colonnes
Le moteur de données en colonnes accélère le traitement des requêtes SQL pour les analyses, les jointures et les agrégations en fournissant les composants suivants :
Store orienté colonnes en mémoire : contient les données des tables et des vues matérialisées pour les colonnes sélectionnées dans un format orienté colonnes. Par défaut, le store orienté colonnes consomme 1 Go sur la mémoire disponible. Pour modifier la quantité de mémoire utilisable par le store orienté colonnes, définissez le paramètre
google_columnar_engine.memory_size_in_mbdans lepostgresql.confutilisé par votre instance AlloyDB Omni.Planificateur de requêtes et moteur d'exécution en colonnes : permettent d'utiliser le store orienté colonnes dans les requêtes.
Gestion automatique de la mémoire
Le module de gestion automatique de la mémoire surveille et optimise en continu la consommation de mémoire sur l'ensemble d'une instance AlloyDB Omni. Lorsque vous exécutez vos charges de travail, ce module ajuste la taille du cache de mémoire tampon partagé en fonction de la pression exercée sur la mémoire. Par défaut, le module de gestion automatique de la mémoire définit la limite supérieure à 80 % de la mémoire système et alloue 10 % de la mémoire système au cache de mémoire tampon partagé.
Pour modifier la limite supérieure de la taille du cache de mémoire tampon partagé, définissez le paramètre shared_buffers dans le postgresql.conf utilisé par votre instance AlloyDB Omni.
Autovacuum adaptatif
L'autovacuum adaptatif analyse les opérations en fonction de la charge de travail de la base de données et ajuste automatiquement la fréquence de nettoyage. Cet ajustement automatique permet à la base de données de fonctionner à son niveau de performances maximal, même lorsque la charge de travail change, sans interférence du processus de nettoyage.
L'autovacuum adaptatif utilise les facteurs suivants pour déterminer la fréquence et l'intensité des opérations de nettoyage :
- Taille de la base de données
- Nombre de tuples morts dans la base de données
- Ancienneté des données dans la base de données
- Nombre de transactions par seconde par rapport à la vitesse de nettoyage estimée
L'autovacuum adaptatif offre les avantages suivants :
- Gestion dynamique des ressources de nettoyage : au lieu d'utiliser une limite de coût fixe, AlloyDB Omni utilise des statistiques sur les ressources en temps réel pour ajuster le nombre de nœuds de calcul de nettoyage. Lorsque le système est occupé, le processus de nettoyage et l'utilisation de ressources associée sont limités. Si suffisamment de mémoire est disponible, de la mémoire supplémentaire est allouée à
maintenance_work_mempour réduire le temps de nettoyage de bout en bout. - Limitation dynamique des ID de transaction (XID) : surveille automatiquement et en continu la progression du nettoyage et la vitesse de consommation des ID de transaction. Si un risque de réinitialisation des ID de transaction est détecté, AlloyDB Omni ralentit les transactions pour limiter la consommation d'ID. De plus, AlloyDB Omni alloue davantage de ressources aux nœuds de calcul de nettoyage pour traiter les tables qui bloquent l'avancement et la libération de l'espace d'ID de transaction. Au cours de ce processus, le nombre global de transactions par seconde est réduit jusqu'à ce que les ID de transaction se trouvent dans une zone sécurisée (observable sous la forme de sessions en attente sur
AdaptiveVacuumNewXidDelay). Lorsque l'ancienneté des ID de transaction augmente, le nombre de nœuds de calcul de nettoyage est augmenté de manière dynamique. - Nettoyage efficace pour les tables plus volumineuses : la logique PostgreSQL par défaut utilisée pour déterminer quand nettoyer une table est basée sur des statistiques spécifiques à la table stockées dans
pg_stat_all_tables, qui contient le ratio de tuples morts. Cette logique fonctionne pour les petites tables, mais elle peut ne pas être efficace pour les tables plus volumineuses et fréquemment mises à jour. AlloyDB Omni fournit un mécanisme d'analyse mis à jour qui permet de déclencher plus souvent le nettoyage automatique. Ce mécanisme d'analyse examine des segments de grandes tables et supprime les tuples morts plus efficacement que la logique PostgreSQL par défaut. - Consigner les messages d'avertissement : dans AlloyDB Omni, les bloqueurs de vacuum, tels que les transactions de longue durée, les transactions préparées ou les emplacements de réplication qui perdent leurs cibles, sont détectés et des avertissements sont enregistrés dans les journaux PostgreSQL afin que vous puissiez résoudre les problèmes rapidement.
Nœud de calcul d'IA/de ML
Dans AlloyDB Omni, le nœud de calcul d'IA/de ML fonctionnant en arrière-plan fournit toutes les fonctionnalités nécessaires pour appeler les modèles Vertex AI directement depuis la base de données. Le nœud de calcul d'IA/de ML s'exécute sous la forme d'un processus appelé omni ml worker.
Étapes suivantes
- Choisissez un environnement de déploiement AlloyDB Omni.
- Faites vos premiers pas avec AlloyDB Omni pour Kubernetes.
- Premiers pas avec AlloyDB Omni pour les conteneurs