Ce document explique comment interpréter les résultats de performances dans AlloyDB Omni sur une VM. Dans ce document, nous partons du principe que vous connaissez PostgreSQL.
Lorsque vous représentez le débit au fil du temps lorsqu'une autre variable est modifiée, vous constatez généralement que le débit augmente jusqu'à atteindre un point d'épuisement des ressources.
La figure suivante montre un graphique de mise à l'échelle du débit type. À mesure que le nombre de clients augmente, la charge de travail et le débit augmentent jusqu'à ce que toutes les ressources soient épuisées.
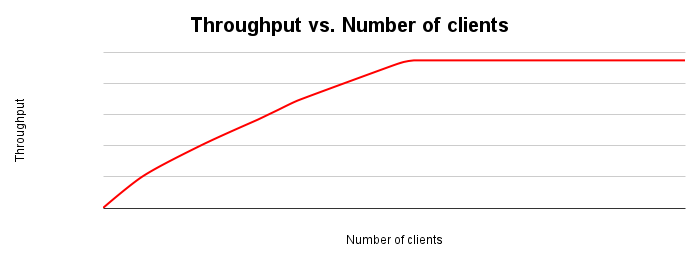
Idéalement, lorsque vous doublez la charge sur le système, le débit doit également doubler. En pratique, il y aura des conflits sur les ressources, ce qui entraînera une augmentation plus faible du débit. À un moment donné, l'épuisement ou le conflit de ressources entraînera une stabilisation ou une diminution du débit. Si vous optimisez pour le débit, il s'agit d'un point clé à identifier, car il vous indique où ajuster l'application ou le système de base de données pour améliorer le débit.
Voici quelques raisons courantes pour lesquelles le débit peut stagner ou baisser:
- Épuisement des ressources de processeur sur le serveur de base de données
- Épuisement des ressources de processeur sur le client, de sorte que le serveur de base de données ne reçoit plus de travail
- Contention de verrouillage de la base de données
- Durée d'attente des E/S lorsque les données dépassent la taille du pool de mémoire tampon Postgres
- Durée d'attente des E/S en raison de l'utilisation du moteur de stockage
- Goulots d'étranglement de la bande passante réseau renvoyant des données au client
La latence et le débit sont inversement proportionnels. À mesure que la latence augmente, le débit diminue. C'est intuitif. À mesure qu'un goulot d'étranglement commence à se matérialiser, les opérations prennent plus de temps et le système effectue moins d'opérations par seconde.
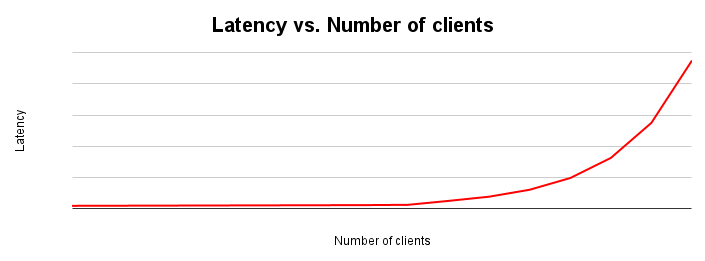
Le graphique de mise à l'échelle de la latence montre comment la latence change à mesure que la charge placée sur un système augmente. La latence reste relativement constante jusqu'à ce qu'un conflit se produise en raison d'un conflit de ressources. Le point d'inflexion de cette courbe correspond généralement à l'aplatissement de la courbe de débit dans le graphique de mise à l'échelle du débit.
Une autre façon utile d'évaluer la latence est de la représenter sous forme d'histogramme. Dans cette représentation, nous regroupons les latences dans des buckets et comptabilisons le nombre de requêtes incluses dans chaque bucket.
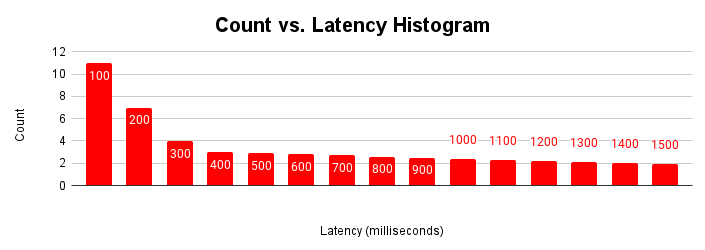
Cet histogramme de latence montre que la plupart des requêtes sont inférieures à 100 millisecondes et que les latences sont supérieures à 100 millisecondes. Comprendre la cause des requêtes avec une latence plus longue peut aider à expliquer les variations de performances de l'application. Les causes de la longue traîne des latences accrues correspondent aux latences accrues observées dans le graphique de mise à l'échelle de la latence typique et à l'aplatissement du graphique du débit.
L'histogramme de latence est particulièrement utile lorsqu'une application comporte plusieurs modalités. Une modalité est un ensemble normal de conditions de fonctionnement. Par exemple, la plupart du temps, l'application accède aux pages qui se trouvent dans le cache tampon. La plupart du temps, l'application met à jour des lignes existantes. Toutefois, il peut exister plusieurs modes. Parfois, l'application récupère des pages à partir de l'espace de stockage, insère de nouvelles lignes ou rencontre un conflit de verrouillage.
Lorsqu'une application rencontre ces différents modes de fonctionnement au fil du temps, l'histogramme de latence affiche ces différentes modalités.
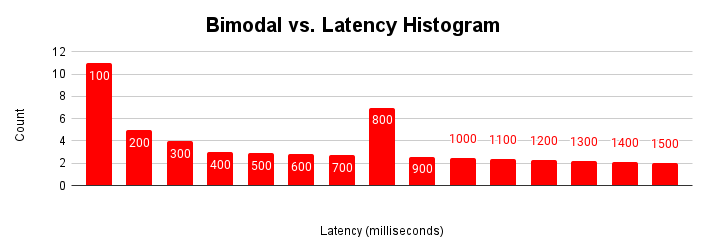
Cette figure montre un histogramme bimodal typique, dans lequel la plupart des requêtes sont traitées en moins de 100 millisecondes, mais un autre groupe de requêtes prend entre 401 et 500 millisecondes. Comprendre la cause de cette seconde modalité peut vous aider à améliorer les performances de votre application. Il peut également y avoir plus de deux modalités.
La seconde modalité peut être due à des opérations de base de données normales, à une infrastructure et une topologie hétérogènes ou au comportement de l'application. Voici quelques exemples à prendre en compte:
- La plupart des accès aux données proviennent du pool de tampons PostgreSQL, mais certains proviennent du stockage.
- Différences de latence réseau entre certains clients et le serveur de base de données
- Logique d'application qui effectue différentes opérations en fonction de l'entrée ou de l'heure de la journée
- Conflits de verrouillage occasionnels
- Pics d'activité des clients