ユースケース
この可用性リファレンス アーキテクチャは、次のユースケースに適しています。
- RTO と RPO の短縮が求められるビジネス クリティカルなアプリケーション。
- データベースの高可用性を実現し、インスタンス、サーバー、ゾーンの障害から保護するレプリカを別のゾーンまたはノードにデプロイする。
- ユーザーエラーやデータ破損から保護する(バックアップを使用)。
リファレンス アーキテクチャの仕組み
Enhanced 可用性は、リージョン内に読み取り専用レプリカ インスタンスを追加して高可用性(HA)を有効にし、目標復旧時間(RTO)を短縮することで、Standard 可用性を強化します。このアプローチでは、トランザクションの変更をレプリカにストリーミングできるため、目標復旧時点(RPO)も短縮されます。
AlloyDB Omni の高可用性では、少なくとも 2 つのデータベース インスタンスが使用されます。1 つのインスタンスがプライマリ データベースとして機能し、読み取り / 書き込みオペレーションをサポートします。残りのインスタンスは、読み取り専用モードで動作するリードレプリカとして機能します。
HA の重要なコンセプトは次のとおりです。
- フェイルオーバーは、プライマリ インスタンスが障害または使用不可になり、スタンバイ レプリカがアクティブになってプライマリ(読み取り / 書き込み)モードになる、計画外の停止時の手順です。このプロセスは「プロモーション」と呼ばれます。通常、このようなシナリオでは、プライマリ サーバーまたはデータベースがオンラインに戻ったときに、データベースを再構築してスタンバイとして機能させる必要があります。稼働時間を長くするために、フェイルオーバーを自動化するメカニズムが導入されています。
- スイッチオーバー(ロールの取り消しとも呼ばれます)は、プライマリ データベースとスタンバイ データベースの 1 つの間でモードを切り替えるために使用される手順です。プライマリがスタンバイになり、スタンバイがプライマリになります。通常、切り替えは制御された正常な方法で行われます。切り替えは、ダウンタイムを許容して以前のプライマリ データベースのパッチ適用を行うなど、さまざまな理由で開始できます。正常な切り替えでは、新しいスタンバイやレプリケーション構成のその他の側面を再インスタンス化することなく、将来の切り戻しを可能にする必要があります。
高可用性のオプション
HA をサポートするために、AlloyDB Omni は次の方法でデプロイできます。
- AlloyDB Omni Kubernetes 演算子を使用する Kubernetes 環境。詳細については、Kubernetes で高可用性を管理するをご覧ください。
- Kubernetes 以外のデプロイに適した Patroni と HAProxy を使用します。詳細については、AlloyDB Omni for PostgreSQL の高可用性アーキテクチャをご覧ください。
| 注: Patroni と HAProxy は、非商用のサードパーティ ツールであり、AlloyDB Omni と互換性があります。 |
|---|
1 つのデータベースが失われてもクラスタの高可用性に影響しないように、少なくとも 2 つのスタンバイ データベースを用意することをおすすめします。このモードでは、フェイルオーバー時やノードの計画メンテナンス中に、少なくとも 1 つの HA ペアが存在します。
AlloyDB Omni Deployment のサイズと形状を計画するには、VM への AlloyDB Omni のインストールを計画するをご覧ください。
ロードバランサ
スムーズな切り替えとフェイルオーバーの手順を支援するもう一つの重要なメカニズムは、ロードバランサの存在です。Kubernetes 以外のデプロイでは、HAProxy ソフトウェアがロード バランシングを提供します。HAProxy は、ネットワーク トラフィックを複数のサーバーに分散することでロード バランシングを提供します。また、HAProxy はヘルスチェックを実行して、接続するバックエンド サーバーを健全な状態に維持します。サーバーがヘルスチェックに失敗すると、HAProxy は、サーバーが再びヘルスチェックに合格するまで、そのサーバーへのトラフィックの送信が停止します。
Kubernetes 演算子は、同様の動作をする独自のロードバランサをデプロイし、ロードバランサを指すデータベースのサービスを作成して、ユーザーに対して透過的にします。
高可用性
リージョン内にデプロイされたリードレプリカ データベースは、プライマリ データベースに障害が発生した場合に高可用性を提供します。プライマリ データベースで障害が発生すると、スタンバイ データベースがプライマリ データベースに代わってプロモートされ、アプリケーションはほとんどまたはまったく停止することなく続行されます。
通常、これらのデータベースに依存するすべてのアプリケーションが適切な時間枠内で接続して応答できるように、切り替えの形で定期的に年 1 回または半年に 1 回のチェックを行うことをおすすめします。
ゾーンレベルの保護は、プライマリ データベースとは異なるアベイラビリティ ゾーンにスタンバイ リードレプリカの 1 つを配置することで、どちらのデプロイタイプでも実現できます。
リードレプリカを使用するもう 1 つのメリットは、読み取り専用オペレーションをスタンバイ データベースにオフロードできることです。スタンバイ データベースは、最新のデータを使用してレポート データベースとして機能できます。このアプローチにより、読み取り / 書き込みプライマリの負荷とオーバーヘッドが軽減されます。
バックアップと高可用性構成
リードレプリカは、高可用性を提供する複数のゾーンに設定できます。RTO と RPO は短縮されますが、論理データの破損(テーブルの誤削除やデータの誤更新など)などの特定の停止から保護することはできません。そのため、HA 設定に加えて定期的なバックアップを行う必要があります。詳細については、Standard 可用性アーキテクチャのドキュメントをご覧ください。
図 1 は、2 つの異なるアベイラビリティ ゾーンに 2 つの読み取りレプリカ スタンバイ データベースがある推奨の HA 構成を示しています。
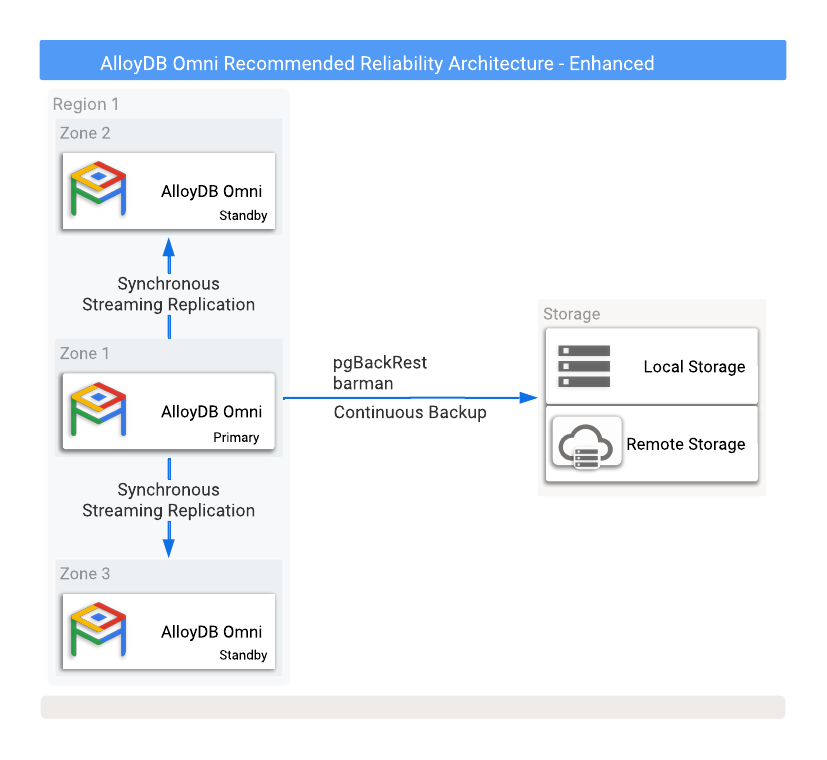
図 1: バックアップと高可用性オプションを備えた AlloyDB Omni。
プライマリ インスタンスで障害が発生した場合のデータ損失を防ぐには、同期モードでレプリケーションを構成する必要があります。この方法では、データ保護は強化されますが、すべての commit をプライマリ データベースとすべての同期スタンバイ データベースの両方に書き込む必要があるため、プライマリ データベースのパフォーマンスに影響する可能性があります。この設定では、これらのデータベース インスタンス間の低レイテンシのネットワーク接続が不可欠です。
Kubernetes HA デプロイ
Kubernetes deployment の場合、AlloyDB Omni デプロイ ファイルにいくつかの基本的な属性の変更と追加を行うことで、フェイルオーバー スタンバイまたは読み取りレプリカを追加して、プライマリ データベースの障害に対応できます。フェイルオーバー スタンバイと読み取り専用レプリカを構成できます。演算子は、サービスのプロビジョニングと公開を行います。また、演算子は、フェイルオーバー後のスタンバイ データベースの再構築や、AlloyDB Omni Kubernetes エンジンに組み込まれた修復メカニズムの使用など、多くの HA プロセスを自動化します。
Kubernetes deployment では、ノードと Pod の障害を処理する組み込みの Kubernetes 機能により、インフラストラクチャとアプリケーションの可用性が向上します。たとえば、次のような機能があります。
- kube-controller-manager
node-status-update-frequency、node-monitor-period、node-monitor-grace-period、pod-eviction-timeout.などのパラメータ
演算子は、組み込みの保護に加えて、障害が発生したプライマリまたはスタンバイの検出に影響を与える次のパラメータを公開します。
healthcheckPeriodSeconds: ヘルスチェックの間隔(デフォルトは 30 秒)autoFailoverTriggerThreshold: フェイルオーバーを開始するまでのヘルスチェックの連続失敗回数。デフォルトは 3 です。
詳細については、Kubernetes で高可用性を管理するをご覧ください。
Kubernetes HA 以外のデプロイ
スタンドアロンの Kubernetes deployment 以外は手動構成であり、Kubernetes deployment よりも設定とメンテナンスが複雑なサードパーティ ツールが必要です。
Kubernetes deployment 以外を使用する場合、フェイルオーバーの検出方法と、プライマリが使用できなくなってからフェイルオーバーが発生するまでの時間に影響するパラメータがあります。これらのパラメータの概要は次のとおりです。
Ttl: フェイルオーバーを開始する前に、プライマリ データベースのロックを取得するのにかかる最大時間。デフォルト値は 30 秒です。Loop_wait: 再チェックするまでの待機時間。デフォルト値は 10 秒です。Retry_timeout: ネットワーク障害によりプライマリ インスタンスを降格するまでのタイムアウト。デフォルト値は 10 秒です。
詳細については、AlloyDB Omni for PostgreSQL の高可用性アーキテクチャをご覧ください。
実装
可用性リファレンス アーキテクチャを選択する場合は、次のメリット、制限事項、別の方法を考慮してください。
利点
- インスタンス障害から保護します。
- サーバー障害から保護します。
- ゾーン障害から保護します。
- RTO が Standard 可用性から大幅に短縮されます。
制限事項
- リージョン障害に対する追加の保護はありません。
- 同期レプリケーションによるプライマリのパフォーマンスへの影響の可能性。
- 同期モードで PostgreSQL WAL ストリーミングを構成すると、通常のオペレーションまたは一般的なフェイルオーバーでデータ損失(
RPO=0)が発生しません。ただし、このアプローチでは、すべてのスタンバイ インスタンスが失われる場合やプライマリから到達不能になる場合に、その直後にプライマリが再起動されるなど、特定の二重障害の状況でのデータ損失を防ぐことはできません。
別の方法
- バックアップと復元オプションの Standard 可用性アーキテクチャ。
- リージョン レベルの障害復旧、追加のリードレプリカ、障害復旧範囲の拡大のための Premium 可用性アーキテクチャ。
次のステップ
- AlloyDB Omni 可用性リファレンス アーキテクチャの概要。
- AlloyDB Omni Standard 可用性。
- AlloyDB Omni Premium 可用性。
- VM への AlloyDB Omni のインストールを計画する
- AlloyDB Omni for PostgreSQL の高可用性アーキテクチャ。
- Kubernetes で高可用性を管理する