ユースケース
このリファレンス アーキテクチャは、次のシナリオをサポートしています。
- 対象のデータベースで、多少のダウンタイムと前回のバックアップ以降のデータ損失を許容できる。
- AlloyDB Omni データベースを(サーバーまたは VM イメージのスナップショットではなく)データベース レベルのユーザーエラー、破損、物理障害から保護する。
- データベースを(たとえば特定の時点まで遡って)インプレースまたはリモートで復元できるようにする。
リファレンス アーキテクチャの仕組み
Standard Availability リファレンス アーキテクチャは、AlloyDB Omni データベースのバックアップと復元を対象としています。その AlloyDB Omni データベースが、ホストサーバー上のスタンドアロン インスタンスとして実行されているか、仮想マシンとして実行されているか(AlloyDB Omni をインストールする)、Kubernetes クラスタで実行されているか(Kubernetes に AlloyDB Omni をインストールする)は問いません。
Standard Availability は基本的な実装であり、必要な追加のハードウェアやサービスを最小限に抑えますが、データベースが大きくなるにつれて目標復旧時間(RTO)が増加します。バックアップするデータが多いほど、データベースの復元に時間がかかります。データ損失はバックアップのタイプによって異なります。データファイルのみが定期的にバックアップされる場合、復元時に前回のバックアップ以降のデータが失われます。
RPO の低減
PostgreSQL の継続的アーカイブ機能を使用すると、目標復旧時点(RPO)を低減し、バックアップによるポイントインタイム リカバリを有効にできます。このプロセスでは、write-ahead log 書き込み(WAL)ファイルのアーカイブと WAL データのストリーミング(リモート ストレージ ロケーションへのストリーミングなど)が行われます。
WAL ファイルがフル バックアップ時または特定の間隔でのみアーカイブされる場合、データベース全体(現在の WAL ファイルを含む)が失われると、復元は最後にアーカイブされた WAL ファイルに制限されます。つまり、目標復旧時点(RPO)では、データ損失の可能性を考慮する必要があります。一方、継続的な WAL データ転送では、データ損失を最小限に抑えることができます。
継続的バックアップを行う場合は、ポイントインタイム リカバリを実行できます。ポイントインタイム リカバリでは、テーブルの偶発的な削除やバッチ アップデートの誤りなどのエラーが発生する前の状態に復元できます。ただし、この復元方法では、一時的な補助データベースを使用しない限り、目標復旧時点(RPO)に影響します。
バックアップ戦略
AlloyDB Omni Postgres レベルのバックアップは、ローカル ストレージまたはリモート ストレージに保存するように構成できます。ローカル ストレージの方がバックアップと復元は高速ですが、ホストまたは VM 全体の障害が発生した場合の障害対応は通常、リモート ストレージの方が堅牢です。
Kubernetes 以外でのバックアップ
Kubernetes 以外のデプロイメントの場合は、次の PostgreSQL ツールを使用してバックアップをスケジュールできます。
- pgBackRest。詳細については、AlloyDB Omni 用に pgBackRest を設定するをご覧ください。
- Barman。詳細については、AlloyDB Omni 用に Barman を設定するをご覧ください。
または、小規模なデータベースの場合は、データベースの論理バックアップを実行することもできます(単一のデータベースの場合は pg_dump、クラスタ全体の場合は pg_dumpall を使用)。復元には pg_restore を使用できます。
AlloyDB Omni Operator を使用した Kubernetes でのバックアップ
Kubernetes クラスタにデプロイされた AlloyDB Omni の場合、データベース クラスタごとにバックアップ プランを使用して継続的バックアップを構成できます。詳細については、Kubernetes でのバックアップと復元をご覧ください。
AlloyDB Omni バックアップは、ローカルまたはリモート(Cloud Storage)に保存できます。これには、任意のクラウド ベンダーが提供するオプションも含まれます。詳細については、バックアップ先の候補を示す図 1 をご覧ください。
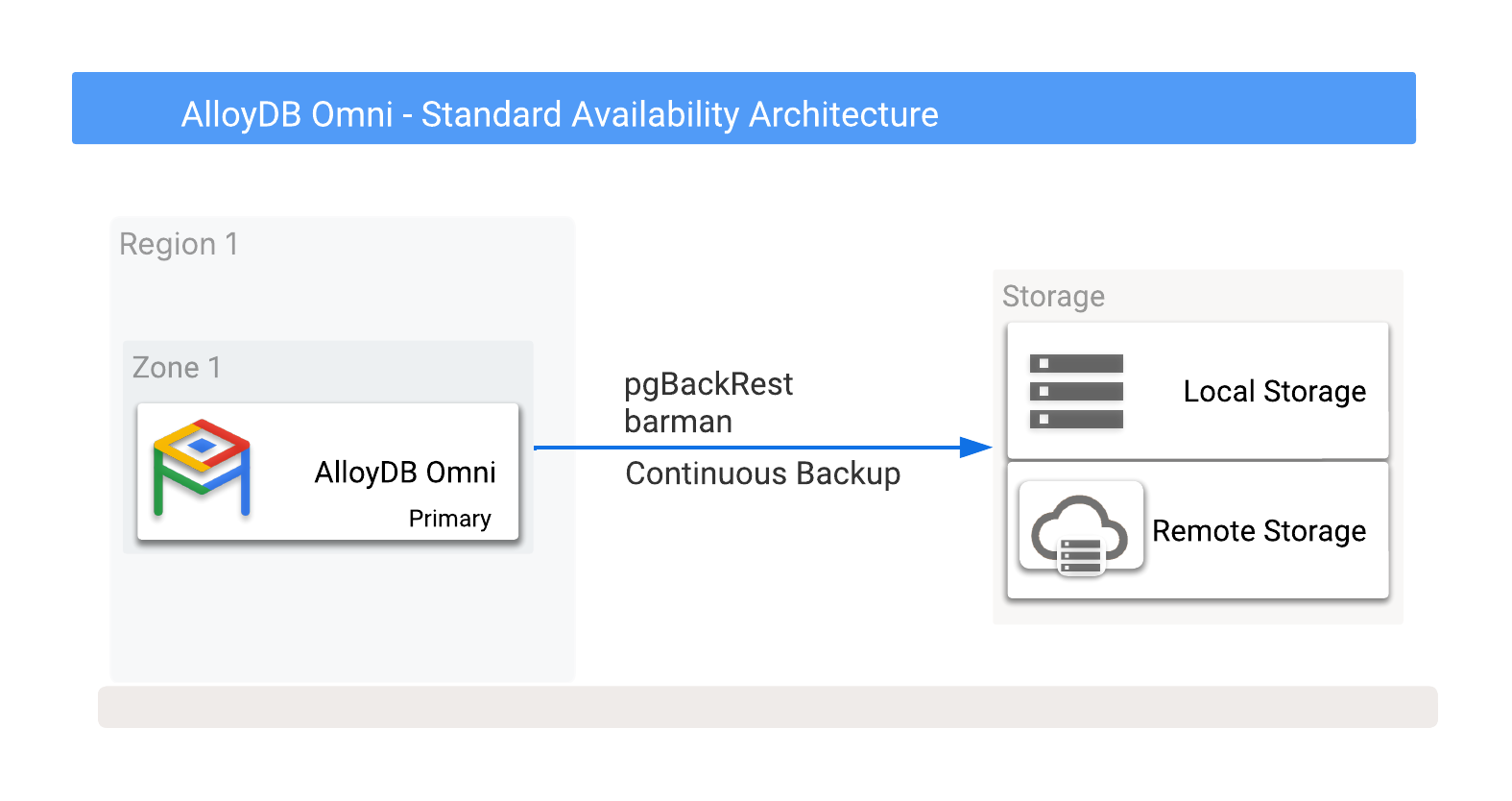
図 1. AlloyDB Omni とバックアップ オプション
バックアップは、ローカル ストレージ オプションまたはリモート ストレージ オプションのいずれかに作成できます。ローカル バックアップは I/O スループットのみに依存するため、通常は高速です。一方、リモート バックアップは通常、レイテンシが高く、ネットワーク帯域幅が低くなります。ただし、リモート バックアップは、最適な保護(ゾーン障害に対する保護を含む)を提供します。
ローカル バックアップをローカル ストレージまたは共有ストレージに分割することもできます。ローカル ストレージ オプションは、データベース ホストで障害が発生した場合に障害復旧オプションがないと影響を受けますが、共有ストレージでは、そのストレージを別のサーバーに再配置して復元に使用できます。つまり、共有ストレージでは RTO を短縮できる可能性があります。
ローカル ストレージと共有ストレージのデプロイメントでは、次のタイプのバックアップをスケジュールするか、オンデマンドで手動で作成できます。
- フル バックアップ: データ復元に必要なすべてのデータベース ファイルの完全バックアップ。
- 差分バックアップ: 前回のフル バックアップ以降のファイル変更のみのバックアップ。
- 増分バックアップ: 前回のバックアップ(種類を問わない)以降のファイル変更のみのバックアップ。
ポイントインタイム リカバリ
PostgreSQL の write-ahead log 書き込み(WAL)ファイルの継続的バックアップは、ポイントインタイム リカバリをサポートしています。障害イベントの後に WAL ファイルが破損しておらず使用可能な状態であれば、これらのファイルを使用してデータ損失なく復元できます。
WAL ファイルの書き込みを制御するには、次のパラメータを構成します。
| パラメータ | 説明 |
|---|---|
|
WAL writer が WAL をディスクにフラッシュする頻度を指定します。ただし、非同期で commit するトランザクションによって書き込みが指定した頻度よりも早く起動される場合があります。デフォルト値は 200 ミリ秒です。この値を大きくすると、書き込みの頻度は減りますが、サーバーがクラッシュした場合に失われるデータ量が増える可能性があります。 |
|
WAL writer がディスクへのフラッシュを強制する前に蓄積できる WAL データの量を指定します。デフォルト値は 1 MB です。0 に設定すると、WAL データは常にすぐディスクにフラッシュされます。 |
|
WAL データがディスクにフラッシュされる前に、commit がユーザーにレスポンスを返すかどうかを指定します。デフォルトの設定は on で、トランザクションの永続性が確保されます。つまり、commit がディスクに書き込まれてから、ユーザーに成功コードを返します。off に設定した場合、トランザクションがディスクに書き込まれるまでに最大 3 回の wal_writer_delay が発生します。 |
WAL の使用状況のモニタリング
次の方法で WAL の使用状況を確認できます。
| 確認方法 | 説明 |
|---|---|
|
この標準ビューには、WAL の書き込み数と WAL の同期数を保存する wal_write 列と wal_sync 列があります。構成パラメータ track_wal_io_timing が有効になっている場合、wal_write_time と wal_sync_time も保存されます。このビューの定期的なスナップショットにより、一定期間にわたる WAL の書き込みと同期のアクティビティを表示できます。 |
pg_current_wal_lsn() |
この関数は現在のログシーケンス番号(lsn)の位置を返します。この位置をタイムスタンプに関連付けて、一定期間にわたってスナップショットとして収集すると、関数 pg_wal_lsn_diff(lsn1, lsn2) を使用して生成された WAL のバイト/秒を取得できます。この関数は、トランザクション レートと WAL ファイルのパフォーマンスを把握するうえで役立つ指標です。 |
リモート ロケーションへの WAL データのストリーミング
Barman を使用すると、WAL データをリモート ロケーションにリアルタイムでストリーミングするように設定して、復元時のデータ損失を最小限に抑えることもできます。リアルタイムでストリーミングが行われても、リモート Barman サーバーへのストリーミング書き込みはデフォルトで非同期であるため、commit されたトランザクションが失われる可能性は多少あります。ただし、WAL を保存してステータス レスポンスをソース データベースに送信する同期モードを使用して WAL ストリーミングを設定することは可能です。このアプローチでは、トランザクションを継続する前にこの書き込みの完了を待つ必要がある場合、トランザクションが遅くなる可能性があることに注意してください。
バックアップ スケジュール
ほとんどの環境では、バックアップは通常、週単位でスケジュールされます。一般的な週次バックアップ スケジュールは次のとおりです。
- 日曜日: フル バックアップ
- 月曜日、火曜日: バックアップ
- 水曜日: 差分バックアップ
- 木曜日、金曜日: 増分バックアップ
- 土曜日: 差分バックアップ
この一般的なスケジュールを使用すると、1 週間のローリング復元ウィンドウでは、最大 3 回のフル バックアップに加えて、必要な増分バックアップまたは差分バックアップを保存するためのストレージ容量が必要になります。このアプローチは、日曜日のフル バックアップ中に障害が発生し、そのバックアップが開始される前週の日曜日の時点までデータベースの復元を延長する必要がある場合をサポートします。
RPO が大きくなる可能性があっても RTO を最小限に抑えるには、追加のデータベースを継続的リカバリモードで動作させます。これには、バックアップの再生と、新しい WAL ファイルのアーカイブと再生によるセカンダリ環境の継続的な更新が含まれます。潜在的なデータ損失を反映する実際の RPO は、トランザクションの頻度、WAL ファイルのサイズ、WAL ストリーミングの使用によって異なります。
Kubernetes 以外での復元
Kubernetes 以外のデプロイメントの場合、AlloyDB Omni データベースを復元するには、Docker コンテナを停止してからデータを復元するか、別のロケーションにデータを復元して、その復元されたデータを使用して新しい Docker インスタンスを起動します。コンテナが再起動すると、復元されたデータでデータベースにアクセスできるようになります。
復元オプションの詳細については、pgBackRest を使用して AlloyDB Omni クラスタを復元すると Barman を使用して AlloyDB Omni クラスタを復元するをご覧ください。
Operator を使用した Kubernetes での復元
Kubernetes でデータベースを復元するために、Operator は、名前付きバックアップまたはポイントインタイム(PIT)のクローンから、同じ Kubernetes クラスタと Namespace への復元を提供します。別の Kubernetes クラスタにデータベースのクローンを作成するには、pgBackRest を使用します。詳細については、Kubernetes でのバックアップと復元と Kubernetes バックアップからデータベース クラスタのクローンを作成する方法の概要をご覧ください。
実装
可用性リファレンス アーキテクチャを選択する場合は、以下の利点、制限事項、別の方法を考慮してください。
利点
- 使用と管理が簡単で、RTO / RPO が緩やかなクリティカルではないデータベースに適しています。
- 追加のハードウェアは最小限で済みます。
- 完全な障害復旧計画には常にバックアップが必要です。
- 復元ウィンドウ内の任意の時点に復元できます。
制限事項
- 保持要件によっては、ストレージ要件がデータベース自体よりも大きくなる可能性があります。
- 復元に時間がかかり、RTO が長くなる可能性があります。
- データベース障害後の現在の WAL データの可用性によっては、一部のデータが失われる可能性があり、RPO に悪影響を及ぼす可能性があります。
別の方法
次のステップ
- AlloyDB Omni 可用性リファレンス アーキテクチャの概要。
- AlloyDB Omni Enhanced Availability。
- AlloyDB Omni Premium Availability。
- Kubernetes に AlloyDB Omni をインストールする。
- AlloyDB Omni 用に pgBackRest を設定する。
- AlloyDB Omni 用に Barman を設定する。
- Kubernetes でのバックアップと復元。
- pgBackRest を使用して AlloyDB Omni クラスタを復元する。
- Barman を使用して AlloyDB Omni クラスタを復元する。
- Kubernetes でのバックアップと復元。
- Kubernetes バックアップからデータベース クラスタのクローンを作成する方法の概要。