Anwendungsfälle
Diese Referenzarchitektur unterstützt die folgenden Szenarien:
- Sie haben Datenbanken, die eine gewisse Ausfallzeit und einen gewissen Datenverlust seit der letzten Sicherung tolerieren können.
- Sie möchten Ihre AlloyDB Omni-Datenbank vor Benutzerfehlern, Beschädigungen oder physischen Fehlern auf Datenbankebene schützen (im Gegensatz zu Server- oder VM-Image-Snapshots).
- Sie möchten Ihre Datenbank lokal oder remote wiederherstellen können, möglicherweise bis zu einem bestimmten Zeitpunkt.
Funktionsweise der Referenzarchitektur
Die Referenzarchitektur für Standardverfügbarkeit deckt die Sicherung und Wiederherstellung Ihrer AlloyDB Omni-Datenbanken ab, unabhängig davon, ob sie als eigenständige Instanz auf einem Hostserver, als virtuelle Maschine (AlloyDB Omni installieren) oder in einem Kubernetes-Cluster (AlloyDB Omni in Kubernetes installieren) ausgeführt werden.
Die Standardverfügbarkeit ist eine einfache Implementierung, die zusätzliche Hardware oder Dienste minimiert. Das Wiederherstellungsziel (Recovery Time Objective, RTO) steigt jedoch mit zunehmender Größe der Datenbank. Je mehr Daten gesichert werden müssen, desto länger dauert es, die Datenbank wiederherzustellen. Der Datenverlust hängt vom Typ der Sicherung ab. Wenn nur Datendateien regelmäßig gesichert werden, kommt es bei der Wiederherstellung zu Datenverlusten seit der letzten Sicherung.
RPO reduzieren
Mit der Funktion Kontinuierliche Archivierung von PostgreSQL können Sie ein niedriges Recovery Point Objective (RPO) erreichen und die Wiederherstellung zu einem bestimmten Zeitpunkt über Sicherungen ermöglichen. Dabei werden Write-Ahead Logging-Dateien (WAL) archiviert und WAL-Daten werden gestreamt, möglicherweise an einen Remote-Speicherort.
Wenn WAL-Dateien nur archiviert werden, wenn sie voll sind oder in bestimmten Intervallen, beschränkt ein vollständiger Datenbankverlust (einschließlich der aktuellen WAL-Dateien) die Wiederherstellung auf die letzte archivierte WAL-Datei. Das bedeutet, dass das Recovery Point Objective (RPO) einen potenziellen Datenverlust berücksichtigen muss. Umgekehrt maximiert die kontinuierliche WAL-Datenübertragung das Risiko eines Datenverlusts.
Wenn Sie kontinuierliche Sicherungen durchführen, können Sie eine Wiederherstellung zu einem bestimmten Zeitpunkt ausführen. Durch die Wiederherstellung zu einem bestimmten Zeitpunkt können Sie den Zustand vor einem Fehler wiederherstellen, z. B. vor dem versehentlichen Löschen einer Tabelle oder vor falschen Batch-Updates. Diese Wiederherstellungsmethode wirkt sich jedoch auf das Recovery Point Objective (RPO) aus, sofern keine temporäre Hilfsdatenbank verwendet wird.
Sicherungsstrategien
Sie können AlloyDB Omni-Sicherungen auf Postgres-Ebene so konfigurieren, dass sie entweder im lokalen oder im Remote-Speicher gespeichert werden. Lokaler Speicher ist zwar möglicherweise schneller zu sichern und wiederherzustellen, aber Remotespeicher ist in der Regel robuster, wenn ein ganzer Host oder eine ganze VM ausfällt.
Sicherungen in Nicht-Kubernetes-Umgebungen
Bei Bereitstellungen, die nicht auf Kubernetes basieren, können Sie Sicherungen mit den folgenden PostgreSQL-Tools planen:
- pgBackRest Weitere Informationen finden Sie unter pgBackRest für AlloyDB Omni einrichten.
- Barman. Weitere Informationen finden Sie unter Barman für AlloyDB Omni einrichten.
Alternativ können Sie für kleine Datenbanken eine logische Sicherung der Datenbank durchführen (mit pg_dump für eine einzelne Datenbank oder pg_dumpall für den gesamten Cluster). Sie können die Daten mit pg_restore wiederherstellen.
Backups in Kubernetes mit dem AlloyDB Omni-Operator
Für AlloyDB Omni, das in einem Kubernetes-Cluster bereitgestellt wird, können Sie kontinuierliche Sicherungen mit einem Sicherungsplan für jeden Datenbankcluster konfigurieren. Weitere Informationen finden Sie unter Sichern und Wiederherstellen in Kubernetes.
Sie können AlloyDB Omni-Sicherungen lokal oder remote in Cloud Storage speichern, einschließlich der Optionen, die von einem beliebigen Cloud-Anbieter bereitgestellt werden. Weitere Informationen finden Sie in Abbildung 1, in der potenzielle Sicherungsziele dargestellt sind.
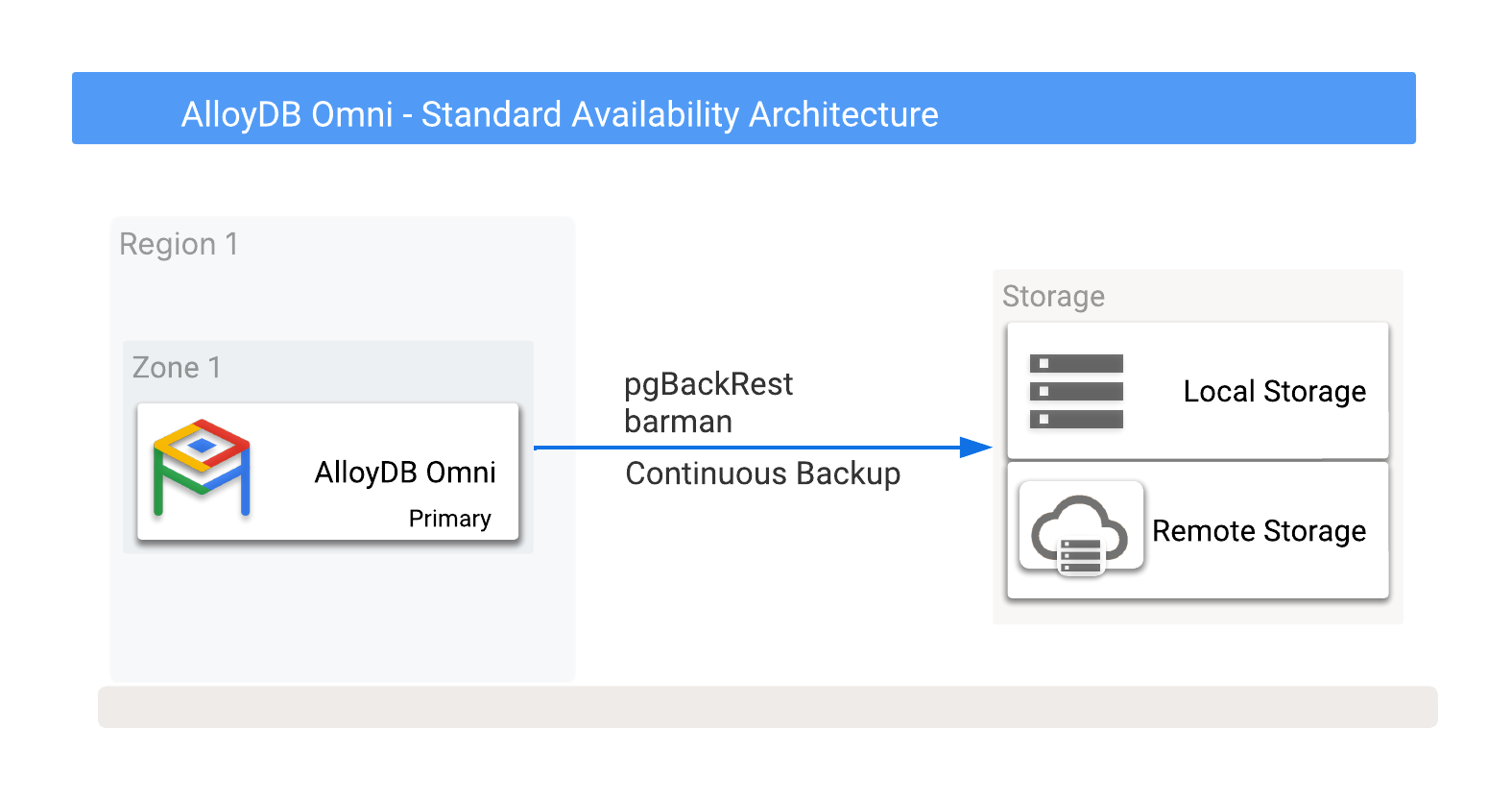
Abbildung 1. AlloyDB Omni mit Sicherungsoptionen
Sicherungen können entweder auf lokalen oder Remote-Speicheroptionen erstellt werden. Lokale Backups sind in der Regel schneller, da sie nur auf dem E/A-Durchsatz basieren, während Remote-Backups in der Regel eine höhere Latenz und eine geringere Netzwerkbandbreite haben. Remote-Backups bieten jedoch optimalen Schutz, auch bei zonalen Ausfällen.
Sie können lokale Sicherungen auch auf lokalen oder freigegebenen Speicher aufteilen. Lokale Speicheroptionen sind von fehlenden Optionen zur Notfallwiederherstellung betroffen, wenn ein Datenbankhost ausfällt. Bei gemeinsam genutztem Speicher kann dieser Speicher auf einen anderen Server verlagert und dann für die Wiederherstellung verwendet werden. Das bedeutet, dass der RTO bei gemeinsam genutztem Speicher möglicherweise kürzer ist.
Bei Bereitstellungen mit lokalem und freigegebenem Speicher können die folgenden Arten von Sicherungen geplant oder manuell auf Anfrage erstellt werden:
- Vollsicherungen: vollständige Sicherungen aller Datenbankdateien, die für die Datenwiederherstellung erforderlich sind.
- Differenzielle Back-ups: Back-ups, die nur die Änderungen an Dateien seit dem letzten vollständigen Back-up enthalten.
- Inkrementelle Sicherungen: Sicherungen nur der Dateiänderungen seit der letzten Sicherung jeglicher Art.
Wiederherstellung zu einem bestimmten Zeitpunkt
Kontinuierliche Sicherungen der PostgreSQL-WAL-Dateien (Write-Ahead Logging) unterstützen die Wiederherstellung zu einem bestimmten Zeitpunkt. Wenn die WAL-Dateien nach einem Fehlerereignis intakt und verwendbar sind, können Sie sie zur Wiederherstellung ohne Datenverlust verwenden.
Sie können die folgenden Parameter konfigurieren, um das Schreiben der WAL-Dateien zu steuern:
| Parameter | Beschreibung |
|---|---|
|
Gibt an, wie oft der WAL-Writer den WAL auf die Festplatte schreibt, sofern der Schreibvorgang nicht früher durch eine asynchron ausgeführte Transaktion ausgelöst wird. Der Standardwert ist 200 ms. Durch Erhöhen dieses Werts wird die Häufigkeit von Schreibvorgängen verringert, aber die Menge der Daten, die bei einem Serverabsturz verloren gehen, kann zunehmen. |
|
Gibt an, wie viele WAL-Daten sich ansammeln können, bevor der WAL-Writer einen Flush auf die Festplatte erzwingt. Der Standardwert ist 1 MB. Wenn der Wert auf null gesetzt ist, werden WAL-Daten immer sofort auf die Festplatte geschrieben. |
|
Gibt an, ob für den Commit eine Antwort an den Nutzer zurückgegeben wird, bevor die WAL-Daten auf die Festplatte geschrieben werden. Die Standardeinstellung ist on. Dadurch wird sichergestellt, dass die Transaktion dauerhaft ist. Mit anderen Worten: Der Commit wurde auf die Festplatte geschrieben, bevor ein Erfolgscode an den Nutzer zurückgegeben wurde. Bei der Einstellung off gibt es bis zu dreimal wal_writer_delay, bevor die Transaktion auf das Laufwerk geschrieben wird. |
Überwachung der WAL-Nutzung
Sie haben folgende Möglichkeiten, die WAL-Nutzung zu beobachten:
| Beobachtungsmethode | Beschreibung |
|---|---|
|
Diese Standardansicht enthält die Spalten wal_write und wal_sync, in denen die Anzahl der WAL-Schreibvorgänge und WAL-Synchronisierungen gespeichert ist. Wenn der Konfigurationsparameter track_wal_io_timing aktiviert ist, werden auch wal_write_time und wal_sync_time gespeichert. Regelmäßige Momentaufnahmen dieser Ansicht können helfen, die WAL-Schreib- und Synchronisierungsaktivität im Zeitverlauf darzustellen. |
pg_current_wal_lsn() |
Diese Funktion gibt die aktuelle Position der Logfolgenummer (Log Sequence Number, LSN) zurück. Wenn sie mit einem Zeitstempel verknüpft und im Laufe der Zeit als Snapshots erfasst wird, kann sie die Byte/Sekunde des WAL liefern, die mit der Funktion pg_wal_lsn_diff(lsn1, lsn2) generiert wird.
Diese Funktion ist ein nützlicher Messwert, um die Transaktionsrate und die Leistung der WAL-Dateien zu verstehen. |
WAL-Daten an einen Remote-Standort streamen
Wenn Sie Barman verwenden, können die WAL-Daten auch so eingerichtet werden, dass sie in Echtzeit an einen Remote-Standort gestreamt werden, um sicherzustellen, dass bei der Wiederherstellung nur geringe oder gar keine Daten verloren gehen. Trotz des Streamings in Echtzeit besteht eine geringe Wahrscheinlichkeit, dass zugesicherte Transaktionen verloren gehen, da die Streaming-Schreibvorgänge auf dem Remote-Barman-Server standardmäßig asynchron sind. Es ist jedoch möglich, WAL-Streaming im synchronen Modus einzurichten, in dem das WAL gespeichert und eine Statusantwort an die Quelldatenbank zurückgesendet wird. Beachten Sie, dass dieser Ansatz Transaktionen verlangsamen kann, wenn sie warten müssen, bis dieser Schreibvorgang abgeschlossen ist, bevor sie fortgesetzt werden können.
Sicherungszeitpläne
In den meisten Umgebungen werden Sicherungen in der Regel wöchentlich geplant. Im Folgenden finden Sie ein typisches wöchentliches Sicherungsschema:
- Sonntag: Vollsicherung
- Montag, Dienstag: Sicherung
- Mittwoch: differenzielle Sicherung
- Donnerstag, Freitag: inkrementelle Sicherung
- Samstag: differenzielle Sicherung
Bei diesem typischen Zeitplan ist für ein fortlaufendes Wiederherstellungsfenster von einer Woche Speicherplatz für bis zu drei vollständige Sicherungen sowie die erforderlichen inkrementellen oder differenziellen Sicherungen erforderlich. Dieser Ansatz unterstützt die Wiederherstellung nach einem Fehler, der während der vollständigen Sicherung am Sonntag auftritt. Die Datenbankwiederherstellung muss bis zum vorherigen Sonntag vor dem Start der Sicherung erfolgen.
Um die RTO bei einem potenziell höheren RPO zu minimieren, können zusätzliche Datenbanken im kontinuierlichen Wiederherstellungsmodus betrieben werden. Dazu müssen Sicherungen wiedergegeben und die sekundäre Umgebung kontinuierlich aktualisiert werden, indem neue WAL-Dateien archiviert und wiedergegeben werden. Der tatsächliche RPO, der den potenziellen Datenverlust widerspiegelt, hängt von der Transaktionshäufigkeit, der WAL-Dateigröße und der Verwendung von WAL-Streaming ab.
Wiederherstellen in Nicht-Kubernetes-Umgebungen
Bei Nicht-Kubernetes-Bereitstellungen müssen Sie zum Wiederherstellen einer AlloyDB Omni-Datenbank entweder den Docker-Container beenden und dann Daten wiederherstellen oder die Daten an einem anderen Speicherort wiederherstellen und eine neue Docker-Instanz mit diesen wiederhergestellten Daten starten. Nach dem Neustart des Containers ist die Datenbank mit den wiederhergestellten Daten zugänglich.
Weitere Informationen zu Wiederherstellungsoptionen finden Sie unter AlloyDB Omni-Cluster mit pgBackRest wiederherstellen und AlloyDB Omni-Cluster mit Barman wiederherstellen.
Wiederherstellen in Kubernetes mit Operator
Zum Wiederherstellen einer Datenbank in Kubernetes bietet der Operator die Wiederherstellung im selben Kubernetes-Cluster und ‑Namespace aus einer benannten Sicherung oder einem Klon von einem Point-in-Time (PIT). Wenn Sie eine Datenbank in einen anderen Kubernetes-Cluster klonen möchten, verwenden Sie pgBackRest. Weitere Informationen finden Sie unter Sichern und Wiederherstellen in Kubernetes und Datenbankcluster aus einer Kubernetes-Sicherung klonen – Übersicht.
Implementierung
Wenn Sie eine Referenzarchitektur für die Verfügbarkeit auswählen, sollten Sie die folgenden Vorteile, Einschränkungen und Alternativen berücksichtigen.
Vorteile
- Einfach zu verwenden und zu verwalten und für nicht kritische Datenbanken mit toleranter RTO/RPO geeignet.
- Nur minimale zusätzliche Hardware erforderlich
- Sicherungen sind immer für einen vollständigen Notfallwiederherstellungsplan erforderlich.
- Die Wiederherstellung zu einem beliebigen Zeitpunkt innerhalb des Wiederherstellungszeitraums ist möglich.
Beschränkungen
- Speicheranforderungen, die je nach Aufbewahrungsanforderungen möglicherweise größer als die Datenbank selbst sind.
- Die Wiederherstellung kann lange dauern und zu einem höheren RTO führen.
- Kann je nach Verfügbarkeit der aktuellen WAL-Daten nach einem Datenbankfehler zu einem gewissen Datenverlust führen, was sich negativ auf den RPO auswirken kann.
Alternativen
- Erwägen Sie die erweiterte oder Premium-Verfügbarkeitsarchitektur, um die Verfügbarkeit und die Optionen zur Notfallwiederherstellung zu verbessern.
Nächste Schritte
- Übersicht über die Referenzarchitektur für die Verfügbarkeit von AlloyDB Omni
- AlloyDB Omni – erhöhte Verfügbarkeit.
- Verfügbarkeit von AlloyDB Omni Premium.
- AlloyDB Omni in Kubernetes installieren
- pgBackRest für AlloyDB Omni einrichten
- Barman für AlloyDB Omni einrichten
- Sichern und Wiederherstellen in Kubernetes
- AlloyDB Omni-Cluster mit pgBackRest wiederherstellen
- AlloyDB Omni-Cluster mit Barman wiederherstellen
- Sichern und Wiederherstellen in Kubernetes
- Datenbankcluster über eine Kubernetes-Sicherungsübersicht klonen