クラウドでモデルのトレーニングや予測の取得の際に発生するエラーの原因を特定することは困難な場合があります。ここでは、AI Platform Training で発生した問題の検出とデバッグの方法を説明します。使用している機械学習フレームワークで問題が発生した場合は、機械学習フレームワークのドキュメントをご覧ください。
コマンドライン ツール
ERROR: (gcloud) Invalid choice: 'ai-platform'.このエラーは、gcloud の更新が必要であることを示しています。gcloud を更新するには、次のコマンドを実行します。
gcloud components updateERROR: (gcloud) unrecognized arguments: --framework=SCIKIT_LEARN.このエラーは、gcloud の更新が必要であることを示しています。gcloud を更新するには、次のコマンドを実行します。
gcloud components updateERROR: (gcloud) unrecognized arguments: --framework=XGBOOST.このエラーは、gcloud の更新が必要であることを示しています。gcloud を更新するには、次のコマンドを実行します。
gcloud components updateERROR: (gcloud) Failed to load model: Could not load the model: /tmp/model/0001/model.pkl. '\\x03'. (Error code: 0)このエラーは、モデルのエクスポートに間違ったライブラリが使用されたことを意味します。この問題を解決するには、正しいライブラリを使用してモデルを再度エクスポートします。たとえば、
model.pklというモデルをエクスポートするにはpickleライブラリを使用し、model.joblibというモデルをエクスポートするにはjoblibライブラリを使用します。ERROR: (gcloud.ai-platform.jobs.submit.prediction) argument --data-format: Invalid choice: 'json'.このエラーは、バッチ予測ジョブの送信時に、
--data-formatフラグの値としてjsonが指定されたことを意味します。JSONデータ形式を使用するには、--data-formatフラグの値としてtextを指定する必要があります。
Python のバージョン
ERROR: Bad model detected with error: "Failed to load model: Could not load the
model: /tmp/model/0001/model.pkl. unsupported pickle protocol: 3. Please make
sure the model was exported using python 2. Otherwise, please specify the
correct 'python_version' parameter when deploying the model. Currently,
'python_version' accepts 2.7 and 3.5. (Error code: 0)"
このエラーは、Python 3 でエクスポートされたモデルファイルが、Python 2.7 が設定された AI Platform Training モデル バージョンのリソースにデプロイされたことを意味します。
この問題を解決するには:
- 新しいモデル バージョンのリソースを作成して、python_version を 3.5 に設定します。
- 同じモデルファイルを新しいモデル バージョンのリソースにデプロイします。
virtualenv コマンドが見つかりません
virtualenv をアクティブにしようとしたときにこのエラーが発生した場合、考えられる 1 つのソリューションは、virtualenv を含むディレクトリを $PATH 環境変数に追加することです。この変数を変更すると、ファイルの完全なパスを入力せずに virtualenv コマンドを使用できます。
まず、次のコマンドを実行して、virtualenv をインストールします。
pip install --user --upgrade virtualenv
$PATH 環境変数の変更を促すプロンプトが表示され、virtualenv スクリプトのパスが指定されます。macOS では、/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin のようになります。
シェルが環境変数を読み込むファイルを開きます。macOS では、これは通常 ~/.bashrc または ~/.bash_profile です。
次の行を追加し、[VALUES-IN-BRACKETS] を適切な値に置き換えます。
export PATH=$PATH:/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin
最後に、次のコマンドを実行して、更新した .bashrc(または .bash_profile)ファイルを読み込みます。
source ~/.bashrc
ジョブログの使用
トラブルシューティングを行うには、最初に Cloud Logging によって記録されたジョブログを調べることをおすすめします。
さまざまなタイプのオペレーションのロギング
ログの内容は、次の各セクションで示すようにオペレーションのタイプによって異なります。
トレーニングのログ
すべてのトレーニング ジョブがログに記録されます。このログには、トレーニング サービスのイベントとトレーニング アプリケーションのイベントが含まれます。 標準の Python ライブラリ(たとえば logging)を使用して、ロギング イベントをアプリケーション内に構成できます。AI Platform Training は、アプリケーションからのすべてのロギング メッセージを取得します。stderr に送信されたすべてのメッセージは、Cloud Logging のジョブのエントリに自動的に記録されます。
バッチ予測のログ
すべてのバッチ予測ジョブがログに記録されます。
オンライン予測のログ
オンライン予測リクエストを行ったときに、デフォルトではログは生成されません。モデルリソースを作成するときに、次の方法で Cloud Logging を有効にできます。
gcloud
gcloud ai-platform models create を実行するときに、--enable-logging フラグを指定します。
Python
projects.models.create に対する呼び出しに使用する Model リソースで onlinePredictionLogging を True に設定します。
ログを探す
ジョブのログには、オペレーションのすべてのイベントが記録されています。分散トレーニングを使用しているときは、クラスタ内のすべてのプロセスからのイベントがログに記録されます。分散型トレーニング ジョブを実行する場合は、ジョブレベルのログはマスター ワーカー プロセスのものとして報告されます。エラーのトラブルシューティングの最初のステップは一般的に、そのプロセスのログを調べて、記録されたイベントのうちクラスタ内の他のプロセスのものを除外することです。このセクションの例では、このフィルタリングを示しています。
ログのフィルタリングは、コマンドラインからでも、Google Cloud コンソールの [Cloud Logging] セクションからでも行えます。どちらの場合も、次に示すメタデータ値を必要に応じてフィルタの中で使用します。
| メタデータ項目 | 次の条件を満たすものを表示するフィルタ |
|---|---|
| resource.type | "cloud_ml_job" に等しい。 |
| resource.labels.job_id | ジョブ名に等しい。 |
| resource.labels.task_name | "master-replica-0" に等しい(マスター ワーカーのログエントリのみを読み取る場合)。 |
| 重要度 | ERROR 以上(エラー状態に対応するログエントリのみを読み取る場合)。 |
コマンドライン
gcloud beta logging read を使用して必要なクエリを作成します。たとえば次のようなものがあります。
各例は、次に示す環境変数に依存しています。
PROJECT="my-project-name"
JOB="my_job_name"
必要に応じて、文字列リテラルを代わりに入力することもできます。
ジョブログを画面に出力するには:
gcloud ai-platform jobs stream-logs $JOB
gcloud ai-platform jobs stream-logs で使用できるすべてのオプションをご確認ください。
マスター ワーカーのログを画面に出力するには:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\""
ログに記録されたエラーのうち、マスター ワーカーのものだけを画面に出力するには:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\" and severity>=ERROR"
上記の例は、AI Platform Training のトレーニング ジョブのログをフィルタリングする最も一般的なケースを示しています。Cloud Logging には、フィルタリングのための便利なオプションが多数あり、検索を絞り込む必要がある場合に使用できます。高度なフィルタリングのドキュメントに、これらのオプションの詳細な説明があります。
Console
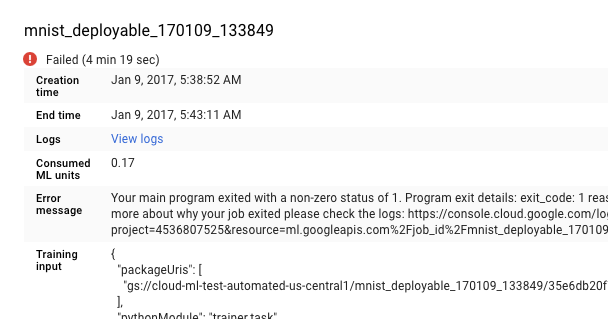
Google Cloud コンソールで AI Platform Training の [ジョブ] ページを開きます。
失敗したジョブを [ジョブ] ページの一覧から選択して詳細情報を表示します。

- [ログを表示] をクリックして Cloud Logging を開きます。
Cloud Logging に直接移動することもできますが、ジョブを見つけるというステップが必要になります。
- リソース セレクタを展開します。
- リソースリストの中の Cloud ML ジョブを展開します。
- job_id リストの中でジョブ名を見つけます(ジョブ名の最初の数文字を検索ボックスに入力すると、表示されるジョブを絞り込めます)。
- ジョブのエントリを展開し、タスクリストから
master-replica-0を選択します。

ログからの情報の取得
ジョブの正しいログが見つかり、フィルタリングして master-replica-0 だけが表示される状態になったら、ログに記録されたイベントを調べて問題の発生源を見つけます。これには標準的な Python のデバッグ手順が含まれますが、次のことに注意してください。
- イベントの重大度はいくつかのレベルに分かれています。イベントをフィルタリングすると、特定のレベル(エラーだけ、またはエラーと警告など)のイベントだけを表示できます。
- 問題が発生したためトレーナーが回復不能なエラー状態(戻りコード > 0)で終了した場合は、例外としてログに記録され、その前にスタック トレースが記録されます。
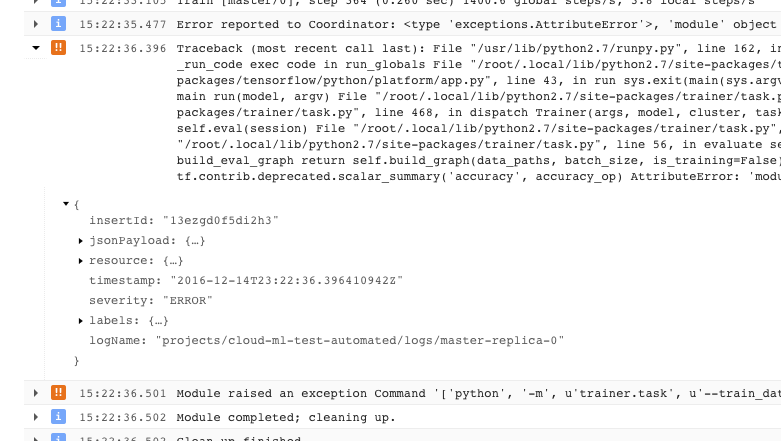
- さらに情報を入手するには、記録された JSON メッセージの中のオブジェクトを展開します(右向き矢印付きで、内容は {...} と表示されています)。たとえば、jsonPayload を展開すると、スタック トレースはメインのエラーの説明よりも読みやすい形式で表示されます。
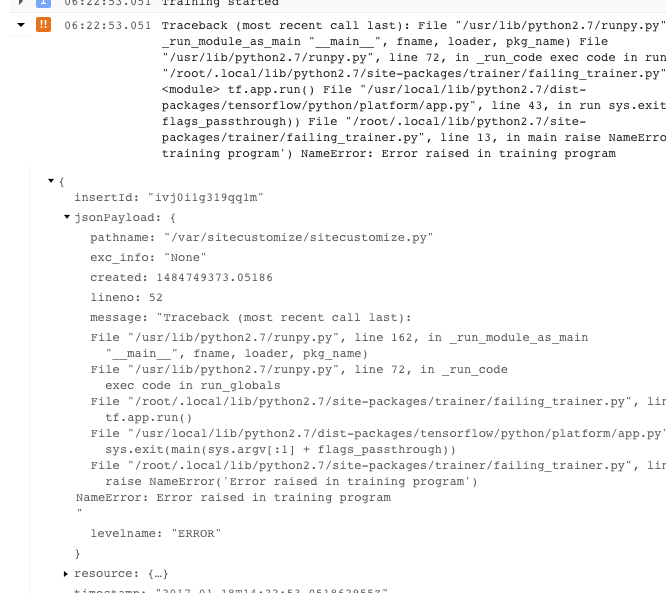
- エラーの中には、再試行可能なエラーもあります。このようなエラーには一般的に、スタック トレースが含まれていないため、診断が難しくなることがあります。
ロギングを最大限に活用
AI Platform Training トレーニング サービスは、自動的に次のイベントを記録します。
- サービス内部のステータス情報。
- トレーナー アプリケーションから
stderrに送信されるメッセージ。 - トレーナー アプリケーションから
stdoutに送信される出力テキスト。
トレーナー アプリケーションのエラーのトラブルシューティングを容易にするには、次のようにプログラミングすることをおすすめします。
- 意味のあるメッセージを stderr に送信します(たとえば logging を使用します)。
- なんらかの問題が生じたときは、最も論理的で記述的な例外を発生させます。
- 説明の文字列を例外オブジェクトに追加します。
Python のドキュメントに、例外に関する詳しい情報が記載されています。
トレーニングのトラブルシューティング
このセクションでは、トレーニング ジョブに適用されるコンセプトとエラー条件について説明します。
トレーニング アプリケーションの戻りコードの理解
クラウドでのトレーニング ジョブを制御するのは、トレーニング クラスタのマスター ワーカー プロセスで実行されるメイン プログラムです。
- トレーニングを単一のプロセスで行う場合は(非分散型)、ワーカーは 1 つだけであり、これがマスターです。
- メイン プログラムは、TensorFlow トレーニング アプリケーションの
__main__関数です。 - AI Platform Training のトレーニング サービスによるトレーナー アプリケーションの実行は、アプリケーションが正常に完了するか、回復不能なエラーが発生するまで続きます。つまり、再試行可能なエラーが発生した場合はプロセスが再起動される可能性があります。
トレーニング サービスは、プロセスを管理します。プログラムの終了は、マスター ワーカー プロセスの戻りコードに従って処理されます。
| 戻りコード | 意味 | AI Platform Training のレスポンス |
|---|---|---|
| 0 | 正常に完了 | シャットダウンしてジョブのリソースを解放します。 |
| 1~128 | 回復不能エラー | ジョブを終了してエラーをログに記録します。 |
__main__ 関数の戻りコードに関して、特に何もする必要はありません。正常に完了したときは Python が自動的に 0 を返し、処理できない例外が発生したときは正のコードを返します。例外オブジェクトに特定の戻りコードを設定するようにプログラミングされていても(間違いではありませんが、あまり一般的な方法ではありません)、上記の表のパターンに従っている限り、AI Platform Training のジョブに影響が及ぶことはありません。その場合も、クライアント コードは一般的に、再試行可能なエラーを直接示すことはありません。このようなエラーは、運用環境からのものです。
特定のエラー条件の処理
このセクションでは、一部のユーザーに影響を及ぼすことが知られているエラー状態に関するガイダンスを示します。
リソース不足です
us-central1 は GPU とコンピューティング リソースの需要が高いリージョンです。ジョブログに、「Resources are
insufficient in region: <region>. Please try a different region.」というエラー メッセージが記録されることがあります。
この問題を解決するには、別のリージョンを使用するか後で再試行してください。
何も進行することなくトレーナーが永遠に実行を続ける
状況によっては、トレーナー アプリケーションが実行を続けているにもかかわらずトレーニング タスクが何も進行しないことがあります。この原因としては、決して利用可能になることのないリソースを待っているブロック呼び出しが考えられます。この問題を軽減するには、トレーナーの中でタイムアウト時間を設定してください。
トレーナーのタイムアウト時間を設定する
タイムアウト(ミリ秒単位)は、セッションを作成するときか、グラフのステップを実行するときに設定できます。
Session オブジェクトを作成する際に、次のように config パラメータを使用して必要なタイムアウト間隔を設定します。
sess = tf.Session(config=tf.ConfigProto(operation_timeout_in_ms=500))Session.run の 1 回の呼び出しに必要なタイムアウト間隔を設定するには、次のように options パラメータを使用します。
v = session.run(fetches, options=tf.RunOptions(timeout_in_ms=500))
詳細については、TensorFlow の Session に関するドキュメントをご覧ください。
プログラムがコード -9 で終了する
終了コード -9 が続く場合は、トレーナー アプリケーションが、そのプロセス用に割り当てられているよりも多くのメモリを使用している可能性があります。このエラーを解決するには、メモリ使用量を減らすか、メモリ容量の大きいマシンタイプを使用してください。
- グラフとトレーナー アプリケーションに、予想以上に多くのメモリを使用しているオペレーションがあるかどうかを調べます。メモリ使用量に影響を与えるものとしては、データの複雑さと、計算グラフのオペレーションの複雑さがあります。
- ジョブに割り当てられるメモリを増やすには、次のような方法が必要になることがあります。
- 定義済みのスケール階層を使用する場合は、マシンを追加することなくマシンあたりのメモリ割り当てを増やすことはできません。カスタム階層に切り替えて、クラスタ内のマシンタイプを自分で定義する必要があります。
- 定義済みの各マシンタイプの正確な構成は変更される可能性がありますが、大まかな比較は可能です。マシンタイプの比較表がトレーニングのコンセプトのページにあります。
- 適切なメモリ割り当てを見つけるためにさまざまなマシンタイプをテストするときは、請求される料金を最小限に抑えるために、マシンを 1 つだけ、または小さいサイズのクラスタを使用することをおすすめします。
プログラムがコード -15 で終了する
一般的に、終了コード -15 はシステムによる保守を示します。これは再試行可能なエラーであるため、プロセスは自動的に再起動されます。
ジョブが長時間キューに入っている
トレーニング ジョブの状態が長時間 QUEUED のままの場合、ジョブ リクエストの割り当てを超過している可能性があります。
AI Platform Training によるトレーニング ジョブの開始はジョブ作成時間に基づいており、先入れ先出し規則が使用されます。ジョブがキューに入っている場合は、プロジェクト割り当てがすべて、そのジョブよりも前に送信されたジョブに使用されているか、キューの先頭のジョブが要求している ML ユニット / GPU が残りの割り当てを超えていることを示しています。
ジョブがキューに入れられた理由は、トレーニング ログに記録されます。ログの中で次のようなメッセージを探してください。
This job is number 2 in the queue and requires
4.000000 ML units and 0 GPUs. The project is using 4.000000 ML units out of 4
allowed and 0 GPUs out of 10 allowed.このメッセージは、キュー内のジョブの現在位置と、プロジェクトの現在の使用量と割り当てを表しています。
なお、理由がログに記録されるのは、キューに入っているジョブのうち、ジョブ作成時間順で最初の 10 個だけです。
割り当てられた数以上のリクエストが必要になることが多い場合は、割り当ての増加をリクエストできます。プレミアム サポート パッケージをお持ちの場合は、サポートにご連絡ください。それ以外の場合は、リクエストをメールで AI Platform Training フィードバックにお送りください。
容量を超えています
「project_number への割当てが失敗しました...」のようなエラーが発生した場合は、リソース割り当てを超過している可能性があります。リソース消費量のモニタリングと増加のリクエストは、コンソールの API Manager の AI Platform Training 割り当てページで行うことができます。
無効な保存パス
ジョブの終了時に返されるエラー メッセージに「無効な保存パス gs://... で復元が呼び出されました」が含まれている場合は、使用している Google Cloud Storage バケットが正しく構成されていない可能性があります。
Google Cloud Platform Console で Google Cloud Storage の [ブラウザ] ページを開きます。
使用しているバケットの [デフォルトのストレージ クラス] を調べます。

- これは Regional のはずです。そうなっている場合は、他に問題があります。ジョブをもう一度実行してみてください。
- [Multi-Regional] の場合は、[Regional] に変更するか、トレーニング用マテリアルを別のバケットに移動する必要があります。前者については、Cloud Storage のドキュメントにあるバケットのストレージ クラスの変更手順をご覧ください。
トレーナーが AbortedError で終了する
このエラーは、TensorFlow Supervisor を使用して分散ジョブを管理するトレーナーを実行している場合に発生することがあります。TensorFlow は、ジョブ全体を停止すべきでない状況で AbortedError 例外をスローする場合があります。この例外はトレーナーで捕捉して適切に対処できます。なお、TensorFlow Supervisor は、AI Platform Training で実行するトレーナーではサポートされていません。
予測のトラブルシューティング
このセクションでは、予測を取得するときに発生する一般的な問題をまとめています。
オンライン予測の特定の条件の処理
このセクションでは、一部のユーザーに影響を及ぼすことが知られているオンライン予測エラー条件に関するガイダンスを示します。
予測の完了までに時間がかかりすぎる(30~180 秒)
オンライン予測の遅さの原因として最も一般的なものは、処理ノードが 0 からスケールアップされることです。モデルに対する予測リクエストが絶えず行われる場合は、予測を処理できる状態のノードが 1 つ以上維持されます。モデルが予測を処理しない時間が長期に及んだ場合は、サービスが自動的に「スケールダウン」し、使用可能なノードは 0 になります。このようなスケールダウンの後に行われた予測リクエストは、結果が返されるまで通常よりも長い時間がかかりますが、これは処理するためのノードのプロビジョニングが必要になるためです。
HTTP ステータス コード
オンライン予測リクエストでエラーが発生すると、通常は HTTP ステータス コードがサービスから返されます。よく発生するコードと、オンライン予測におけるその意味を次に示します。
- 429 - メモリ不足
処理ノードでのモデルの実行中に、メモリの空きがなくなりました。予測ノードに割り当てられたメモリを増やす方法は、この時点ではありません。モデルを実行できるようにするには、次のことを試してみてください。
- 次の方法でモデルを小さくします。
- 精度の低い変数を使用する。
- 連続データを量子化する。
- 他の入力特徴のサイズを小さくする(たとえば、ボキャブラリのサイズを小さくする)。
- バッチのインスタンス数を減らしてリクエストをもう一度送信する。
- 次の方法でモデルを小さくします。
- 429 - 保留中のリクエストが多すぎます
モデルが処理できる以上のリクエストが発生しています。自動スケーリングを使用している場合は、システムがスケールアップできる速さを超えてリクエストが発生しています。
自動スケーリングを使用しているときは、指数バックオフを指定してリクエストを再送信してみてください。 このようにすると、システムに調整する時間を与えることが可能です。
- 429 - 割り当て
Google Cloud Platform プロジェクトのリクエスト数は、100 秒あたり 10,000 件(1 秒あたり約 100 件)に制限されています。リクエストの一時的な急増によりこのエラーが発生した場合は、指数バックオフを使用して再試行するとすべてのリクエストを時間どおりに処理できることがあります。このコードが返されることが続く場合は、割り当ての増加をリクエストしてください。詳細については、割り当てのページをご覧ください。
- 503 - ご利用のコンピュータ ネットワークから通常以上のトラフィックが検出されました
単一の IP からモデルが受け取るリクエストの頻度が高すぎるため、サービス拒否攻撃が疑われています。リクエストの送信を 1 分間停止してから、頻度を下げて送信を再開してください。
- 500 - モデルを読み込めませんでした
システムがモデルを読み込むことができませんでした。次のステップを試してください。
- トレーナーがエクスポートしているモデルが正しいことを確認します。
gcloud ai-platform local predictコマンドを使用してテスト予測を試行します。- モデルを再度エクスポートして、再試行します。
予測リクエストのフォーマット エラー
次に示すメッセージはすべて、予測入力に関係しています。
- 「リクエスト本文が空白であるか、不適切または無効な JSON があります」
- リクエスト内の JSON を解析できなかったか、リクエストが空です。JSON を無効にするエラーや省略がメッセージにないかどうかを確認してください。
- 「リクエスト本文にインスタンス フィールドが見つかりません」 リクエスト本文の形式が正しくありません。
- リクエスト本文は、JSON オブジェクトであり、キーは 1 つだけで名前が
"instances"であり、この中にすべての入力インスタンスのリストが格納されている必要があります。 - リクエストの作成時に、JSON のエンコード エラーが発生しました
リクエストの中に base64 でエンコードされたデータがありますが、適切な JSON 形式ではありません。base64 でエンコードされた文字列はそれぞれ、
"b64"という名前の単一のキーを持つオブジェクトで表す必要があります。次に例を示します。{"b64": "an_encoded_string"}base64 エラーは、base64 でエンコードされていないバイナリデータがある場合にも発生します。データをエンコードして、次のようにフォーマットします。
{"b64": base64.b64encode(binary_data)}詳細については、バイナリデータのフォーマットとエンコーディングをご覧ください。
クラウドの予測に要する時間がデスクトップよりも長い
オンライン予測は、大量の予測リクエストを短時間で処理するスケーラブルなサービスとして設計されています。このサービスは、処理リクエストすべての全体的なパフォーマンスを高めるように最適化されています。スケーラビリティに重点を置いていることから、パフォーマンス特性はローカルマシンで少数の予測を生成する場合とは異なるものとなります。
次のステップ
- サポートを利用する。
- Google API のエラーモデルの詳細を確認する。特に、
google.rpc.Codeで定義されている正規のエラーコードと、google/rpc/error_details.proto で定義されている標準エラーの詳細について学習する。 - トレーニング ジョブをモニタリングする方法を確認する。
- Cloud TPU での AI Platform の実行時、Cloud TPU についてのトラブルシューティングとよくある質問を参照して、診断と問題解決を行う。