Dokumen ini menunjukkan cara menguji dan memantau performa layanan online model machine learning (ML) yang di-deploy ke AI Platform Prediction. Dokumen ini menggunakan Locust, alat open source untuk pengujian beban.
Dokumen ini ditujukan untuk data scientist dan engineer MLOps yang ingin memantau beban kerja layanan, latensi, dan penggunaan resource model ML mereka dalam produksi.
Dokumen ini mengasumsikan bahwa Anda memiliki pengalaman dengan Google Cloud, TensorFlow, AI Platform Prediction, Cloud Monitoring, dan notebook Jupyter.
Dokumen ini disertai dengan repositori GitHub yang menyertakan kode dan panduan deployment untuk menerapkan sistem yang dijelaskan dalam dokumen ini. Tugas-tugas tersebut dimasukkan ke dalam notebook Jupyter.
Biaya
Notebook yang Anda gunakan dalam dokumen ini menggunakan komponen Google Cloudyang dapat ditagih berikut:
- Notebook Vertex AI Workbench yang dikelola pengguna
- AI Platform Prediction
- Cloud Storage
- Cloud Monitoring
- Google Kubernetes Engine (GKE)
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda, gunakan kalkulator harga.
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
Ringkasan arsitektur
Diagram berikut menunjukkan arsitektur sistem untuk men-deploy model ML untuk prediksi online, menjalankan pengujian beban, serta mengumpulkan dan menganalisis metrik untuk performa penayangan model ML.
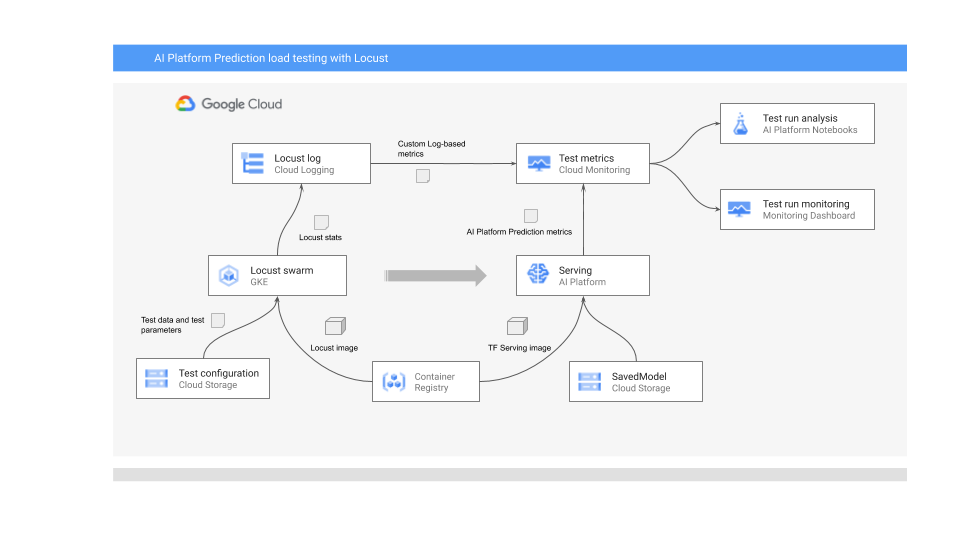
Diagram menunjukkan alur berikut:
- Model terlatih Anda mungkin berada di Cloud Storage—misalnya, SavedModel TensorFlow atau joblib scikit-learn. Atau, model dapat digabungkan ke dalam penampung penayangan kustom di Container Registry—misalnya, TorchServe untuk menayangkan model PyTorch.
- Model di-deploy ke AI Platform Prediction sebagai REST API. AI Platform Prediction adalah layanan terkelola sepenuhnya untuk penayangan model yang mendukung berbagai jenis mesin, mendukung penskalaan otomatis berdasarkan penggunaan resource, dan mendukung berbagai akselerator GPU.
- Locust digunakan untuk menerapkan tugas pengujian (yaitu, perilaku pengguna). Hal ini dilakukan dengan memanggil model ML yang di-deploy ke AI Platform Prediction dan menjalankannya dalam skala besar di Google Kubernetes Engine (GKE). Hal ini menyimulasikan banyak panggilan pengguna secara bersamaan untuk menguji beban layanan prediksi model. Anda dapat memantau progres pengujian menggunakan antarmuka web Locust.
- Locust mencatat statistik pengujian ke Cloud Logging. Entri log yang dibuat oleh pengujian Locust digunakan untuk menentukan kumpulan metrik berbasis log di Cloud Monitoring. Metrik ini melengkapi metrik AI Platform Prediction standar.
- Metrik AI Platform dan metrik Locust kustom tersedia untuk visualisasi di dasbor Cloud Monitoring secara real time. Setelah pengujian selesai, metrik juga dikumpulkan secara terprogram sehingga Anda dapat menganalisis dan memvisualisasikan metrik di notebook Vertex AI Workbench yang dikelola pengguna.
Notebook Jupyter untuk skenario ini
Semua tugas untuk menyiapkan dan men-deploy model, menjalankan pengujian Locust, serta mengumpulkan dan menganalisis hasil pengujian dikoding dalam notebook Jupyter berikut. Untuk melakukan tugas, jalankan urutan sel di setiap notebook.
01-prepare-and-deploy.ipynb. Anda menjalankan notebook ini untuk menyiapkan SavedModel TensorFlow untuk inferensi dan men-deploy model ke AI Platform Prediction.02-perf-testing.ipynb. Anda menjalankan notebook ini untuk membuat metrik berbasis log di Cloud Monitoring untuk pengujian Locust, serta men-deploy pengujian Locust ke GKE dan menjalankannya.03-analyze-results.ipynb. Anda menjalankan notebook ini untuk mengumpulkan dan menganalisis hasil pengujian beban Locust dari metrik AI Platform standar yang dibuat oleh Cloud Monitoring, dan dari metrik Locust kustom.
Melakukan inisialisasi lingkungan Anda
Seperti yang dijelaskan dalam file
README.md
dari repositori GitHub terkait, Anda perlu melakukan langkah-langkah
berikut untuk menyiapkan lingkungan guna menjalankan notebook:
- Di project Google Cloud Anda, buat bucket Cloud Storage, yang diperlukan untuk menyimpan model terlatih dan konfigurasi pengujian Locust. Catat nama yang Anda gunakan untuk bucket karena Anda akan memerlukannya nanti.
- Buat ruang kerja Cloud Monitoring dalam project Anda.
- Buat cluster Google Kubernetes Engine yang memiliki CPU yang diperlukan. Node pool harus memiliki akses ke Cloud API.
- Buat instance notebook yang dikelola pengguna Vertex AI Workbench yang menggunakan TensorFlow 2. Untuk tutorial ini, Anda tidak memerlukan GPU karena Anda tidak melatih model. (GPU dapat berguna dalam skenario lain, terutama untuk mempercepat pelatihan model Anda.)
Membuka JupyterLab
Untuk mengerjakan tugas pada skenario ini, Anda perlu membuka lingkungan JupyterLab dan mendapatkan notebook.
Di konsol Google Cloud, buka halaman Notebooks.
Di tab User-managed notebooks, klik Open Jupyterlab di samping lingkungan notebook yang Anda buat.
Tindakan ini akan membuka lingkungan JupyterLab di browser Anda.
Untuk meluncurkan tab terminal, klik ikon Terminal di tab Peluncur.
Di terminal, clone repositori GitHub
mlops-on-gcp:git clone https://github.com/GoogleCloudPlatform/mlops-on-gcp.gitSetelah perintah selesai, Anda akan melihat folder
mlops-on-gcpdi file browser. Di folder tersebut, Anda akan melihat notebook yang Anda gunakan dalam dokumen ini.
Mengonfigurasi setelan notebook
Di bagian ini, Anda akan menetapkan variabel di notebook dengan nilai yang spesifik untuk konteks, dan menyiapkan lingkungan untuk menjalankan kode untuk skenario tersebut.
- Buka direktori
model_serving/caip-load-testing. - Untuk setiap tiga notebook, lakukan hal berikut:
- Buka notebook.
- Jalankan sel di bagian Configure Google Cloud environment settings.
Bagian berikut menyoroti bagian-bagian penting dari proses tersebut serta menjelaskan aspek desain dan kode.
Menayangkan model untuk prediksi online
Model ML yang digunakan dalam dokumen ini menggunakan model klasifikasi gambar ResNet V2 101 yang telah dilatih sebelumnya dari TensorFlow Hub. Namun, Anda dapat menyesuaikan pola dan teknik desain sistem dari dokumen ini ke domain lain dan ke jenis model lainnya.
Kode untuk menyiapkan dan menayangkan model ResNet 101 ada di notebook 01-prepare-and-deploy.ipynb. Anda menjalankan sel di notebook untuk melakukan tugas berikut:
- Download dan jalankan model ResNet dari TensorFlow Hub.
- Buat tanda tangan penayangan untuk model.
- Mengekspor model sebagai SavedModel.
- Men-deploy SavedModel ke AI Platform Prediction.
- Validasi model yang di-deploy.
Bagian berikutnya dalam dokumen ini memberikan detail tentang cara menyiapkan model ResNet dan cara men-deploy-nya.
Menyiapkan model ResNet untuk deployment
Model ResNet dari TensorFlow Hub tidak memiliki tanda tangan penayangan karena dioptimalkan untuk rekomposisi dan penyesuaian. Oleh karena itu, Anda perlu membuat tanda tangan penayangan untuk model agar dapat menayangkan model untuk prediksi online.
Selain itu, untuk menayangkan model, sebaiknya sematkan logika rekayasa fitur ke dalam antarmuka penayangan. Dengan melakukan hal ini, Anda akan menjamin kesesuaian antara prapemrosesan dan penayangan model, bukan bergantung pada aplikasi klien untuk memproses data dalam format yang diperlukan. Anda juga harus menyertakan pascapemrosesan di antarmuka penayangan, seperti mengonversi ID class menjadi label class.
Agar model ResNet dapat ditayangkan, Anda perlu menerapkan tanda tangan penayangan yang menjelaskan metode inferensi model. Oleh karena itu, kode notebook menambahkan dua tanda tangan:
- Tanda tangan default. Tanda tangan ini mengekspos metode
predictdefault dari model ResNet V2 101; metode default tidak memiliki logika pra-pemrosesan atau pascapemrosesan. - Prapemrosesan dan pascapemrosesan tanda tangan. Input yang diharapkan untuk antarmuka ini memerlukan prapemrosesan yang relatif kompleks, termasuk encoding, penskalaan, dan normalisasi gambar. Oleh karena itu, model ini juga mengekspos tanda tangan alternatif yang menyematkan logika pra-pemrosesan dan pascapemrosesan. Tanda tangan ini menerima gambar mentah yang belum diproses dan menampilkan daftar label class yang diberi peringkat dan probabilitas label terkait.
Tanda tangan dibuat di class modul kustom. Class ini berasal dari
class dasar
tf.Module
yang mengenkapsulasi model ResNet. Class kustom memperluas class
dasar dengan metode yang menerapkan logika prapemrosesan gambar dan
pascapemrosesan output. Metode default modul kustom dipetakan ke
metode default model ResNet dasar untuk mempertahankan antarmuka analog. Modul kustom
diekspor sebagai SavedModel yang menyertakan model asli, logika prapemrosesan, dan dua tanda tangan penayangan.
Implementasi class modul kustom ditampilkan dalam cuplikan kode berikut:
LABELS_KEY = 'labels'
PROBABILITIES_KEY = 'probabilities'
NUM_LABELS = 5
class ServingModule(tf.Module):
"""
A custom tf.Module that adds image preprocessing and output post processing to
a base TF 2 image classification model from TensorFlow Hub.
"""
def __init__(self, base_model, input_size, output_labels):
super(ServingModule, self).__init__()
self._model = base_model
self._input_size = input_size
self._output_labels = tf.constant(output_labels, dtype=tf.string)
def _decode_and_scale(self, raw_image):
"""
Decodes, crops, and resizes a single raw image.
"""
image = tf.image.decode_image(raw_image, dtype=tf.dtypes.uint8, expand_animations=False)
image_shape = tf.shape(image)
image_height = image_shape[0]
image_width = image_shape[1]
crop_size = tf.minimum(image_height, image_width)
offset_height = ((image_height - crop_size) + 1) // 2
offset_width = ((image_width - crop_size) + 1) // 2
image = tf.image.crop_to_bounding_box(image, offset_height, offset_width, crop_size, crop_size)
image = tf.image.resize(image, [self._input_size, self._input_size])
image = tf.cast(image, tf.uint8)
return image
def _preprocess(self, raw_inputs):
"""
Preprocesses raw inputs as sent by the client.
"""
# A mitigation for https://github.com/tensorflow/tensorflow/issues/28007
with tf.device('/cpu:0'):
images = tf.map_fn(self._decode_and_scale, raw_inputs, dtype=tf.uint8)
images = tf.image.convert_image_dtype(images, tf.float32)
return images
def _postprocess(self, model_outputs):
"""
Postprocess outputs returned by the base model.
"""
probabilities = tf.nn.softmax(model_outputs)
indices = tf.argsort(probabilities, axis=1, direction='DESCENDING')
return {
LABELS_KEY: tf.gather(self._output_labels, indices, axis=-1)[:,:NUM_LABELS],
PROBABILITIES_KEY: tf.sort(probabilities, direction='DESCENDING')[:,:NUM_LABELS]
}
@tf.function(input_signature=[tf.TensorSpec([None, 224, 224, 3], tf.float32)])
def __call__(self, x):
"""
A pass-through to the base model.
"""
return self._model(x)
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def predict_labels(self, raw_images):
"""
Preprocesses inputs, calls the base model
and postprocess outputs from the base model.
"""
# Call the preprocessing handler
images = self._preprocess(raw_images)
# Call the base model
logits = self._model(images)
# Call the postprocessing handler
outputs = self._postprocess(logits)
return outputs
serving_module = ServingModule(model, 224, imagenet_labels)
Cuplikan kode berikut menunjukkan cara model diekspor sebagai SavedModel dengan tanda tangan penayangan yang ditentukan sebelumnya:
...
default_signature = serving_module.__call__.get_concrete_function()
preprocess_signature = serving_module.predict_labels.get_concrete_function()
signatures = {
'serving_default': default_signature,
'serving_preprocess': preprocess_signature
}
tf.saved_model.save(serving_module, model_path, signatures=signatures)
Men-deploy model ke AI Platform Prediction
Saat model diekspor sebagai SavedModel, tugas berikut akan dilakukan:
- Model diupload ke Cloud Storage.
- Objek model dibuat di AI Platform Prediction.
- Versi model dibuat untuk SavedModel.
Cuplikan kode berikut dari notebook menunjukkan perintah yang melakukan tugas ini.
gcloud storage cp {model_path} {GCS_MODEL_LOCATION} --recursive
gcloud ai-platform models create {MODEL_NAME} \
--project {PROJECT_ID} \
--regions {REGION}
MACHINE_TYPE='n1-standard-8'
ACCELERATOR='count=1,type=nvidia-tesla-p4'
gcloud beta ai-platform versions create {MODEL_VERSION} \
--model={MODEL_NAME} \
--origin={GCS_MODEL_LOCATION} \
--runtime-version=2.1 \
--framework=TENSORFLOW \
--python-version=3.7 \
--machine-type={MACHINE_TYPE} \
--accelerator={ACCELERATOR} \
--project={PROJECT_ID}
Perintah ini membuat jenis mesin n1-standard-8 untuk layanan prediksi
model beserta akselerator GPU nvidia-tesla-p4.
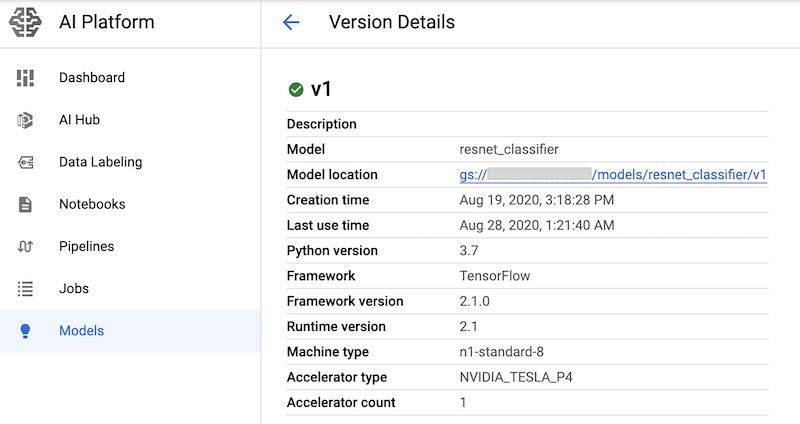
Setelah menjalankan sel notebook yang memiliki perintah ini, Anda dapat memverifikasi bahwa versi model di-deploy dengan melihatnya di halaman AI Platform Models di konsol Google Cloud. Outputnya mirip dengan hal berikut ini:
Membuat metrik Cloud Monitoring
Setelah model disiapkan untuk ditayangkan, Anda dapat mengonfigurasi metrik yang memungkinkan Anda memantau performa penayangan. Kode untuk mengonfigurasi metrik ada di notebook 02-perf-testing.ipynb.
Bagian pertama notebook 02-perf-testing.ipynb membuat metrik berbasis log kustom di Cloud Monitoring menggunakan Python Cloud Logging SDK.
Metrik ini didasarkan pada entri log yang dihasilkan oleh tugas Locust.
Metode
log_stats
menulis entri log ke dalam log Cloud Logging bernama locust.
Setiap entri log menyertakan kumpulan key-value pair dalam format JSON, seperti yang tercantum dalam tabel berikut. Metrik didasarkan pada subset kunci dari entri log.
| Kunci | Deskripsi nilai | Penggunaan |
|---|---|---|
test_id
|
ID pengujian | Memfilter atribut |
model |
Nama model AI Platform Prediction | |
model_version |
Versi model AI Platform Prediction | |
latency
|
Waktu respons persentil ke-95, yang dihitung selama periode geser 10 detik | Nilai metrik |
num_requests |
Jumlah total permintaan sejak pengujian dimulai | |
num_failures |
Jumlah total kegagalan sejak pengujian dimulai | |
user_count |
Jumlah pengguna simulasi | |
rps |
Permintaan per detik |
Cuplikan kode berikut menunjukkan fungsi create_locust_metric di
notebook yang membuat metrik berbasis log kustom.
def create_locust_metric(
metric_name:str,
log_path:str,
value_field:str,
bucket_bounds:List[int]):
metric_path = logging_client.metric_path(PROJECT_ID, metric_name)
log_entry_filter = 'resource.type=global AND logName={}'.format(log_path)
metric_descriptor = {
'metric_kind': 'DELTA',
'value_type': 'DISTRIBUTION',
'labels': [{'key': 'test_id', 'value_type': 'STRING'},
{'key': 'signature', 'value_type': 'STRING'}]}
bucket_options = {
'explicit_buckets': {'bounds': bucket_bounds}}
value_extractor = 'EXTRACT(jsonPayload.{})'.format(value_field)
label_extractors = {
'test_id': 'EXTRACT(jsonPayload.test_id)',
'signature': 'EXTRACT(jsonPayload.signature)'}
metric = logging_v2.types.LogMetric(
name=metric_name,
filter=log_entry_filter,
value_extractor=value_extractor,
bucket_options=bucket_options,
label_extractors=label_extractors,
metric_descriptor=metric_descriptor,
)
try:
logging_client.get_log_metric(metric_path)
print('Metric: {} already exists'.format(metric_path))
except:
logging_client.create_log_metric(parent, metric)
print('Created metric {}'.format(metric_path))
Cuplikan kode berikut menunjukkan cara metode create_locust_metric
dipanggil di notebook untuk membuat empat metrik Locust kustom yang ditampilkan
dalam tabel sebelumnya.
# user count metric
metric_name = 'locust_users'
value_field = 'user_count'
bucket_bounds = [1, 16, 32, 64, 128]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# latency metric
metric_name = 'locust_latency'
value_field = 'latency'
bucket_bounds = [1, 50, 100, 200, 500]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# failure count metric
metric_name = 'num_failures'
value_field = 'num_failures'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# request count metric
metric_name = 'num_requests'
value_field = 'num_requests'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
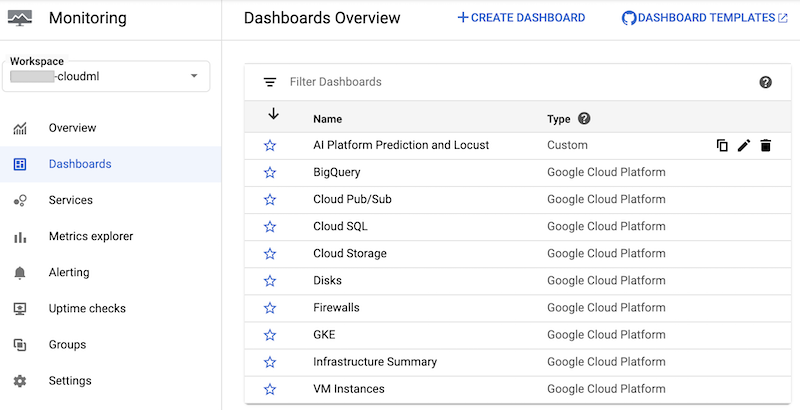
Notebook membuat dasbor Cloud Monitoring kustom yang disebut AI Platform Prediction and Locust. Dasbor menggabungkan metrik Prediksi AI Platform standar dan metrik kustom yang dibuat berdasarkan log Locust.
Untuk informasi selengkapnya, lihat dokumentasi Cloud Logging API.
Dasbor ini dan diagramnya dapat
dibuat secara manual.
Namun, notebook menyediakan cara terprogram untuk membuatnya menggunakan template JSON monitoring-template.json. Kode tersebut menggunakan class
DashboardsServiceClient
untuk memuat template JSON dan membuat dasbor di Cloud Monitoring,
seperti yang ditunjukkan dalam cuplikan kode berikut:
parent = 'projects/{}'.format(PROJECT_ID)
dashboard_template_file = 'monitoring-template.json'
with open(dashboard_template_file) as f:
dashboard_template = json.load(f)
dashboard_proto = Dashboard()
dashboard_proto = ParseDict(dashboard_template, dashboard_proto)
dashboard = dashboard_service_client.create_dashboard(parent, dashboard_proto)
Setelah dasbor dibuat, Anda dapat melihatnya dalam daftar dasbor Cloud Monitoring di Konsol Google Cloud:
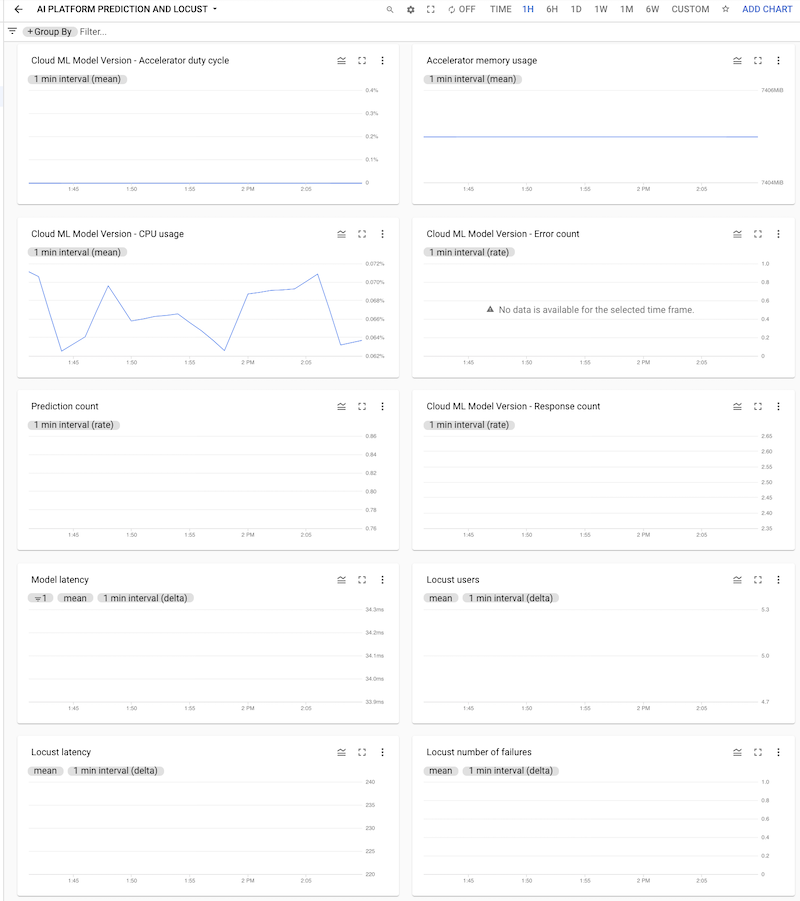
Anda dapat mengklik dasbor untuk membukanya dan melihat diagram. Setiap diagram menampilkan metrik dari AI Platform Prediction atau dari log Locust, seperti yang ditunjukkan dalam screenshot berikut.
Men-deploy pengujian Locust ke cluster GKE
Sebelum men-deploy sistem Locust ke GKE, Anda harus membangun image container Docker yang berisi logika pengujian yang di-build ke dalam file task.py. Image ini
berasal dari
image baseline locust.io
dan digunakan untuk Pod master dan pekerja Locust.
Logika untuk mem-build dan men-deploy ada di notebook di bagian 3. Men-deploy Locust ke cluster GKE. Image dibuat menggunakan kode berikut:
image_uri = 'gcr.io/{}/locust'.format(PROJECT_ID)
!gcloud builds submit --tag {image_uri} locust/locust-image
Proses deployment yang dijelaskan dalam notebook telah ditentukan menggunakan Kustomize. Manifes deployment Kustomize Locust menentukan file berikut yang menentukan komponen:
locust-master. File ini menentukan deployment yang menghosting antarmuka web tempat Anda memulai pengujian dan melihat statistik langsung.locust-worker. File ini menentukan deployment yang menjalankan tugas untuk menguji beban layanan prediksi model ML Anda. Biasanya, beberapa pekerja dibuat untuk menyimulasikan efek beberapa pengguna serentak yang melakukan panggilan ke API layanan prediksi Anda.locust-worker-service. File ini menentukan layanan yang mengakses antarmuka web dilocust-mastermelalui load balancer HTTP.
Anda perlu mengupdate manifes default sebelum cluster di-deploy. Manifes
default terdiri dari
file
kustomization.yaml
dan
patch.yaml; Anda harus melakukan perubahan di kedua file tersebut.
Dalam file kustomization.yaml, lakukan hal berikut:
- Tetapkan nama image Locust kustom. Tetapkan kolom
newNamedi bagianimageske nama image kustom yang Anda build sebelumnya. - Secara opsional, tetapkan jumlah Pod pekerja. Konfigurasi default men-deploy 32 Pod pekerja. Untuk mengubah angka, ubah kolom
countdi bagianreplicas. Pastikan cluster GKE Anda memiliki CPU dalam jumlah yang memadai untuk pekerja Locust. - Tetapkan bucket Cloud Storage untuk konfigurasi pengujian dan file payload. Di bagian
configMapGenerator, pastikan hal berikut ditetapkan:LOCUST_TEST_BUCKET. Tetapkan ini ke nama bucket Cloud Storage yang Anda buat sebelumnya.LOCUST_TEST_CONFIG. Tetapkan ini ke nama file konfigurasi pengujian. Dalam file YAML, nilai ini ditetapkan ketest-config.json, tetapi Anda dapat mengubahnya jika ingin menggunakan nama yang berbeda.LOCUST_TEST_PAYLOAD. Tetapkan ke nama file payload pengujian. Dalam file YAML, nilai ini ditetapkan ketest-payload.json, tetapi Anda dapat mengubahnya jika ingin menggunakan nama yang berbeda.
Dalam file patch.yaml, lakukan hal berikut:
- Secara opsional, ubah node pool yang menghosting master dan pekerja Locust. Jika Anda men-deploy workload Locust ke node pool selain
default-pool, temukan bagianmatchExpressions, lalu di bagianvalues, perbarui nama node pool tempat workload Locust akan di-deploy.
Setelah melakukan perubahan ini, Anda dapat mem-build penyesuaian ke dalam
manifes Kustomize dan menerapkan deployment Locust (locust-master,
locust-worker, dan locust-master-service) ke cluster GKE. Perintah berikut di notebook akan melakukan tugas-tugas ini:
!kustomize build locust/manifests | kubectl apply -f -
Anda dapat memeriksa beban kerja yang di-deploy di konsol Google Cloud. Outputnya mirip dengan hal berikut ini:
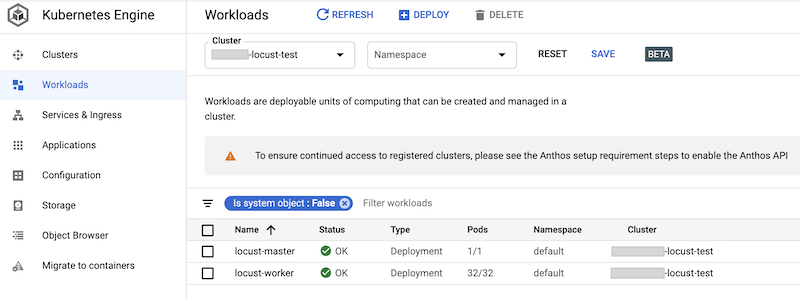
Menerapkan pengujian beban Locust
Tugas pengujian untuk Locust adalah memanggil model yang di-deploy ke AI Platform Prediction.
Tugas ini diterapkan di
class
AIPPClient dalam
modul
task.py yang ada di folder /locust/locust-image/. Cuplikan kode berikut
menunjukkan implementasi class.
class AIPPClient(object):
"""
A convenience wrapper around AI Platform Prediction REST API.
"""
def __init__(self, service_endpoint):
logging.info(
"Setting the AI Platform Prediction service endpoint: {}".format(service_endpoint))
credentials, _ = google.auth.default()
self._authed_session = AuthorizedSession(credentials)
self._service_endpoint = service_endpoint
def predict(self, project_id, model, version, signature, instances):
"""
Invokes the predict method on the specified signature.
"""
url = '{}/v1/projects/{}/models/{}/versions/{}:predict'.format(
self._service_endpoint, project_id, model, version)
request_body = {
'signature_name': signature,
'instances': instances
}
response = self._authed_session.post(url, data=json.dumps(request_body))
return response
Class
AIPPUser
dalam file task.py mewarisi dari
class locust.User
untuk menyimulasikan perilaku pengguna saat memanggil model
AI Platform Prediction. Perilaku ini diterapkan dalam metode predict_task. Metode
on_start dari class AIPPUser mendownload file berikut dari
bucket Cloud Storage yang ditentukan dalam variabel LOCUST_TEST_BUCKET
dalam file task.py:
test-config.json. File JSON ini menyertakan konfigurasi berikut untuk pengujian:test_id,project_id,model, danversion.test-payload.json. File JSON ini menyertakan instance data dalam format yang diharapkan oleh AI Platform Prediction, beserta tanda tangan target.
Kode untuk menyiapkan data pengujian dan konfigurasi pengujian disertakan dalam
notebook 02-perf-testing.ipynb
di bagian 4. Konfigurasi pengujian Locust.
Konfigurasi pengujian dan instance data digunakan sebagai parameter untuk
metode predict di class AIPPClient untuk menguji model target menggunakan
data pengujian yang diperlukan. AIPPUser
Mensimulasikan waktu tunggu
1 hingga 2 detik di antara panggilan dari satu pengguna.
Menjalankan pengujian Locust
Setelah menjalankan sel notebook untuk men-deploy beban kerja Locust ke
cluster GKE, dan setelah membuat, lalu mengupload
file test-config.json dan test-payload.json ke Cloud Storage, Anda
dapat memulai, menghentikan, dan mengonfigurasi pengujian beban Locust baru menggunakan
antarmuka web-nya.
Kode di notebook mengambil URL load balancer eksternal yang
mengekspos antarmuka web menggunakan perintah berikut:
%%bash
IP_ADDRESS=$(kubectl get service locust-master | awk -v col=4 'FNR==2{print $col}')
echo http://$IP_ADDRESS:8089
Untuk melakukan pengujian, lakukan hal berikut:
- Di browser, masukkan URL yang Anda ambil.
Untuk menyimulasikan beban kerja pengujian menggunakan konfigurasi yang berbeda, masukkan nilai ke antarmuka Locust, yang mirip dengan berikut:
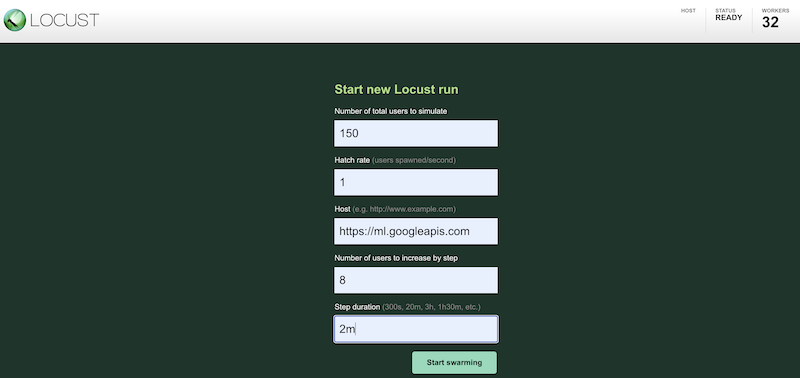
Screenshot sebelumnya menunjukkan nilai konfigurasi berikut:
- Jumlah total pengguna yang akan disimulasikan:
150 - Rasio menetas:
1 - Host:
http://ml.googleapis.com - Jumlah pengguna yang akan ditingkatkan per langkah:
10 - Durasi langkah:
2m
- Jumlah total pengguna yang akan disimulasikan:
Saat pengujian berjalan, Anda dapat memantau pengujian dengan memeriksa diagram Locust. Screenshot berikut menunjukkan cara nilai ditampilkan.
Satu diagram menunjukkan jumlah total permintaan per detik:
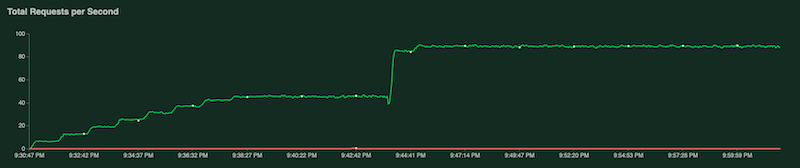
Diagram lain menunjukkan waktu respons dalam milidetik:
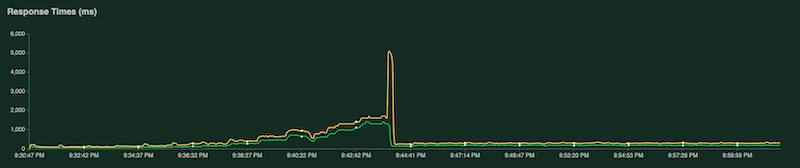
Seperti yang disebutkan sebelumnya, statistik ini juga dicatat ke Cloud Logging sehingga Anda dapat membuat metrik berbasis log Cloud Monitoring kustom.
Mengumpulkan dan menganalisis hasil pengujian
Tugas berikutnya adalah mengumpulkan dan menganalisis metrik Cloud Monitoring yang dihitung dari log hasil sebagai objek DataFrame pandas sehingga Anda dapat memvisualisasikan dan menganalisis hasilnya di notebook. Kode untuk
melakukan tugas ini ada di
notebook 03-analyze-results.ipynb.
Kode ini menggunakan Cloud Monitoring Query Python SDK untuk memfilter dan mengambil nilai metrik, dengan nilai yang diteruskan dalam parameter project_id, test_id, start_time, end_time, model, model_version, dan log_name.
Cuplikan kode berikut menunjukkan metode yang mengambil metrik Prediksi AI Platform dan metrik berbasis log Locust kustom.
import pandas as pd
from google.cloud.monitoring_v3.query import Query
def _get_aipp_metric(metric_type: str, labels: List[str]=[], metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified AIPP metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_resources(model_id=model)
query = query.select_resources(version_id=model_version)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.set_index(df.index.round('T'))
return df
def _get_locust_metric(metric_type: str, labels: List[str]=[],
metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified custom logs-based metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_metrics(log=log_name)
query = query.select_metrics(test_id=test_id)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.apply(lambda row: [metric.mean for metric in row])
df = df.set_index(df.index.round('T'))
return df
Data metrik diambil sebagai objek DataFrame pandas untuk setiap metrik;
setiap frame data kemudian digabungkan menjadi satu objek DataFrame. Objek
DataFrame akhir dengan hasil gabungan akan terlihat seperti berikut di
notebook Anda:
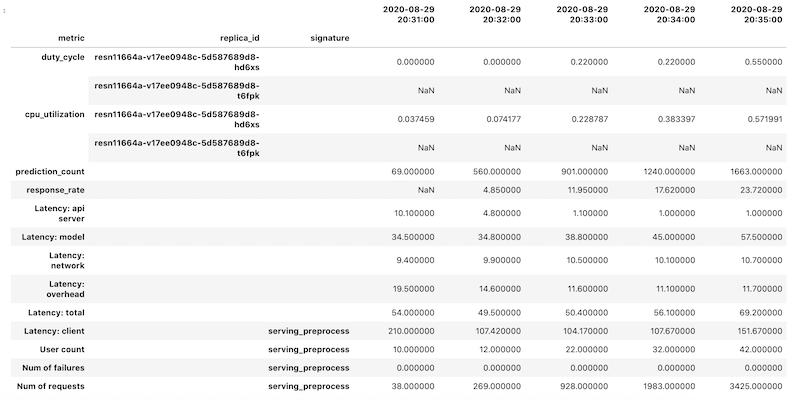
Objek DataFrame yang diambil menggunakan pengindeksan hierarkis untuk nama kolom. Alasannya adalah karena beberapa metrik berisi beberapa deret waktu.
Misalnya, metrik duty_cycle GPU menyertakan deret waktu pengukuran untuk setiap GPU yang digunakan dalam deployment, yang ditunjukkan sebagai replica_id. Tingkat teratas
indeks kolom menampilkan nama untuk setiap metrik. Tingkat kedua adalah
ID replika. Tingkat ketiga menampilkan tanda tangan model. Semua metrik
disejajarkan pada linimasa yang sama.
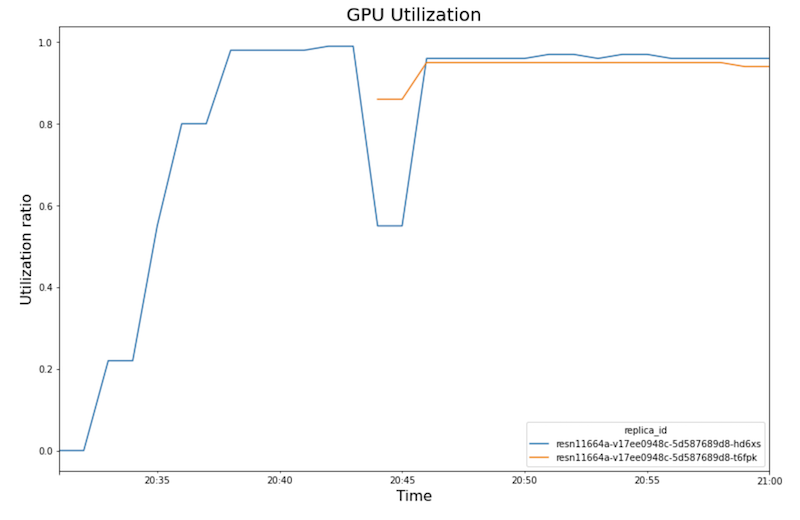
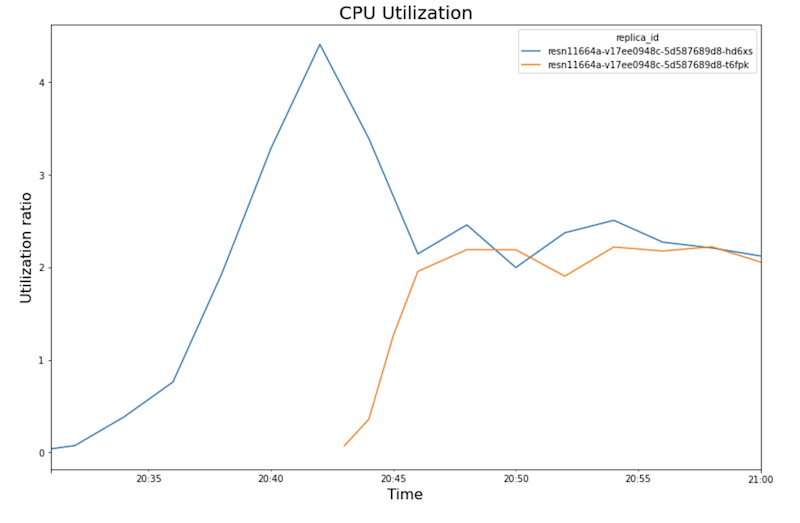
Diagram berikut menunjukkan penggunaan GPU, penggunaan CPU, dan latensi seperti yang Anda lihat di notebook.
Pemakaian GPU:
Pemakaian CPU:
Latensi:
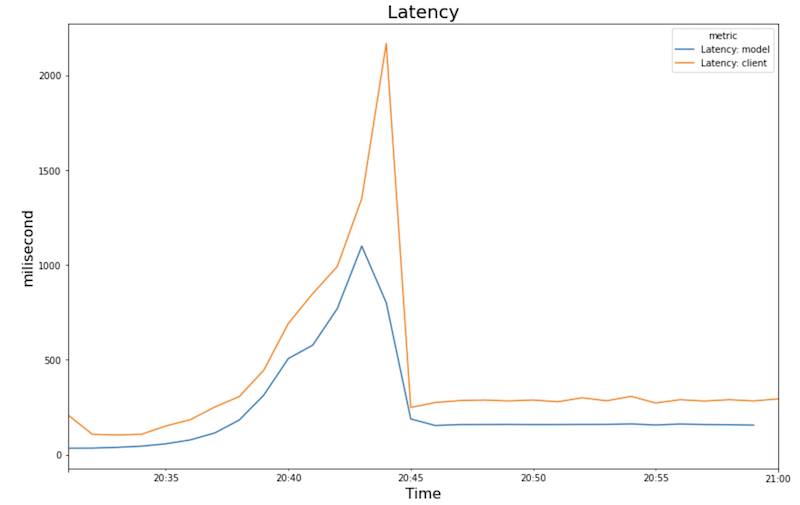
Diagram menunjukkan perilaku dan urutan berikut:
- Seiring meningkatnya beban kerja (jumlah pengguna), penggunaan CPU dan GPU akan meningkat. Akibatnya, latensi meningkat, dan perbedaan antara latensi model dan latensi total meningkat hingga mencapai puncaknya sekitar pukul 20.40.
- Pada pukul 20.40, penggunaan GPU mencapai 100%, sedangkan diagram CPU menunjukkan bahwa
penggunaan mencapai 4 CPU. Contoh ini menggunakan mesin
n1-standard-8dalam pengujian ini, yang memiliki 8 CPU. Dengan demikian, penggunaan CPU mencapai 50%. - Pada tahap ini, penskalaan otomatis akan menambahkan kapasitas: node penayangan baru ditambahkan dengan replika GPU tambahan. Penggunaan replika GPU pertama menurun, dan penggunaan replika GPU kedua meningkat.
- Latensi menurun saat replika baru mulai menayangkan prediksi, yang berkonvergensi sekitar 200 milidetik.
- Penggunaan CPU berkonvergensi sekitar 250% untuk setiap replika—yaitu,
menggunakan 2,5 CPU dari 8 CPU. Nilai ini menunjukkan bahwa Anda dapat menggunakan
mesin
n1-standard-4, bukan mesinn1-standard-8.
Pembersihan
Agar tidak dikenai biaya pada Google Cloud untuk resource yang digunakan dalam dokumen ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus setiap resource.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Jika Anda ingin mempertahankan project Google Cloud, tetapi menghapus resource yang Anda buat, hapus cluster Google Kubernetes Engine dan model AI Platform yang di-deploy.
Langkah selanjutnya
- Pelajari MLOps, continuous delivery, dan pipeline otomatisasi di machine learning.
- Pelajari arsitektur untuk MLOps menggunakan TFX, Kubeflow Pipelines, dan Cloud Build.
- Untuk mengetahui lebih banyak tentang arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.