AI Hypercomputer is a supercomputing system that helps you deploy multi-host artificial intelligence (AI) and machine learning (ML) workloads using GPU machines. The underlying network services you use in the deployment are determined by the GPU machine type that you choose.
This document is intended to help architects, network engineers, and developers understand the underlying network services that relate to the GPU machines. This document assumes you have basic familiarity with cloud networking and distributed computing concepts.
Understanding the GPU machine networking services is the first step to successfully deploying and managing your workloads, and is essential for optimizing performance and goodput. Goodput, or good throughput, measures the effective progress a system makes on an ML training task. This metric offers additional insights when compared to metrics such as total time elapsed or raw throughput rate.
Some GPU machine types feature a distinct, layered hierarchy that optimizes communication at every level. This hierarchy ranges from the data center fabric to AI-optimized clusters and VM instances. The following sections explain these hierarchical components.
GPU network architecture
AI Hypercomputer helps you deploy GPU machines that use a hierarchical, rail-aligned network architecture. This design's predictable, high-performance connectivity minimizes communication overhead, which directly improves goodput by allowing GPUs to spend more time on computation rather than waiting for data.
The rail-aligned arrangement of GPUs consists of three main components:
- Sub-blocks: These are foundational units, which are made up of a group of hosts that are physically co-located on a single rack. A top-of-rack (ToR) switch connects these hosts, enabling extremely efficient, single-hop communication between any two GPUs within the sub-block. RDMA over Converged Ethernet (RoCE) facilitates this direct communication. An enhanced NCCL library that's optimized for Google's rail-aligned topology handles GPU communication collectives.
- Blocks: These are made up of multiple sub-blocks that are interconnected with non-blocking fabric, which enables a high-bandwidth interconnect. Any GPU within a block is reachable in a maximum of two network hops. The system exposes block and sub-block metadata to enable optimal job placement.
- Clusters: These are formed by multiple interconnected blocks, which can scale to thousands of GPUs, and enable you to run large-scale training workloads. Communication across different blocks adds only one additional hop, maintaining high performance and predictability even at massive scale. To enable intelligent, large-scale job placement, cluster-level metadata is also available to orchestrators.
Technologies for GPU-to-GPU communication
GPU machines use a combination of technologies to provide high performance, high throughput, and low latency for workloads. These technologies include RDMA over Converged Ethernet (RoCE), NVIDIA NICs, and Google's datacenter-wide rail-aligned network topology.
These machine types use NVIDIA's NVLink technology to create ultra-high-speed, direct data paths between the NVIDIA NICs on each machine. Additionally, RoCE enables efficient RDMA between GPUs on different machines.
GPU networking stacks
A networking stack is a collection of software protocols, drivers, and layers that work together to implement GPU-to-GPU communication. Different GPU machine types use different networking stacks. The following table defines the networking stacks and their associated machine types:
| Networking stack | Description | GPU machine type |
|---|---|---|
| GPUDirect RDMA | GPUDirect RDMA enables a direct path for data exchange between a GPU and another device. For A4X instances, this networking stack uses RDMA over Converged Ethernet (RoCE). This technology lets peer devices directly read from and write to the GPU's memory, bypassing the CPU to create a more efficient connection for high-performance data exchange. For more information, see Cluster configuration options with GPUDirect RDMA. | |
| GPUDirect-TCPXO | GPUDirect-TCPXO improves on GPUDirect-TCPX by offloading the TCP protocol. Using GPUDirect-TCPXO, the A3 Mega machine type doubles the network bandwidth compared to the A3 High and A3 Edge machine types. For information on maximizing network bandwidth on GKE clusters that use GPUDirect-TCPXO, see Maximize GPU network bandwidth in Standard mode clusters and select the GPUDirect-TCPXO tab. | |
| GPUDirect-TCPX | GPUDirect-TCPX increases network performance by allowing data packet payloads to transfer directly from GPU memory to the network interface. For information on maximizing network bandwidth on GKE clusters that use GPUDirect-TCPX, see Maximize GPU network bandwidth in Standard mode clusters and select the GPUDirect-TCPX tab. |
Host and storage data plane network
A separate network path handles all traffic that is not direct GPU-to-GPU communication. This traffic includes access to Cloud Storage, host-level management, and communication with other Google Cloud services. To manage this traffic, the GPU machine types use Google Titanium NICs.
Titanium NICs offload network processing tasks from the CPU, freeing the CPU to focus on your workloads. This separation ensures that general-purpose traffic and dedicated GPU-to-GPU traffic use different physical interfaces, preventing them from competing for the same system resources.
Multi-VPC environment
All workloads operate within Google Cloud's Virtual Private Cloud (VPC).
High-performance accelerator machines feature a specialized hardware design that uses multiple physical network interfaces to handle different types of traffic. To handle this specialized hardware design, a multi-VPC environment is required, regardless of whether you whether you use Slurm, GKE, or Compute Engine to run your workloads.
The specific multi-VPC configuration depends on the GPU machine type and its networking stack:
A4X, A4, and A3 Ultra with GPUDirect RDMA: These machines use the default VPC network for general-purpose host traffic (gVNIC) and require one additional VPC network for general-purpose host traffic, and one shared VPC network for all GPU-to-GPU traffic. The GPU-traffic VPC must have the RDMA network profile enabled. For more information on this configuration for A4 VMs and A3 Ultra VMs, see Create VPC and subnets.
A3 Mega with GPUDirect-TCPXO: These machines require eight separate VPCs for the GPU NICs, which are dedicated to high-bandwidth communication. For detailed steps on how to complete this configuration, see Create VPCs and subnets.
A3 High with GPUDirect-TCPX: These machines require four separate VPCs for the GPU NICs, which are dedicated to high-bandwidth communication. For detailed steps on how to complete this configuration, see Create VPCs and subnets.
This multi-VPC configuration ensures that storage operations and other system tasks don't compete for bandwidth with critical GPU-to-GPU communications.
The required multi-VPC network configuration that you need to set up differs based on your GPU machine type. For a detailed guide on network arrangement, bandwidth speeds, and NICs for all supported GPU machine types, see Networking and GPU machines.
The following diagram shows the network architecture for a GPU machine, highlighting the separation of general-purpose traffic and dedicated GPU-to-GPU traffic onto different network planes.
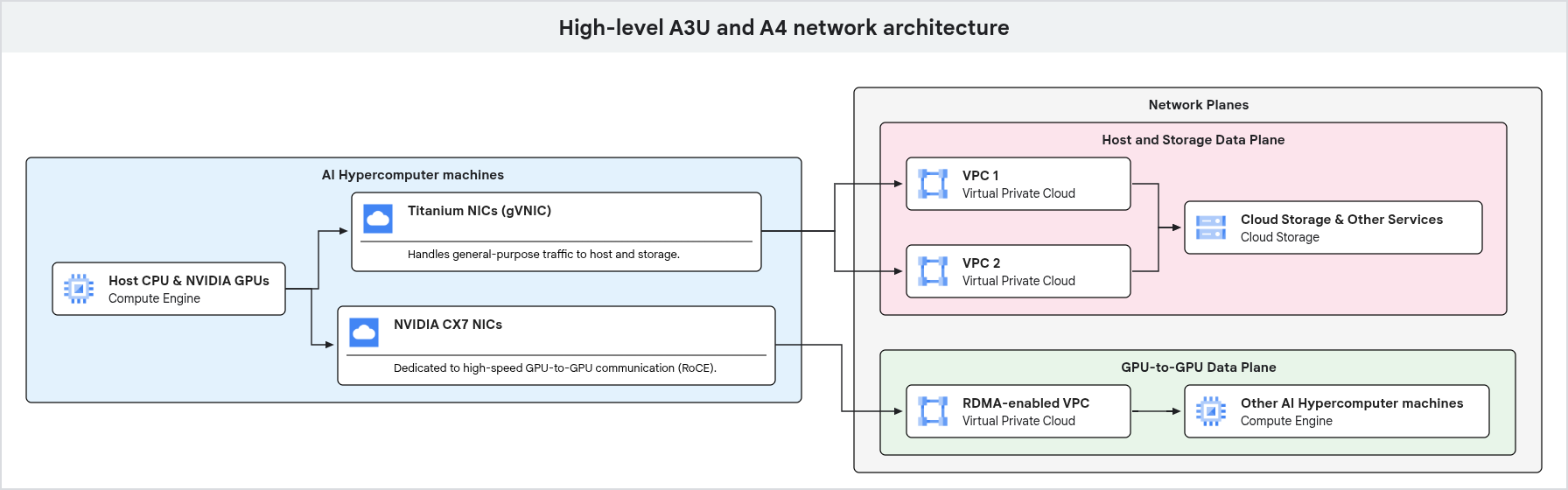
As shown in the preceding diagram, the GPU machines use dedicated network paths for different types of traffic. General-purpose traffic, including management and storage access, flows through Google Titanium NICs which are connected to a VPC. High-performance GPU-to-GPU communication uses separate network interfaces and VPCs, optimized with technologies like RDMA, ensuring high bandwidth and low latency for AI and ML workloads.
Networking libraries and components
To maximize network bandwidth and performance, the following networking libraries and components enable you to use GPUs with Google's networking stack:
- gVNIC: The Google Virtual NIC (gVNIC) is a virtual network interface designed specifically for Compute Engine. gVNIC enhances performance, increases consistency, and reduces noisy neighbor problems. It is supported and recommended on all machine families, machine types, and generations, and is the recommended vNIC for host-to-host communication. For more information, see Using Google Virtual NIC.
- NCCL: The NVIDIA Collective Communications Library (NCCL) provides optimized primitives for collective communication operations. It is specifically designed for multi-GPU and multi-node environments, using NVIDIA GPUs and networking. Run NCCL tests to evaluate the performance of deployed clusters. For more information, see Deploy and run NCCCL test.
- GKE multi-networking: Multi-network support for Pods enables multiple interfaces on nodes and Pods in a GKE cluster. For details on how to set up multi-networking in the context of GPUDirect, see Maximize GPU network bandwidth in Standard mode clusters and Cluster configuration options with GPUDirect RDMA.
For more details on the software stacks that are available, see OS and Docker images.
What's next
- Learn about network services for cluster and VM deployments.
- Learn about the best practices for networking in AI Hypercomputer