Reusing a pipeline component
The machine learning (ML) pipeline components on AI Hub are self-contained sets of code, packaged as container images, that perform a step in the ML workflow. This guide describes how to reuse a component from AI Hub to build a new pipeline.
Prerequisites
Before you reuse a component in your ML pipeline, you must first set up your Kubeflow Pipelines system.
Kubeflow Pipelines is a component of Kubeflow that provides a platform for building and deploying ML workflows. Kubeflow is an open source toolkit for running ML workloads on Kubernetes. Learn more about getting started with Kubeflow.
To set up Kubeflow Pipelines on Google Kubernetes Engine (GKE), choose one of the following options:
- Deploy Kubeflow using the command line. Choose this option if you want to deploy Kubeflow.
- Deploy Kubeflow Pipelines standalone to a cluster. Choose this option if you want to deploy only Kubeflow Pipelines to a GKE cluster.
Reuse a pipeline component
Follow these steps reuse a component from AI Hub in your ML pipeline. This example uses the Scikit-learn Trainer component to create a pipeline that trains a model on the Iris dataset.
To find a pipeline component on AI Hub:
- Open your web browser and go to AI Hub.
- Click Kubeflow pipeline under Category to filter the list of assets to display only pipelines and components.
- Search for scikit-learn, to find pipelines and components that use the scikit-learn framework.
- Find Scikit-learn Trainer in the list of assets, and click the component's name. AI Hub displays a description of the component and information on how to use it. For more information on how to find assets, read the guide to finding assets on AI Hub.
Read the component description to understand the following:
- The component's inputs and outputs.
- The services and APIs that the component depends on.
When you deploy a component that was shared with you, ensure that your Kubeflow Pipelines system can access the component's container image. In order for Kubeflow to access the component's container image, one of the following must be true:
- The component's container image must be publicly accessible.
- Or the container image must be registered to the same Google Cloud project as the Kubeflow Pipelines clusters on deployment.
- Or you must grant your Kubeflow Pipelines cluster's service account access to your shared Container Registry.
You can build a pipeline in a Python file or in a Jupyter notebook. Check that your development environment has the Kubeflow Pipelines SDK installed:
$ which dsl-compile
The response should be something like this:
/[PATH_TO_YOUR_USER_BIN]/miniconda2/envs/mlpipeline/bin/dsl-compile
If dsl-compile was not found, follow the instructions in the guide to installing the Kubeflow Pipelines SDK to set up your ML pipeline development environment.
Create a Python file or Jupyter notebook build your pipeline in. The rest of this document will refer to this as your pipeline code file.
Import the packages required to use the Kubeflow Pipelines SDK to create a pipeline.
from kfp import compiler import kfp.dsl as dsl import kfp.components as comp
Load the component. You can either load it by URL or by downloading the component's zip file from AI Hub.
To load the component by its URL, click Copy URL under Use this asset on the component's page in AI Hub. In your pipeline code file, load the component by its URL:
scikit_learn_train = comp.load_component_from_url('[COMPONENT_URL_FROM_AI_HUB]')
To load the component from a file, click Download under Use this asset on the component's page in AI Hub. In your pipeline code file, load the component from its zip file.
scikit_learn_train = comp.load_component_from_file('[PATH_TO_COMPONENT_ZIP_FILE]')
Create the pipeline as a Python function. In this example, you create a pipeline with a single step that trains a scikit-learn model. To learn more about building pipelines, see the Kubeflow Pipelines guide to building pipelines.
# Use the @dsl.pipeline decorator to add a name and description to your pipeline definition. @dsl.pipeline( name='Scikit-learn Trainer', description='Trains a Scikit-learn model') # Use a function to define the pipeline. def scikit_learn_trainer( training_data_path='gs://cloud-samples-data/ml-engine/iris/classification/train.csv', test_data_path='gs://cloud-samples-data/ml-engine/iris/classification/evaluate.csv', output_dir='/tmp', estimator_name='GradientBoostingClassifier', hyperparameters='n_estimators 100 max_depth 4'): # Use the component you loaded in the previous step to create a pipeline task. sklearn_op = scikit_learn_train(training_data_path, test_data_path, output_dir, estimator_name, hyperparameters)Compile your pipeline and save it as a zip file:
compiler.Compiler().compile(scikit_learn_trainer, '[PATH_TO_YOUR_NEW_PIPELINE]')
You have reused a component from AI Hub to create a new Kubeflow pipeline.
Deploy your pipeline
Follow these steps to deploy the pipeline you created to your Kubeflow Pipelines system.
- Open your Kubeflow environment and click Pipeline Dashboard to access the Kubeflow Pipelines UI.
- Click Upload pipeline to open the Upload and name your
pipeline form.
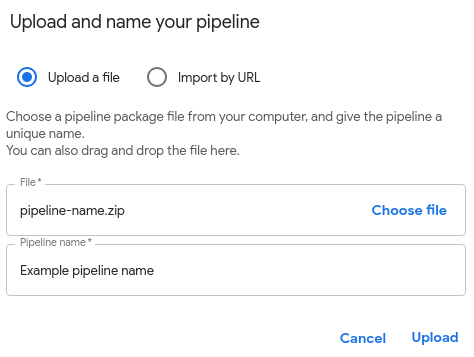
Supply the following information to the form:
- File: Click Choose file to open the file selector. Navigate to the pipeline's zip file, select the pipeline, and click Open.
- Pipeline name: A short description that will help you identify the pipeline in Kubeflow Pipelines.
Click Upload to load the pipeline to Kubeflow Pipelines.
To learn more about running Kubeflow pipeline components, read the quickstart to running a Kubeflow pipeline.
What's next
- Read a blog post on getting started with Kubeflow Pipelines.
- Explore the pipeline samples.
- Learn more about Kubeflow pipelines and components by reading the guide to understanding Kubeflow pipelines and components.
- Understand important concepts and terms by reading the introduction to AI Hub.