Arquitectura
En el siguiente diagrama, se muestra la arquitectura de alto nivel de una canalización sin servidores de extracción, carga y transformación (ELT) con Workflows.

En el diagrama anterior, considera una plataforma de venta minorista que recopila eventos de ventas de forma periódica como archivos de varias tiendas y, luego, los escribe en un bucket de Cloud Storage. Los eventos se usan para proporcionar métricas empresariales mediante la importación y el procesamiento en BigQuery. Esta arquitectura proporciona un sistema de organización confiable y sin servidores para importar tus archivos a BigQuery y se divide en los siguientes dos módulos:
- Lista de archivos: Mantiene la lista de archivos sin procesar agregados a un bucket de Cloud Storage en una colección de Firestore.
Este módulo funciona a través de una función de Cloud Run que se activa por un evento de almacenamiento de Finalización del objeto, que se genera cuando se agrega un archivo nuevo al bucket de Cloud Storage. El nombre del archivo se agrega al array
filesde la colección llamadanewen Firestore. Flujo de trabajo: Ejecuta los flujos de trabajo programados. Cloud Scheduler activa un flujo de trabajo que ejecuta una serie de pasos según una sintaxis basada en YAML para organizar la carga y, luego, transformar los datos en BigQuery mediante una llamada a funciones de Cloud Run. Los pasos del flujo de trabajo llaman a las funciones de Cloud Run para ejecutar las siguientes tareas:
- Crear y, luego, iniciar un trabajo de carga de BigQuery.
- Consultar el estado del trabajo de carga.
- Crear y, luego, iniciar el trabajo de consulta de transformación.
- Consultar el estado del trabajo de transformación.
Usar las transacciones para mantener la lista de archivos nuevos en Firestore ayuda a garantizar que no se pierda ningún archivo cuando un flujo de trabajo los importe a BigQuery. Las ejecuciones separadas del flujo de trabajo se hacen idempotentes mediante el almacenamiento de metadatos y estados de trabajo en Firestore.
Objetivos
- Crea una base de datos de Firestore.
- Configurar un activador de funciones de Cloud Run para hacer un seguimiento de los archivos que se agregaron al bucket de Cloud Storage en Firestore.
- Implementar funciones de Cloud Run para ejecutar y supervisar trabajos de BigQuery
- Implementar y ejecutar un flujo de trabajo para automatizar el proceso.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Cuando finalices las tareas que se describen en este documento, puedes borrar los recursos que creaste para evitar que continúe la facturación. Para obtener más información, consulta Cómo realizar una limpieza.
Antes de comenzar
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Build, Cloud Run functions, Identity and Access Management, Resource Manager, and Workflows APIs.
Ve a la página Bienvenida y anota el ID del proyecto para usarlo en un paso posterior.
In the Google Cloud console, activate Cloud Shell.
Prepare el entorno
Para preparar tu entorno, crea una base de datos de Firestore, clona los ejemplos de código del repositorio de GitHub, crea recursos con Terraform, edita el archivo YAML de Workflows y, luego, instala los requisitos del generador de archivos.
Para crear una base de datos de Firestore, sigue estos pasos:
En la consola de Google Cloud, ve a la página Firestore.
Haz clic en Seleccionar modo nativo.
En el menú Selecciona una ubicación, selecciona la región en la que deseas alojar la base de datos de Firestore. Te recomendamos que elijas una región cercana a tu ubicación física.
Haga clic en Create database.
En Cloud Shell, clona el repositorio de código fuente:
cd $HOME && git clone https://github.com/GoogleCloudPlatform/workflows-demos cd workflows-demos/workflows-bigquery-loadEn Cloud Shell, crea los siguientes recursos con Terraform:
terraform init terraform apply \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approveReemplaza lo siguiente:
PROJECT_ID: El ID del proyecto de Google Cloud.REGION: Es una ubicación geográfica específica de Google Cloud para alojar tus recursos, por ejemplo,us-central1ZONE: es una ubicación dentro de una región para alojar tus recursos, por ejemplo,us-central1-b.
Deberías ver un mensaje similar al siguiente:
Apply complete! Resources: 7 added, 0 changed, 1 destroyed.Terraform puede ayudarte a crear, cambiar y actualizar la infraestructura a gran escala de forma segura y predecible. Los siguientes recursos se crean en tu proyecto:
- Cuentas de servicio con los privilegios necesarios para garantizar un acceso seguro a tus recursos
- Un conjunto de datos de BigQuery llamado
serverless_elt_datasety una tabla llamadaword_countpara cargar los archivos entrantes. - Un bucket de Cloud Storage llamado
${project_id}-ordersbucketpara los archivos de entrada de etapa de pruebas. - Las siguientes cinco funciones de Cloud Run:
file_add_handleragrega el nombre de los archivos que se agregan al bucket de Cloud Storage a la colección de Firestore.create_jobcrea un trabajo de carga nuevo de BigQuery y asocia los archivos de la colección de Firebase con el trabajo.create_querycrea un nuevo trabajo de consulta de BigQuery.poll_bigquery_jobobtiene el estado de un trabajo de BigQuery.run_bigquery_jobinicia un trabajo de BigQuery.
Obtén las URLs de las funciones de Cloud Run
create_job,create_query,poll_jobyrun_bigquery_jobque implementaste en el paso anterior.gcloud functions describe create_job | grep url gcloud functions describe poll_bigquery_job | grep url gcloud functions describe run_bigquery_job | grep url gcloud functions describe create_query | grep url
El resultado es similar a este:
url: https://REGION-PROJECT_ID.cloudfunctions.net/create_job url: https://REGION-PROJECT_ID.cloudfunctions.net/poll_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/run_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/create_query
Anota estas URLs, ya que las necesitarás cuando implementes tu flujo de trabajo.
Crea e implementa un flujo de trabajo
En Cloud Shell, abre el archivo de origen del flujo de trabajo,
workflow.yaml:Reemplaza lo siguiente:
CREATE_JOB_URL: la URL de la función para crear un trabajo nuevo.POLL_BIGQUERY_JOB_URL: la URL de la función que consulta el estado de un trabajo en ejecución.RUN_BIGQUERY_JOB_URL: la URL de la función para iniciar un trabajo de carga de BigQuery.CREATE_QUERY_URL: la URL de la función que inicia un trabajo de consulta de BigQuery.BQ_REGION: La región de BigQuery en la que se almacenan los datos, por ejemplo,USBQ_DATASET_TABLE_NAME: Es el nombre de la tabla del conjunto de datos de BigQuery en el formatoPROJECT_ID.serverless_elt_dataset.word_count.
Implementa el archivo
workflow:gcloud workflows deploy WORKFLOW_NAME \ --location=WORKFLOW_REGION \ --description='WORKFLOW_DESCRIPTION' \ --service-account=workflow-runner@PROJECT_ID.iam.gserviceaccount.com \ --source=workflow.yamlReemplaza lo siguiente:
WORKFLOW_NAME: el nombre único del flujo de trabajo.WORKFLOW_REGION: La región en la que se implementa el flujo de trabajo, por ejemplo,us-central1WORKFLOW_DESCRIPTION: la descripción del flujo de trabajo.
Crea un entorno virtual de Python 3 y, luego, instala los requisitos para el generador de archivos:
sudo apt-get install -y python3-venv python3 -m venv env . env/bin/activate cd generator pip install -r requirements.txt
Genera archivos para importar
La secuencia de comandos gen.py de Python genera contenido aleatorio en formato Avro. El esquema es el mismo que el de la tabla word_count de BigQuery. Estos archivos Avro se copian en el bucket de Cloud Storage especificado.
En Cloud Shell, genera los archivos:
python gen.py -p PROJECT_ID \
-o PROJECT_ID-ordersbucket \
-n RECORDS_PER_FILE \
-f NUM_FILES \
-x FILE_PREFIX
Reemplaza lo siguiente:
RECORDS_PER_FILE: la cantidad de registros en un solo archivo.NUM_FILES: la cantidad total de archivos que se subiránFILE_PREFIX: el prefijo de los nombres de los archivos generados.
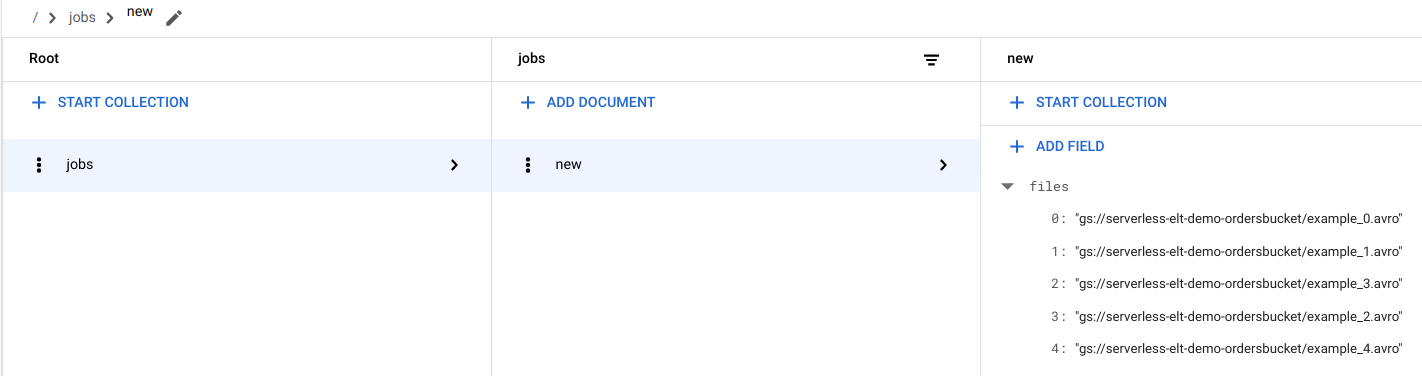
Visualiza entradas de archivos en Firestore
Cuando se copian los archivos en Cloud Storage, se activa la función handle_new_file de Cloud Run. Esta función agrega la lista de archivos al array de la lista en el documento new de la colección jobs de Firestore.
Para ver la lista de archivos, ve a la página Datos de Firestore en la consola de Google Cloud.
Activa el flujo de trabajo
Los flujos de trabajo vinculan una serie de tareas sin servidores desde Google Cloud y los servicios de API. Los pasos individuales de este flujo de trabajo se ejecutan como funciones de Cloud Run y el estado se almacena en Firestore. Todas las llamadas a las funciones de Cloud Run se autentican mediante la cuenta de servicio del flujo de trabajo.
En Cloud Shell, ejecuta el flujo de trabajo como se indica a continuación:
gcloud workflows execute WORKFLOW_NAME
En el siguiente diagrama, se muestran los pasos que se usaron en el flujo de trabajo:

El flujo de trabajo se divide en dos partes: el flujo de trabajo principal y el flujo de trabajo secundario. El flujo de trabajo principal controla la creación de trabajos y la ejecución condicional mientras que el flujo de trabajo secundario ejecuta un trabajo de BigQuery. El flujo de trabajo realiza las siguientes operaciones:
- La función de Cloud Run
create_jobcrea un objeto de trabajo nuevo, obtiene la lista de archivos agregados a Cloud Storage desde el documento de Firestore y asocia los archivos con el trabajo de carga. Si no hay archivos para cargar, la función no crea un trabajo nuevo. - La función de Cloud Run
create_querytoma la consulta que se debe ejecutar junto con la región de BigQuery en la que se debe ejecutar la consulta. La función crea el trabajo en Firestore y muestra el ID del trabajo. - La función
run_bigquery_jobde Cloud Run obtiene el ID del trabajo que se debe ejecutar y, luego, llama a la API de BigQuery para enviar el trabajo. - En lugar de esperar a que el trabajo se complete en la función
Cloud Run, puedes consultar de forma periódica el estado del trabajo.
- La función de Cloud Run
poll_bigquery_jobproporciona el estado del trabajo. Se llama de forma reiterada hasta que se completa el trabajo. - Para agregar un retraso entre las llamadas a la función de Cloud Run
poll_bigquery_job, se llama a una rutinasleepdesde Workflows.
- La función de Cloud Run
Visualiza el estado del trabajo
Puedes ver la lista de archivos y el estado del trabajo.
En la consola de Google Cloud, ve a la página Datos de Firestore.
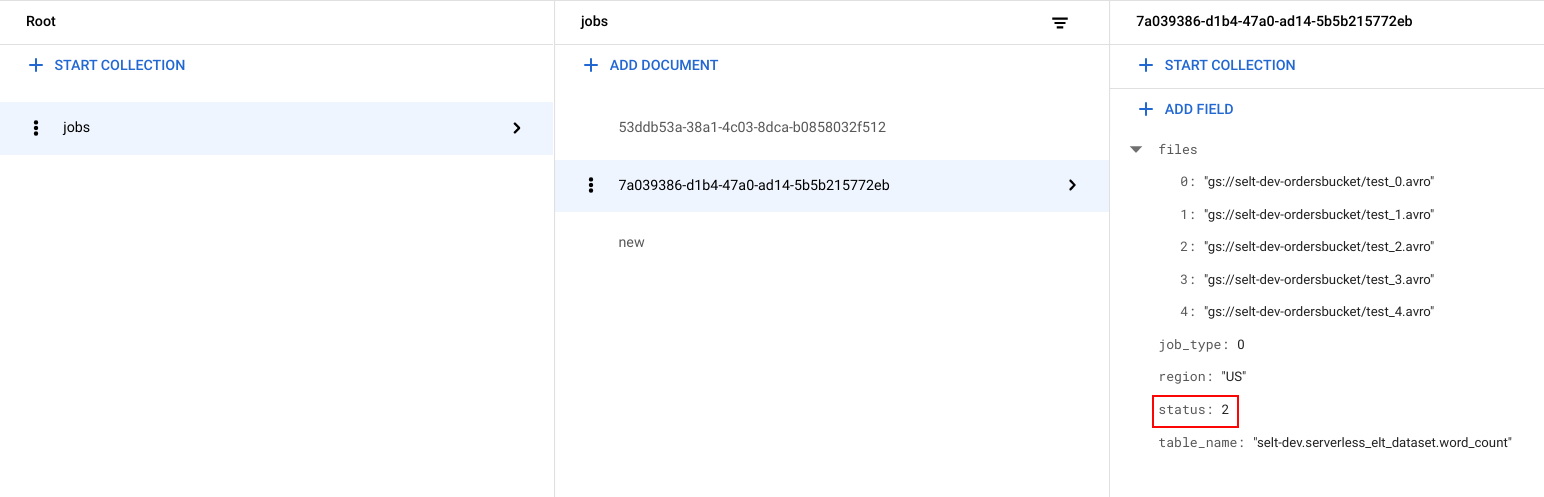
Se genera un identificador único (UUID) para cada trabajo. Para ver los
job_typeystatus, haz clic en el ID de trabajo. Cada trabajo puede tener uno de los siguientes tipos y estados:job_type: Es el tipo de trabajo que ejecuta el flujo de trabajo con uno de los siguientes valores:- 0: Carga datos en BigQuery.
- 1: Ejecuta una consulta en BigQuery.
status: Es el estado actual del trabajo con uno de los siguientes valores:- 0: Se creó el trabajo, pero no se inició.
- 1: El trabajo se está ejecutando.
- 2: El trabajo se completó correctamente.
- 3: Hubo un error y el trabajo no se completó correctamente.
El objeto de trabajo también contiene atributos de metadatos, como la región del conjunto de datos de BigQuery, el nombre de la tabla de BigQuery y, si es un trabajo de consulta, la cadena de consulta que se ejecuta.
Visualizar datos en BigQuery
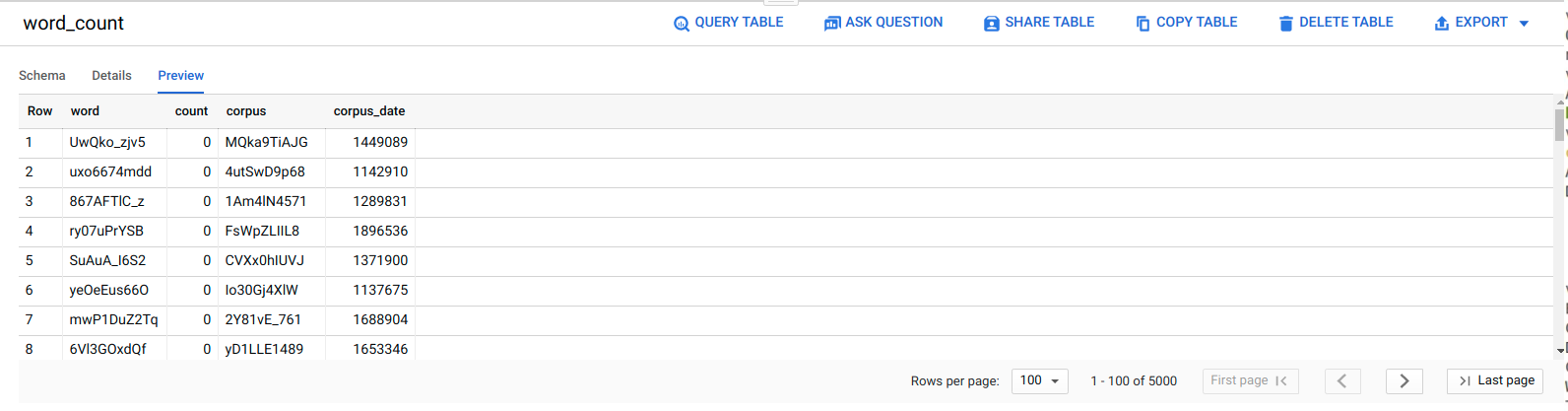
Para confirmar que el trabajo de ELT se realizó correctamente, verifica que los datos aparezcan en la tabla.
En la consola de Google Cloud, ve a la página Editor de BigQuery.
Haz clic en la tabla
serverless_elt_dataset.word_count.Haz clic en la pestaña Vista previa.
Programa el flujo de trabajo
Para ejecutar el flujo de trabajo de forma periódica, puedes usar Cloud Scheduler.
Realiza una limpieza
La manera más fácil de eliminar la facturación es borrar el proyecto de Google Cloud que creaste para el instructivo. Como alternativa, puedes borrar los recursos individuales.Borra los recursos individuales
En Cloud Shell, quita todos los recursos creados mediante Terraform:
cd $HOME/bigquery-workflows-load terraform destroy \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approve
En la consola de Google Cloud, ve a la página Datos de Firestore.
Junto a Trabajos, haz clic en Menú y selecciona Borrar.
Borra el proyecto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
¿Qué sigue?
- Para aprender más sobre BigQuery, consulta la documentación de BigQuery.
- Aprende a compilar canalizaciones de aprendizaje automático personalizadas sin servidores.
- Para obtener más información sobre las arquitecturas de referencia, los diagramas y las prácticas recomendadas, explora Cloud Architecture Center.