아키텍처
다음 다이어그램에서는 Workflows를 사용하는 서버리스 추출, 로드, 변환(ELT) 파이프라인의 개략적인 아키텍처를 보여줍니다.

앞의 다이어그램에서 여러 저장소에서 파일과 같은 영업 이벤트를 주기적으로 수집한 후 파일을 Cloud Storage 버킷에 기록하는 소매업 플랫폼이 있다고 가정해보세요. 이러한 이벤트는 BigQuery에서 가져오기 및 처리를 위한 비즈니스 측정항목을 제공하기 위해 사용됩니다. 이 아키텍처는 파일을 BigQuery로 가져오기 위해 신뢰할 수 있는 서버리스 조정 시스템을 제공합니다. 이 아키텍처는 다음 2개 모듈로 구분됩니다.
- 파일 목록: Firestore 컬렉션에서 Cloud Storage 버킷에 추가된 처리되지 않은 파일 목록을 유지 관리합니다.
이 모듈은 새 파일이 Cloud Storage 버킷에 추가될 때 생성되는 객체 완료 스토리지 이벤트에서 트리거하는 Cloud Run 함수를 통해 작동합니다. 파일 이름은 Firestore에서
new라는 컬렉션의files배열에 추가됩니다. 워크플로: 예약된 워크플로를 실행합니다. Cloud Scheduler는 YAML 기반 구문에 따라 일련의 단계를 실행하여 로딩을 조정한 후 Cloud Run 함수를 호출하여 BigQuery의 데이터를 변환하는 워크플로를 트리거합니다. 워크플로의 단계는 Cloud Run 함수를 호출하여 다음 태스크를 실행합니다.
- BigQuery 로드 작업을 만들고 시작합니다.
- 로드 작업 상태를 폴링합니다.
- 쿼리 변환 작업을 만들고 시작합니다.
- 변환 작업 상태를 폴링합니다.
트랜잭션을 사용하여 Firestore에서 새 파일 목록을 유지 관리하면 워크플로가 BigQuery로 가져올 때 파일이 누락되지 않도록 보장하는 데 도움이 됩니다. 워크플로의 개별 실행은 작업 메타데이터 및 상태를 Firestore에 저장하여 멱등적으로 됩니다.
개발 환경 준비
환경을 준비하려면 Firestore 데이터베이스를 만들고, GitHub 저장소에서 코드 샘플을 클론하고, Terraform을 사용하여 리소스를 만들고, Workflows YAML 파일을 수정하고, 파일 생성기에 요구사항을 설치합니다.
Firestore 데이터베이스를 만들기 위해 다음을 수행합니다.
Google Cloud 콘솔에서 Firestore 페이지로 이동합니다.
기본 모드 선택을 클릭합니다.
위치 선택 메뉴에서 Firestore 데이터베이스를 호스팅할 리전을 선택합니다. 실제 위치와 가까운 리전을 선택하는 것이 좋습니다.
데이터베이스 만들기를 클릭합니다.
Cloud Shell에서 소스 저장소를 클론합니다.
cd $HOME && git clone https://github.com/GoogleCloudPlatform/workflows-demos cd workflows-demos/workflows-bigquery-loadCloud Shell에서 Terraform을 사용하여 다음 리소스를 만듭니다.
terraform init terraform apply \ -var project_id=PROJECT_ID \ -var region=REGION \ -var zone=ZONE \ --auto-approve다음을 바꿉니다.
PROJECT_ID: Google Cloud 프로젝트 IDREGION: 리소스를 호스팅할 특정 Google Cloud 지리적 위치(예:us-central1)ZONE: 리전 내에서 리소스를 호스팅할 위치(예:us-central1-b)
다음과 유사한 메시지가 표시됩니다.
Apply complete! Resources: 7 added, 0 changed, 1 destroyed.Terraform은 대규모로 안전하고 예측 가능한 방식으로 인프라를 만들고, 변경, 업그레이드할 수 있게 해줍니다. 다음 리소스가 프로젝트에 생성됩니다.
- 리소스에 대한 보안 액세스를 보장하는 데 필요한 권한이 있는 서비스 계정
- 수신되는 파일을 로드하기 위한
serverless_elt_dataset라는 BigQuery 데이터 세트 및word_count라는 테이블 - 입력 파일을 스테이징하기 위한
${project_id}-ordersbucket이라는 Cloud Storage 버킷 - 다음 Cloud Run 함수 5개:
file_add_handler는 Cloud Storage 버킷에 추가된 파일의 이름을 Firestore 컬렉션에 추가합니다.create_job은 새 BigQuery 로드 작업을 만들고 Firebase 컬렉션의 파일을 작업과 연결합니다.create_query는 새 BigQuery 쿼리 작업을 만듭니다.poll_bigquery_job은 BigQuery 작업의 상태를 가져옵니다.run_bigquery_job은 BigQuery 작업을 시작합니다.
이전 단계에서 배포한
create_job,create_query,poll_job,run_bigquery_jobCloud Run 함수의 URL을 가져옵니다.gcloud functions describe create_job | grep url gcloud functions describe poll_bigquery_job | grep url gcloud functions describe run_bigquery_job | grep url gcloud functions describe create_query | grep url
출력은 다음과 비슷합니다.
url: https://REGION-PROJECT_ID.cloudfunctions.net/create_job url: https://REGION-PROJECT_ID.cloudfunctions.net/poll_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/run_bigquery_job url: https://REGION-PROJECT_ID.cloudfunctions.net/create_query
워크플로를 배포할 때 필요하므로 이러한 URL을 기록해 둡니다.
워크플로 생성 및 배포
Cloud Shell에서 워크플로의 소스 파일
workflow.yaml을 엽니다.다음을 바꿉니다.
CREATE_JOB_URL: 새 작업을 만들기 위한 함수의 URL입니다.POLL_BIGQUERY_JOB_URL: 실행 중인 작업의 상태를 폴링하기 위한 함수의 URL입니다.RUN_BIGQUERY_JOB_URL: BigQuery 로드 작업을 시작하기 위한 함수의 URL입니다.CREATE_QUERY_URL: BigQuery 쿼리 작업을 시작하기 위한 함수의 URL입니다.BQ_REGION: 데이터가 저장되는 BigQuery 리전입니다(예:US).BQ_DATASET_TABLE_NAME:PROJECT_ID.serverless_elt_dataset.word_count형식의 BigQuery 데이터 세트 테이블 이름입니다.
workflow파일을 배포합니다.gcloud workflows deploy WORKFLOW_NAME \ --location=WORKFLOW_REGION \ --description='WORKFLOW_DESCRIPTION' \ --service-account=workflow-runner@PROJECT_ID.iam.gserviceaccount.com \ --source=workflow.yaml다음을 바꿉니다.
WORKFLOW_NAME: 워크플로의 고유한 이름입니다.WORKFLOW_REGION: 워크플로가 배포되는 리전입니다(예:us-central1).WORKFLOW_DESCRIPTION: 워크플로에 대한 설명입니다.
Python 3 가상 환경을 만들고 파일 생성기의 요구사항을 설치합니다.
sudo apt-get install -y python3-venv python3 -m venv env . env/bin/activate cd generator pip install -r requirements.txt
가져올 파일 생성
gen.py Python 스크립트는 임의 콘텐츠를 Avro 형식으로 생성합니다. 스키마는 BigQuery word_count 테이블과 동일합니다. 이러한 Avro 파일은 지정된 Cloud Storage 버킷에 복사됩니다.
Cloud Shell에서 파일을 생성합니다.
python gen.py -p PROJECT_ID \
-o PROJECT_ID-ordersbucket \
-n RECORDS_PER_FILE \
-f NUM_FILES \
-x FILE_PREFIX
다음을 바꿉니다.
RECORDS_PER_FILE: 단일 파일의 레코드 수입니다.NUM_FILES: 업로드할 총 파일 수입니다.FILE_PREFIX: 생성된 파일의 프리픽스입니다.
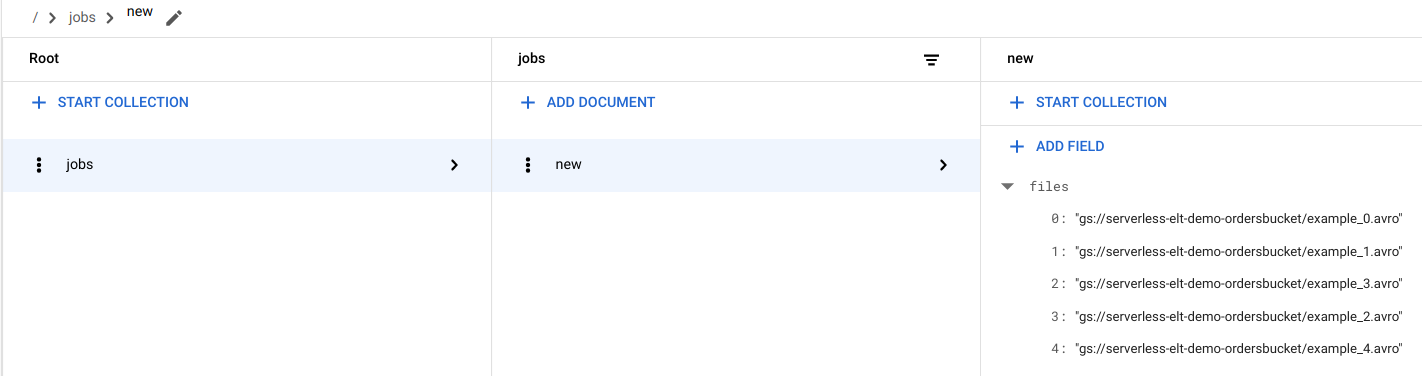
Firestore에서 파일 항목 보기
파일을 Cloud Storage에 복사하면 handle_new_file Cloud Run 함수가 트리거됩니다. 이 함수는 Firestore jobs 컬렉션에서 new 문서에 있는 파일 목록 배열에 파일 목록을 추가합니다.
파일 목록을 보려면 Google Cloud 콘솔에서 Firestore 데이터 페이지로 이동합니다.
워크플로 트리거
워크플로는Google Cloud 및 API 서비스에서 일련의 서버리스 작업을 함께 연결합니다. 이 워크플로의 개별 단계는 Cloud Run 함수로 실행되며 상태는 Firestore에 저장됩니다. Cloud Run 함수에 대한 모든 호출은 워크플로 서비스 계정을 통해 인증됩니다.
Cloud Shell에서 워크플로를 실행합니다.
gcloud workflows execute WORKFLOW_NAME
다음 다이어그램은 워크플로에 사용된 단계를 보여줍니다.

워크플로는 기본 워크플로와 하위 워크플로의 두 부분으로 나뉩니다. 기본 워크플로는 작업 만들기 및 조건부 실행을 처리하며, 하위 워크플로는 BigQuery 작업을 실행합니다. 워크플로는 다음 작업을 수행합니다.
create_jobCloud Run 함수는 새 작업 객체를 만들고 Firestore 문서에서 Cloud Storage에 추가된 파일 목록을 가져오며 파일을 로드 작업과 연결합니다. 로드할 파일이 없으면 함수가 새 작업을 만들지 않습니다.create_queryCloud Run 함수는 쿼리를 실행해야 하는 BigQuery 리전과 함께 실행해야 하는 쿼리를 사용합니다. 이 함수는 Firestore에 작업을 만들고 작업 ID를 반환합니다.run_bigquery_jobCloud Run 함수는 실행해야 하는 작업의 ID를 가져온 후 BigQuery API를 호출하여 작업을 제출합니다.- Cloud Run 함수에서 작업이 완료될 때까지 기다리는 대신 주기적으로 작업 상태를 폴링할 수 있습니다.
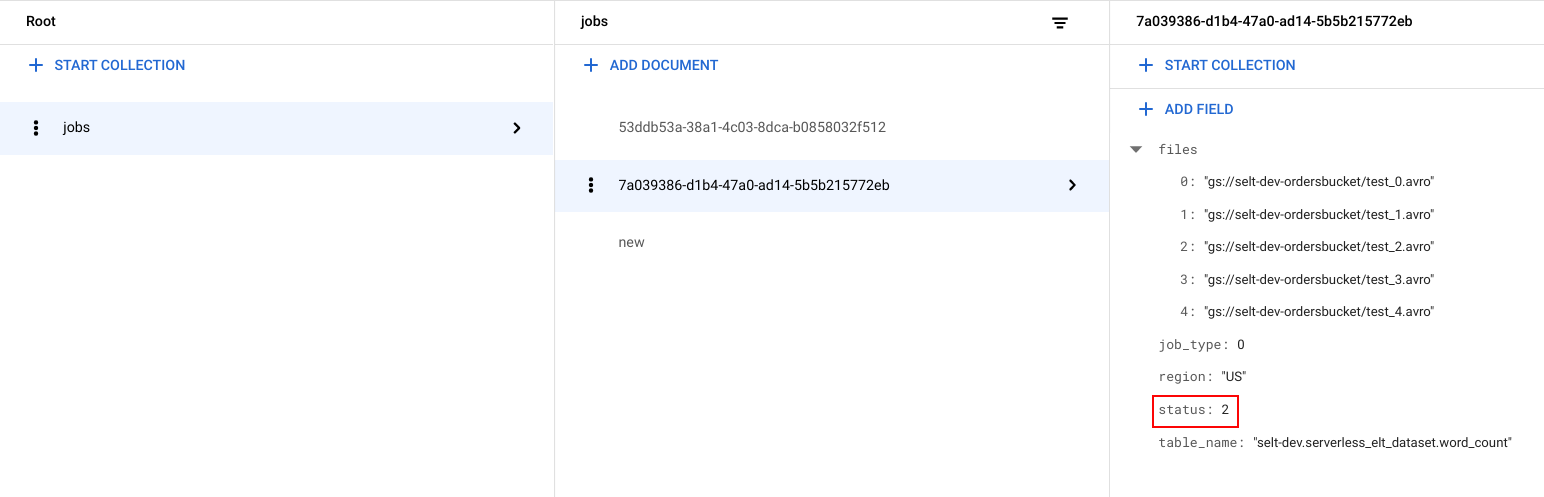
작업 상태 보기
파일 목록과 작업 상태를 확인할 수 있습니다.
Google Cloud 콘솔에서 Firestore 데이터 페이지로 이동합니다.
작업마다 고유 식별자(UUID)가 생성됩니다.
job_type및status를 보려면 작업 ID를 클릭합니다. 각 작업에는 다음 유형 및 상태 중 하나가 포함될 수 있습니다.job_type: 다음 값 중 하나를 사용하여 워크플로에서 실행되는 작업의 유형입니다.- 0: BigQuery에 데이터를 로드합니다.
- 1: BigQuery에서 쿼리를 실행합니다.
status: 다음 값 중 하나를 포함하는 작업의 현재 상태입니다.- 0: 작업이 생성되었지만 시작되지 않았습니다.
- 1: 작업이 실행되는 중입니다.
- 2: 작업 실행이 성공적으로 완료되었습니다.
- 3: 오류가 발생하여 작업이 성공적으로 완료되지 않았습니다.
또한 작업 객체에 BigQuery 데이터 세트의 리전, BigQuery 테이블의 이름과 같은 메타데이터 속성이 포함되며, 쿼리 작업의 경우 실행되는 쿼리 문자열이 포함됩니다.
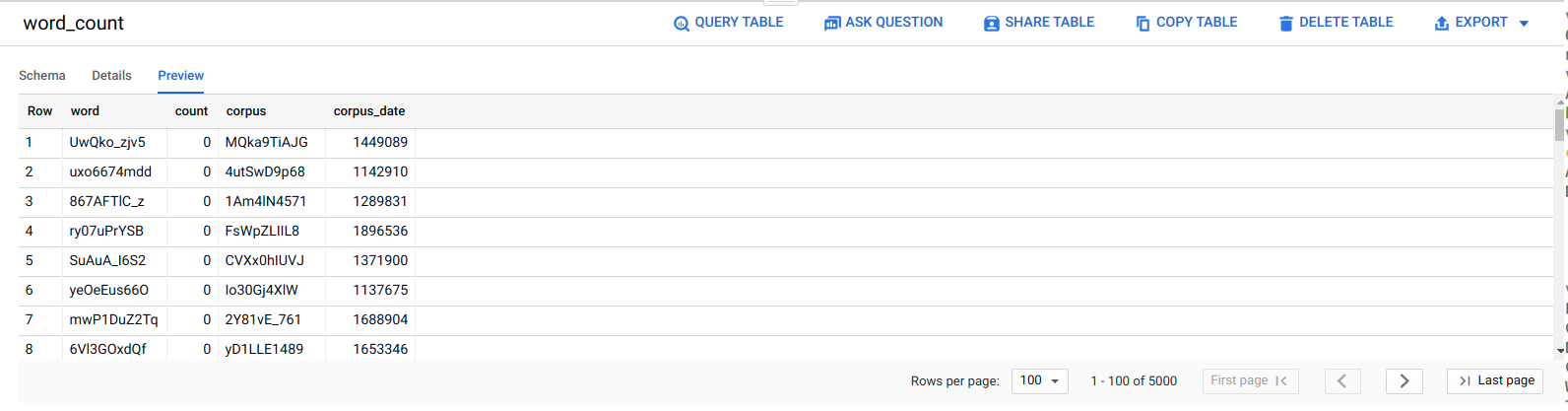
BigQuery에서 데이터 보기
ELT 작업이 성공했는지 확인하려면 데이터가 테이블에 표시되는지 확인합니다.
Google Cloud 콘솔에서 BigQuery 편집기 페이지로 이동합니다.
serverless_elt_dataset.word_count테이블을 클릭합니다.미리보기 탭을 클릭합니다.
워크플로 예약
예약에 따라 워크플로를 주기적으로 실행하려면 Cloud Scheduler를 사용할 수 있습니다.