機能リスト
現在、Vision API では次の機能を使用できます。
| すべての機能タイプ |

|
- 画像の光学式文字認識(OCR)によって、テキストを認識し、マシンコード化されたテキストへ変換します。画像内の UTF-8 テキストを識別して抽出します。
- 画像: 大きな画像内のテキストのスパース領域向けに最適化されます。
- レスポンス: テキストとして識別された単語、境界ボックス、
textAnnotations のリストに加え、OCR で検出されたテキスト(fullTextAnnotation)の構造的階層を返します。
- 抽出されたテキスト構造の階層:
- TextAnnotation -> Page -> Block -> Paragraph -> Word -> Symbol
- Page 以降の各構造要素には、検出された言語、区切りなどの独自のプロパティがある場合があります。
- サポートされている言語: 現在サポートされている言語、マッピングされている言語、試験運用版の言語で動作します。
- 機能の列挙値:
TEXT_DETECTION
|

|
- ファイル(PDF / TIFF)または高密度テキスト画像用の光学式文字認識(OCR)によって、高密度テキストを認識し、マシンコード化されたテキストに変換します。
- ファイル: ドキュメント ファイル(PDF / TIFF)向けに最適化されます。
- 画像: 画像内(文書の画像)の高密度テキスト領域と、手書き文字を含む画像向けに最適化されます。
- レスポンス: OCR で検出されたテキスト(
fullTextAnnotation)の構造的階層を返します。
- 抽出されたテキスト構造の階層:
- TextAnnotation -> Page -> Block -> Paragraph -> Word -> Symbol
- Page 以降の各構造要素には、検出された言語、区切りなどの独自のプロパティがある場合があります。
- サポートされている言語: 現在サポートされている言語、マッピングされている言語、試験運用版の言語で動作します。
- 機能の列挙値:
DOCUMENT_TEXT_DETECTION
DOCUMENT_TEXT_DETECTION と TEXT_DETECTION の両方がリクエストされた場合に優先されます。
|

|
- ランドマークの名称、信頼スコア、ランドマークの画像の境界ボックスを提供します。
- 検出されたエンティティの座標を返します。
|

|
- ファイル内のロゴで識別されたエンティティに関するテキスト形式の説明、信頼スコア、境界ポリゴンを提供します。
|
|
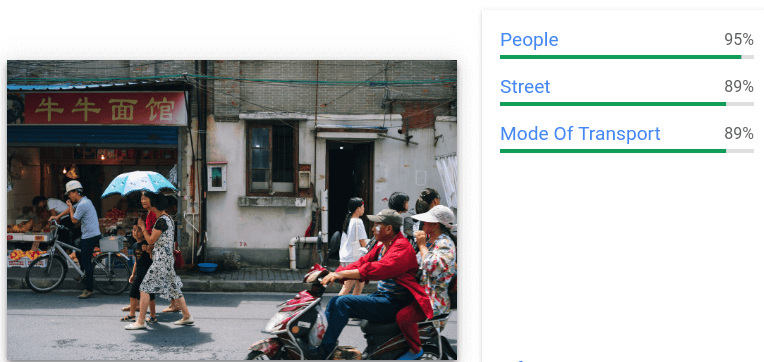
- 画像の一般化されたラベルを提供します。
- ラベルごとにテキスト形式の説明、信頼スコア、トピカリティ評価を返します。
|

|
- 画像のドミナント カラーを返します。
- 各色は RGBA 色空間で表され、信頼スコアを持ち、色 [0, 1] が占めるピクセルの割合を表示します。
|

|
|
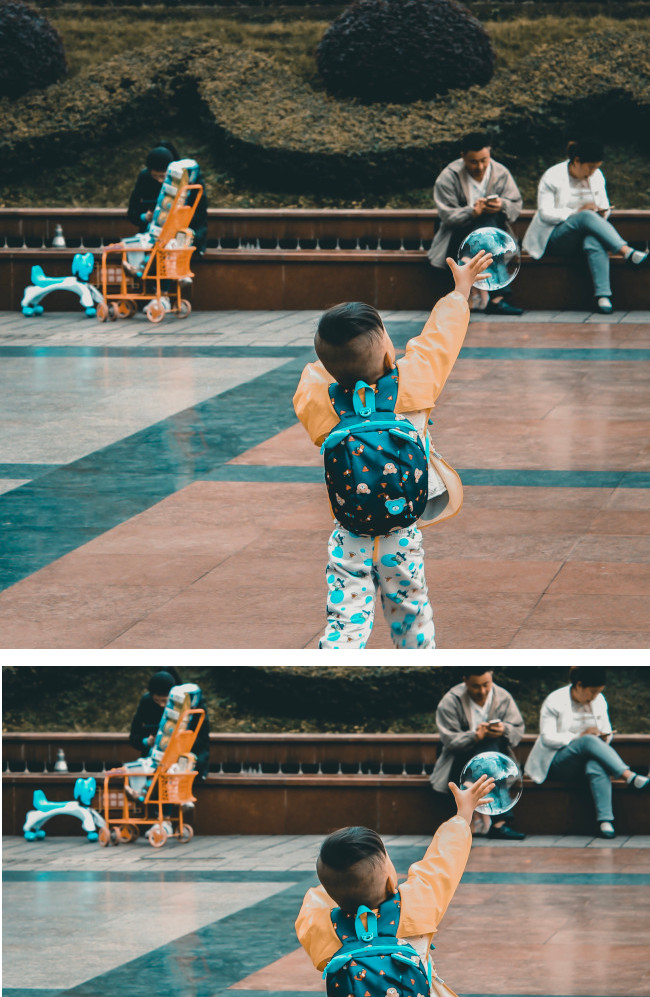
|
- 切り抜いた画像の境界ポリゴン、信頼スコア、元の画像に対するこの注目領域の重要度の比率をリクエストごとに提示します。
- 1 つの画像に対して最大 16 の画像比率値(幅 : 高さ)を指定できます。
|

|
- 一連の関連するウェブ コンテンツを画像に提供します。
- 次の情報を返します。
- ウェブ エンティティ: ウェブ上の類似する画像から推定されるエンティティ(ラベル / 説明)。
- 完全一致画像: インターネット上で完全に一致した、あらゆるサイズの画像の URL リスト。
- 部分一致画像: 元の画像の切り抜きバージョンなど、主な特徴を共有する画像の URL リスト。
- 画像が一致するページ: 上述の条件を満たす画像を含むウェブページ(ページ URL、ページのタイトル、一致する画像 URL で識別)のリスト。
- 視覚的に類似した画像: 元の画像と一部の特徴を共有する画像の URL リスト。
- 最良の推測ラベル: リクエストされた画像のトピックに関する最良の推測。インターネット上の類似画像から推測されます。
|
|
- 不適切なコンテンツ カテゴリ(
adult、spoof、medical、violence、racy)の可能性評価を提供します。
- 可能性評価は、
UNKNOWN、VERY_UNLIKELY、UNLIKELY、POSSIBLE、LIKELY、VERY_LIKELY の 6 つの異なる値で表されます。
|

|
- 顔を境界ポリゴンで特定し、目、耳、鼻、口など、顔にある特定の「ランドマーク」を対応する信頼値とともに識別します。
- 感情(喜び、悲しみ、怒り、驚き)の可能性評価と一般的な画像プロパティ(露出不明、ぼかし、帽子あり)を返します。
- 可能性評価は、
UNKNOWN、VERY_UNLIKELY、UNLIKELY、POSSIBLE、LIKELY、VERY_LIKELY の 6 つの異なる値で表されます。
- 特定の個人の顔認証はサポートされていません。
|
1. 画像クレジット: Nikolay Vorobyev、Unsplash より(アノテーション入り)↩
2. 画像クレジット: Robert Scoble(CC BY 2.0、アノテーション入り)↩
3. 画像クレジット: Alex Knight、Unsplash より↩
4. 画像クレジット: Jeremy Bishop、Unsplash より↩
5. 画像クレジット: Bogdan Dada、Unsplash より(アノテーション入り)↩
6. 画像クレジット: Yasmin Dangor、Unsplashより(元の画像と切り抜いた画像を表示)↩
7. 画像クレジット: Quinten de Graaf、Unsplash より抜粋↩
特に記載のない限り、このページのコンテンツはクリエイティブ・コモンズの表示 4.0 ライセンスにより使用許諾されます。コードサンプルは Apache 2.0 ライセンスにより使用許諾されます。詳しくは、Google Developers サイトのポリシーをご覧ください。Java は Oracle および関連会社の登録商標です。
最終更新日 2025-11-01 UTC。
[[["わかりやすい","easyToUnderstand","thumb-up"],["問題の解決に役立った","solvedMyProblem","thumb-up"],["その他","otherUp","thumb-up"]],[["わかりにくい","hardToUnderstand","thumb-down"],["情報またはサンプルコードが不正確","incorrectInformationOrSampleCode","thumb-down"],["必要な情報 / サンプルがない","missingTheInformationSamplesINeed","thumb-down"],["翻訳に関する問題","translationIssue","thumb-down"],["その他","otherDown","thumb-down"]],["最終更新日 2025-11-01 UTC。"],[],[]]