Objectifs du tutoriel
Dans ce tutoriel, vous allez télécharger un modèle TensorFlow Lite personnalisé et exporté à partir d'AutoML Vision Edge. Vous exécuterez ensuite une application iOS prédéfinie qui utilise le modèle pour détecter plusieurs objets dans une image (avec des cadres de délimitation) et pour fournir des étiquettes personnalisées correspondant aux catégories des objets.
Objectifs
Dans ce tutoriel de présentation détaillé, vous allez utiliser du code pour effectuer les opérations suivantes :
- Exécuter un modèle Edge de détection d'objets AutoML Vision dans une application iOS à l'aide de l'interpréteur TF Lite
Avant de commencer
Cloner le dépôt Git
À l'aide de la ligne de commande, exécutez la commande suivante pour cloner le dépôt Git ci-dessous :
git clone https://github.com/tensorflow/examples.git
Accédez au répertoire ios du clone local du dépôt (examples/lite/examples/object_detection/ios/). Vous exécuterez tous les exemples de code suivants à partir de ce répertoire ios :
cd examples/lite/examples/object_detection/ios
Prérequis
- Git doit être installé.
- Versions iOS compatibles : iOS 12.0 ou version ultérieure.
Configurer l'application iOS
Générer et ouvrir le fichier de l'espace de travail
Pour commencer à configurer l'application iOS d'origine, vous devez d'abord générer le fichier de l'espace de travail à l'aide du logiciel requis :
Accédez au dossier
iossi vous ne l'avez pas déjà fait :cd examples/lite/examples/object_detection/ios
Installez le pod pour générer le fichier de l'espace de travail :
pod install
Si vous avez déjà installé ce pod, utilisez la commande suivante :
pod update
Après avoir généré le fichier de l'espace de travail, vous pouvez ouvrir le projet avec Xcode. Pour ouvrir le projet via la ligne de commande, exécutez la commande suivante à partir du répertoire
ios:open ./ObjectDetection.xcworkspace
Créer un identifiant unique et l'application
Avec ObjectDetection.xcworkspace ouvert dans Xcode, vous devez d'abord remplacer l'identifiant du bundle (ID du bundle) par une valeur unique.
Sélectionnez l'élément de projet
ObjectDetectionsupérieur dans le navigateur de projet sur la gauche.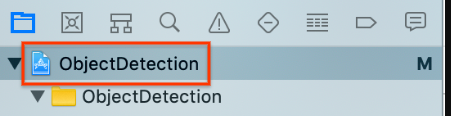
Assurez-vous d'avoir sélectionné Targets > ObjectDetection (Cibles > ObjectDetection).
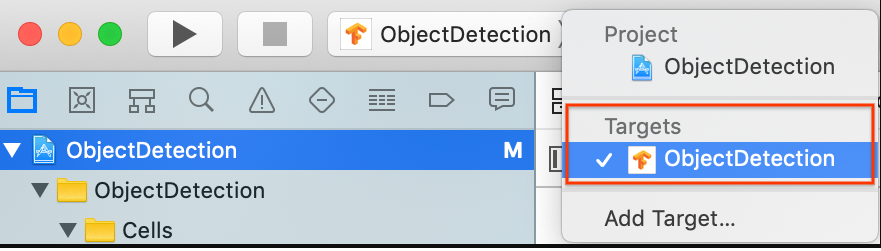
Dans la section General > Identity (Général > Identité), remplacez le champ "Bundle Identifier" (Identifiant de groupe) par une valeur unique. Le style préféré est la notation du nom de domaine inverse.
Dans la section General > Signing (Général > Signature), sous Identity (Identité), sélectionnez une équipe dans le menu déroulant. Cette valeur est fournie à partir de votre ID de développeur.
Connectez un appareil iOS à votre ordinateur. Une fois l'appareil détecté, sélectionnez-le dans la liste des appareils.
Après avoir spécifié toutes les modifications de configuration, créez l'application dans Xcode à l'aide de la commande suivante : Commande+B.
Exécuter l'application d'origine
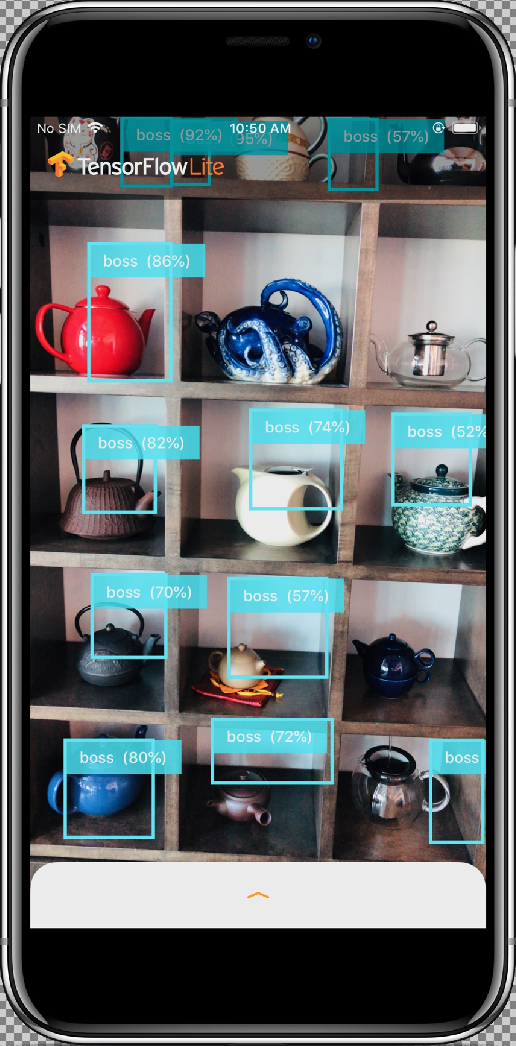
L'exemple d'application est une application d'appareil photo qui détecte en continu les objets (cadres de délimitation et étiquettes) dans les images de l'appareil photo situé à l'arrière de votre appareil, à l'aide d'un modèle MobileNet SSD entraîné et quantifié sur l'ensemble de données COCO.
Ces instructions vous guident dans la conception et l'exécution de la version de démonstration sur un appareil iOS.
Les fichiers du modèle sont téléchargés via des scripts dans Xcode lors de la création et de l'exécution. Vous ne devez pas effectuer de procédure pour télécharger explicitement des modèles TF Lite dans le projet.
Avant d'insérer votre modèle personnalisé, testez la version de référence de l'application qui utilise le modèle MobileNet de base entraîné.
Pour lancer l'application dans le simulateur, sélectionnez le bouton de lecture
 dans l'angle supérieur gauche de la fenêtre Xcode.
dans l'angle supérieur gauche de la fenêtre Xcode.
Une fois que vous avez autorisé l'application à accéder à votre appareil photo en sélectionnant le bouton Allow (Autoriser), celle-ci démarre la détection et l'annotation en direct. Les objets sont détectés et marqués d'un cadre de délimitation et d'une étiquette dans chaque image de l'appareil photo.
Déplacez votre appareil vers différents objets de votre environnement et vérifiez que l'application détecte correctement les images.
Exécuter l'application personnalisée
Modifiez l'application de sorte qu'elle utilise votre modèle réentraîné avec des catégories d'image d'objets personnalisées.
Ajouter les fichiers de modèle au projet
Le projet de démonstration est configuré pour rechercher deux fichiers dans le répertoire ios/objectDetection/model :
detect.tflitelabelmap.txt
Pour remplacer ces deux fichiers par vos versions personnalisées, exécutez la commande suivante :
cp tf_files/optimized_graph.lite ios/objectDetection/model/detect.tflite cp tf_files/retrained_labels.txt ios/objectDetection/model/labelmap.txt
Exécuter l'application
Pour relancer l'application sur votre appareil iOS, sélectionnez le bouton de lecture ![]() dans l'angle supérieur gauche de la fenêtre Xcode.
dans l'angle supérieur gauche de la fenêtre Xcode.
Pour tester les modifications, déplacez l'appareil photo vers différents objets pour voir les prédictions en temps réel.
Les résultats doivent ressembler à ce qui suit :
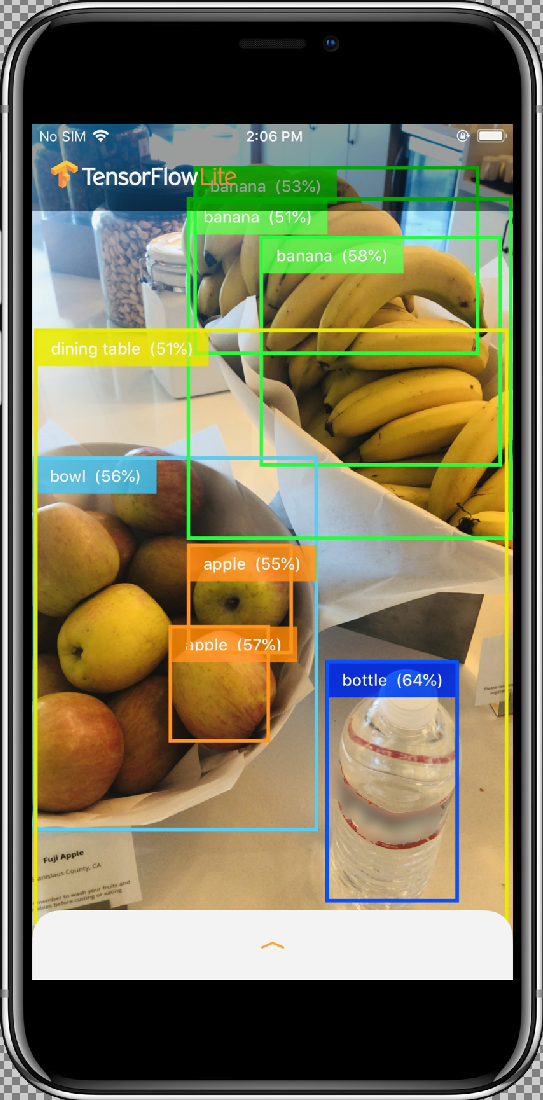
Fonctionnement
Maintenant que l'application est en cours d'exécution, examinez le code propre à TensorFlow Lite.
Pod TensorFlow Lite
Cette application utilise un CocoaPod TFLite précompilé. Le fichier Podfile inclut le CocoaPod dans le projet :
# Uncomment the next line to define a global platform for your project platform :ios, '12.0' target 'ObjectDetection' do # Comment the next line if you're not using Swift and don't want to use dynamic frameworks use_frameworks! # Pods for ObjectDetection pod 'TensorFlowLiteSwift' end
L'intégralité du code d'interface avec TF Lite est contenu dans le fichier ModelDataHandler.swift. Cette classe gère tous les prétraitements de données et réalise des appels pour exécuter l'inférence sur une image donnée en invoquant le code Interpreter.
Elle formate ensuite les inférences obtenues et renvoie les N premiers résultats pour une inférence réussie.
Explorer le code
Le premier bloc de code présentant un certain intérêt (après les importations nécessaires) est celui des déclarations de propriété. Les paramètres inputShape du modèle tfLite (batchSize, inputChannels, inputWidth, inputHeight) figurent dans tflite_metadata.json. Vous obtiendrez ce fichier lors de l'exportation du modèle tflite. Pour plus d'informations, consultez la page d'aide Exportation des modèles Edge.
L'exemple de tflite_metadata.json ressemble au code suivant :
{
"inferenceType": "QUANTIZED_UINT8",
"inputShape": [
1, // This represents batch size
512, // This represents image width
512, // This represents image Height
3 //This represents inputChannels
],
"inputTensor": "normalized_input_image_tensor",
"maxDetections": 20, // This represents max number of boxes.
"outputTensorRepresentation": [
"bounding_boxes",
"class_labels",
"class_confidences",
"num_of_boxes"
],
"outputTensors": [
"TFLite_Detection_PostProcess",
"TFLite_Detection_PostProcess:1",
"TFLite_Detection_PostProcess:2",
"TFLite_Detection_PostProcess:3"
]
}
...
Paramètres du modèle :
Remplacez les valeurs ci-dessous conformément au fichier tflite_metadata.json de votre modèle.
let batchSize = 1 //Number of images to get prediction, the model takes 1 image at a time let inputChannels = 3 //The pixels of the image input represented in RGB values let inputWidth = 300 //Width of the image let inputHeight = 300 //Height of the image ...
init
La méthode init, qui crée Interpreter avec le chemin d'accès Model et InterpreterOptions, alloue ensuite de la mémoire pour l'entrée du modèle.
init?(modelFileInfo: FileInfo, labelsFileInfo: FileInfo, threadCount: Int = 1) {
let modelFilename = modelFileInfo.name
// Construct the path to the model file.
guard let modelPath = Bundle.main.path(forResource: modelFilename,ofType: modelFileInfo.extension)
// Specify the options for the `Interpreter`.
var options = InterpreterOptions()
options.threadCount = threadCount
do {
// Create the `Interpreter`.
interpreter = try Interpreter(modelPath: modelPath, options: options)
// Allocate memory for the model's input `Tensor`s.
try interpreter.allocateTensors()
}
super.init()
// Load the classes listed in the labels file.
loadLabels(fileInfo: labelsFileInfo)
}
…
runModel
La méthode runModel ci-dessous :
- Ajuste l'image d'entrée au format pour lequel le modèle est entraîné.
- Supprime le composant alpha du tampon d'image pour obtenir les données RVB.
- Copie les données RVB dans le Tensor d'entrée.
- Exécute l'inférence en invoquant
Interpreter. - Obtient le résultat de l'interpréteur.
- Formate la sortie.
func runModel(onFrame pixelBuffer: CVPixelBuffer) -> Result? {
Rogne l'image sur le plus grand carré du centre et l'ajuste aux dimensions du modèle :
let scaledSize = CGSize(width: inputWidth, height: inputHeight)
guard let scaledPixelBuffer = pixelBuffer.resized(to: scaledSize) else
{
return nil
}
...
do {
let inputTensor = try interpreter.input(at: 0)
Supprime le composant alpha du tampon d'image pour obtenir les données RVB :
guard let rgbData = rgbDataFromBuffer(
scaledPixelBuffer,
byteCount: batchSize * inputWidth * inputHeight * inputChannels,
isModelQuantized: inputTensor.dataType == .uInt8
) else {
print("Failed to convert the image buffer to RGB data.")
return nil
}
Copie les données RVB vers l'entrée Tensor :
try interpreter.copy(rgbData, toInputAt: 0)
Exécute l'inférence en appelant Interpreter :
let startDate = Date()
try interpreter.invoke()
interval = Date().timeIntervalSince(startDate) * 1000
outputBoundingBox = try interpreter.output(at: 0)
outputClasses = try interpreter.output(at: 1)
outputScores = try interpreter.output(at: 2)
outputCount = try interpreter.output(at: 3)
}
Formate les résultats :
let resultArray = formatResults(
boundingBox: [Float](unsafeData: outputBoundingBox.data) ?? [],
outputClasses: [Float](unsafeData: outputClasses.data) ?? [],
outputScores: [Float](unsafeData: outputScores.data) ?? [],
outputCount: Int(([Float](unsafeData: outputCount.data) ?? [0])[0]),
width: CGFloat(imageWidth),
height: CGFloat(imageHeight)
)
...
}
Filtre tous les résultats avec un score de confiance inférieur au seuil et renvoie les N premiers résultats triés par ordre décroissant :
func formatResults(boundingBox: [Float], outputClasses: [Float],
outputScores: [Float], outputCount: Int, width: CGFloat, height: CGFloat)
-> [Inference]{
var resultsArray: [Inference] = []
for i in 0...outputCount - 1 {
let score = outputScores[i]
Filtre les résultats dont le score de confiance est inférieur au seuil :
guard score >= threshold else {
continue
}
Récupère les noms de classe de sortie pour les classes détectées à partir de la liste des étiquettes :
let outputClassIndex = Int(outputClasses[i])
let outputClass = labels[outputClassIndex + 1]
var rect: CGRect = CGRect.zero
Traduit le cadre de délimitation détecté en CGRect.
rect.origin.y = CGFloat(boundingBox[4*i])
rect.origin.x = CGFloat(boundingBox[4*i+1])
rect.size.height = CGFloat(boundingBox[4*i+2]) - rect.origin.y
rect.size.width = CGFloat(boundingBox[4*i+3]) - rect.origin.x
Les angles détectés correspondent aux dimensions du modèle. Nous adaptons donc rect par rapport aux dimensions réelles de l'image.
let newRect = rect.applying(CGAffineTransform(scaleX: width, y: height))
Récupère la couleur attribuée à la classe :
let colorToAssign = colorForClass(withIndex: outputClassIndex + 1)
let inference = Inference(confidence: score,
className: outputClass,
rect: newRect,
displayColor: colorToAssign)
resultsArray.append(inference)
}
// Sort results in descending order of confidence.
resultsArray.sort { (first, second) -> Bool in
return first.confidence > second.confidence
}
return resultsArray
}
CameraFeedManager
CameraFeedManager.swift gère toutes les fonctionnalités liées à l'appareil photo.
Il initialise et configure la fonction AVCaptureSession :
private func configureSession() {session.beginConfiguration()
Il tente ensuite d'ajouter un
AVCaptureDeviceInputet ajoutebuiltInWideAngleCameracomme entrée d'appareil pour Session.addVideoDeviceInput()
Il tente ensuite d'ajouter
AVCaptureVideoDataOutput:addVideoDataOutput()
session.commitConfiguration() self.cameraConfiguration = .success }Démarre la session.
Arrête la session.
Traitement des erreurs :
- NSNotification.Name.AVCaptureSessionRuntimeError : ce message est publié lorsqu'une erreur inattendue se produit pendant l'exécution de l'instance
AVCaptureSession. Le dictionnaire userInfo contient un objetNSErrorpour la cléAVCaptureSessionErrorKey. - NSNotification.Name.AVCaptureSessionWasInterrupted : ce message est publié lors d'une interruption (par exemple, un appel téléphonique, une alarme, etc.). Le cas échéant, l'instance
AVCaptureSessioncessera de s'exécuter automatiquement pour répondre à l'interruption. Le message userInfo contientAVCaptureSessionInterruptionReasonKeyindiquant le motif de l'interruption. - NSNotification.Name.AVCaptureSessionInterruptionEnded : ce message est publié lorsque
AVCaptureSessioncesse l'interruption. L'instance de session peut reprendre une fois l'interruption terminée, par exemple lorsque l'appel téléphonique prend fin.
La classe InferenceViewController.swift est responsable de l'affichage de l'écran ci-dessous, où la zone d'intérêt principal est en surbrillance.
- Resolution (Résolution) : affiche la résolution de l'image actuelle (issue d'une session vidéo).
- Crop (Rogner) : affiche la taille de rognage de l'image actuelle.
- InferenceTime (Durée d'interférence) : indique le temps nécessaire au modèle pour détecter l'objet.
- Threads : indique le nombre de threads en cours d'exécution.
L'utilisateur peut augmenter ou diminuer ce nombre en appuyant sur le symbole
+ou-de l'exécution pas à pas. Le nombre actuel de threads utilisés par l'interpréteur TensorFlow Lite.
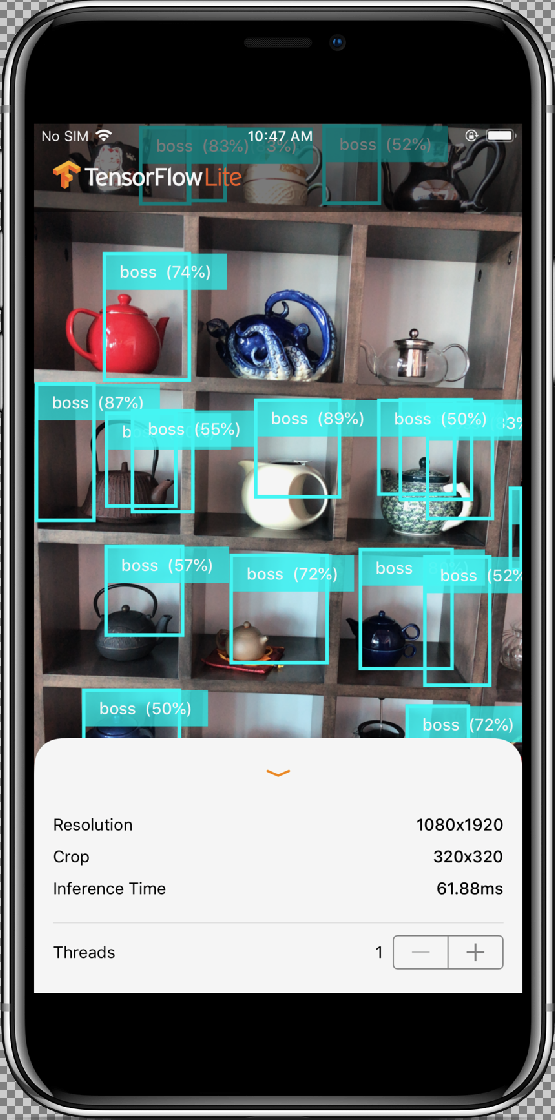
La classe ViewController.swift contient l'instance de CameraFeedManager, qui gère les fonctionnalités associées à l'appareil photo et ModelDataHandler. ModelDataHandler gère Model (modèle entraîné) et obtient la sortie pour l'image de la session vidéo.
private lazy var cameraFeedManager = CameraFeedManager(previewView: previewView)
private var modelDataHandler: ModelDataHandler? =
ModelDataHandler(modelFileInfo: MobileNetSSD.modelInfo, labelsFileInfo: MobileNetSSD.labelsInfo)
Démarre la session d'appareil photo en appelant :
cameraFeedManager.checkCameraConfigurationAndStartSession()
Lorsque vous modifiez le nombre de threads, cette classe réinitialise le modèle avec le nouveau nombre de threads dans la fonction didChangeThreadCount.
La classe CameraFeedManager enverra ImageFrame en tant que CVPixelBuffer à ViewController, qui sera envoyé au modèle pour la prédiction.
Cette méthode exécute l'appareil photo en direct pixelBuffer via TensorFlow pour obtenir le résultat.
@objc
func runModel(onPixelBuffer pixelBuffer: CVPixelBuffer) {
Exécuter le pixelBuffer de l'appareil photo en direct via tensorFlow pour obtenir le résultat :
result = self.modelDataHandler?.runModel(onFrame: pixelBuffer)
...
let displayResult = result
let width = CVPixelBufferGetWidth(pixelBuffer)
let height = CVPixelBufferGetHeight(pixelBuffer)
DispatchQueue.main.async {
Afficher les résultats en les fournissant au InferenceViewController :
self.inferenceViewController?.resolution = CGSize(width: width, height: height) self.inferenceViewController?.inferenceTime = inferenceTime
Dessine les cadres de délimitation et affiche les noms des classes et les scores de confiance :
self.drawAfterPerformingCalculations(onInferences: displayResult.inferences, withImageSize: CGSize(width: CGFloat(width), height: CGFloat(height)))
}
}
Étapes suivantes
Vous venez de terminer un tutoriel sur une application de détection et d'annotation d'objets sur iOS à l'aide d'un modèle Edge. Vous avez testé une application de détection d'objets à l'aide d'un modèle Edge Tensorflow Lite entraîné, vous avez modifiée cette application, puis vous avez obtenu des exemples d'annotations. Vous avez ensuite examiné le code propre à TensorFlow Lite afin d'en comprendre les fonctionnalités sous-jacentes.
Pour continuer à découvrir les modèles TensorFlow et AutoML Vision Edge, consultez les ressources suivantes :
- Pour en savoir plus sur TFLite, consultez la documentation officielle et le dépôt de code.
- Testez d'autres modèles pour TFLite, tels qu'un détecteur vocal de mots clés ou une version avec Réponse suggérée intégrée directement sur l'appareil.
- Pour en savoir plus sur TensorFlow en général, consultez la documentation de mise en route de TensorFlow.