Qué compilarás
En este instructivo, descargarás un modelo personalizado de TensorFlow Lite exportado desde AutoML Vision Edge. Luego, ejecutarás una app para iOS prediseñada que usa el modelo a fin de detectar múltiples objetos dentro de una imagen (con cuadros de límite) y proporcionar un etiquetado personalizado de categorías de objetos.
Objetivos
En esta introducción detallada, usarás el código para lo siguiente:
- Ejecutar un modelo de Edge de la detección de objetos de AutoML Vision en una app para iOS mediante el intérprete de TF Lite
Antes de comenzar
Clona el repositorio de Git
Mediante la línea de comandos, clona el repositorio de Git con el siguiente comando:
git clone https://github.com/tensorflow/examples.git
Navega al directorio ios del clon local del repositorio (examples/lite/examples/object_detection/ios/). Debes ejecutar todas las siguientes muestras de código desde el directorio ios:
cd examples/lite/examples/object_detection/ios
Requisitos previos
- Git debe estar instalado.
- Versiones de iOS compatibles: iOS 12.0 y versiones posteriores.
Configura la app para iOS
Genera y abre el archivo del espacio de trabajo
Si deseas comenzar a configurar la app para iOS original, primero debes generar el archivo del espacio de trabajo mediante el software necesario:
Navega a la carpeta
iossi aún no lo hiciste:cd examples/lite/examples/object_detection/ios
Instala el pod para generar el archivo del espacio de trabajo:
pod install
Si ya instalaste este pod antes, usa el siguiente comando:
pod update
Después de haber generado el archivo del espacio de trabajo, puedes abrir el proyecto con Xcode. Para abrir el proyecto a través de la línea de comandos, ejecuta el siguiente comando desde el directorio
ios:open ./ObjectDetection.xcworkspace
Crea un identificador único y compila la app
Con el ObjectDetection.xcworkspace abierto en Xcode, primero debes cambiar el identificador del paquete (ID del paquete) a un valor único.
Selecciona el elemento de proyecto
ObjectDetectionde arriba en el navegador de proyectos que se encuentra a la izquierda.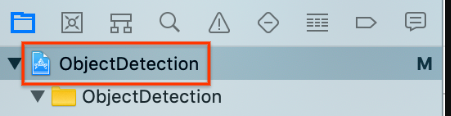
Asegúrate de tener seleccionado Destinos > ObjectDetection (Targets > ObjectDetection).
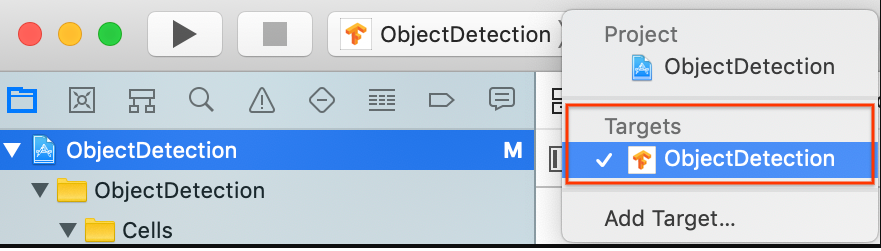
En la sección General > Identity (General > Identidad), cambia el campo del identificador del paquete a un valor único. El estilo preferido es el de notación de nombre de dominio inverso.
En la sección General > Signing (General > Firma), que se encuentra debajo de Identity (Identidad), especifica un Team (Equipo) en el menú desplegable. Este valor lo proporciona tu ID de desarrollador.
Conecta un dispositivo iOS a tu computadora. Después de que se detecte el dispositivo, selecciónalo de la lista de dispositivos.
Después de especificar todos los cambios de configuración, compila la app en Xcode mediante el siguiente comando: Comando + B.
Ejecuta la app original
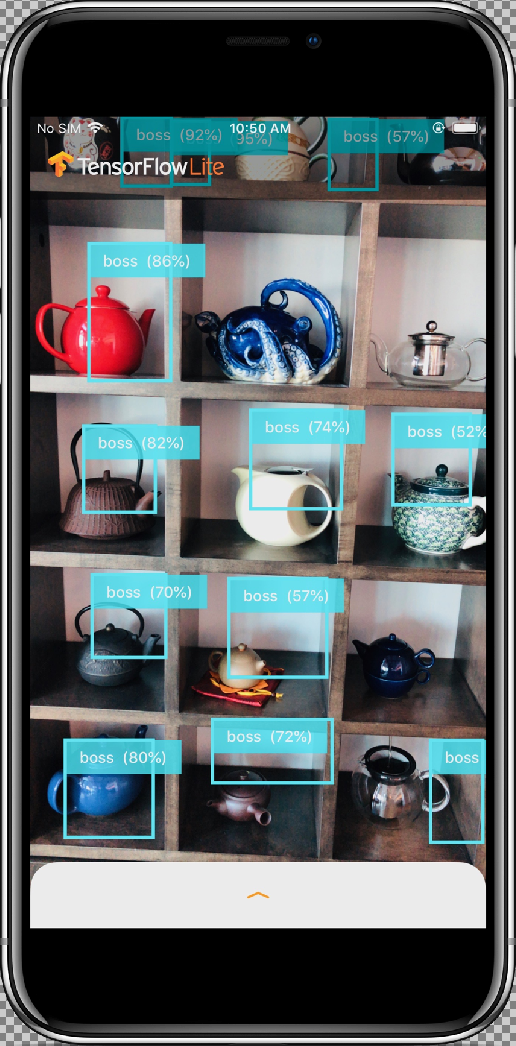
La app de muestra es una app de cámara que detecta de manera continua los objetos (cuadros de límite y etiquetas) en los marcos que ve la cámara trasera de tu dispositivo, mediante un modelo entrenado y cuantizado de SSD de MobileNet en un conjunto de datos de COCO.
Estas instrucciones te permitirán compilar y ejecutar la demostración en un dispositivo iOS.
Los archivos del modelo se descargan mediante secuencias de comandos en Xcode cuando compilas y ejecutas. No debes seguir ningún paso para descargar los modelos de TF Lite en el proyecto de forma explícita.
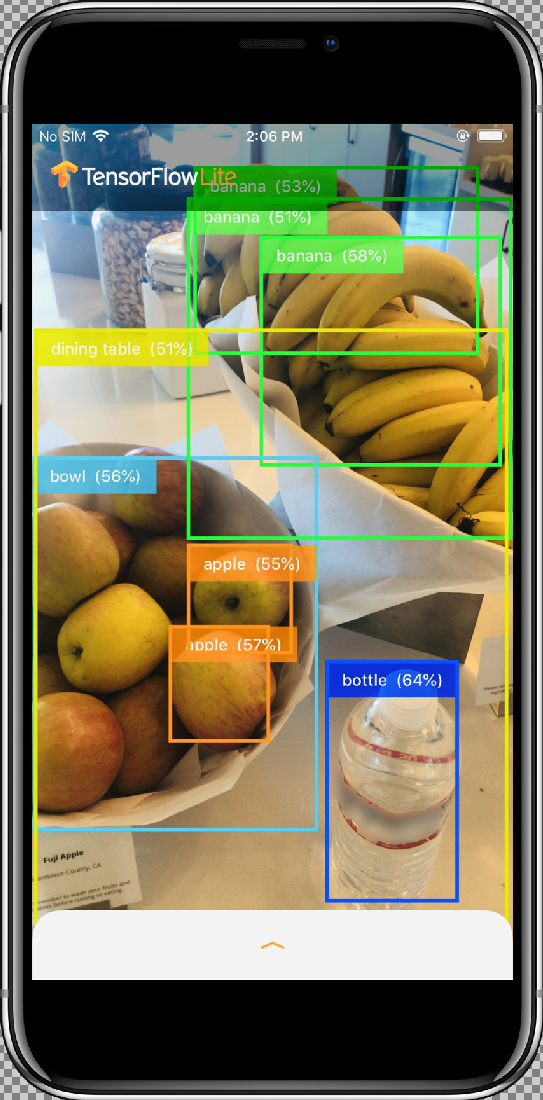
Antes de insertar tu modelo personalizado, prueba la versión de modelo de referencia de la app que usa el modelo base entrenado de “mobilenet”.
Para iniciar la app en el simulador, selecciona el botón de reproducir
 en la esquina superior izquierda de la ventana de Xcode.
en la esquina superior izquierda de la ventana de Xcode.
Luego de que hayas permitido que la app acceda a tu cámara con el botón Permitir, la app iniciará la detección y la anotación en vivo. Los objetos se detectarán y se marcarán con un cuadro de límite y una etiqueta en cada marco de la cámara.
Mueve el dispositivo hacia diferentes objetos de tu entorno y verifica que la app detecte las imágenes de forma correcta.
Ejecuta la app personalizada
Modifica la app para que use el modelo que se volvió a entrenar con categorías de imágenes de objetos personalizadas.
Agrega los archivos del modelo al proyecto
El proyecto de demostración está configurado para buscar dos archivos en el directorio ios/objectDetection/model:
detect.tflitelabelmap.txt
Para reemplazar esos dos archivos con las versiones personalizadas, ejecuta el siguiente comando:
cp tf_files/optimized_graph.lite ios/objectDetection/model/detect.tflite cp tf_files/retrained_labels.txt ios/objectDetection/model/labelmap.txt
Ejecuta tu app
Para reiniciar la app en tu dispositivo iOS, selecciona el botón de reproducir ![]() que se encuentra en la esquina superior izquierda de la ventana de Xcode.
que se encuentra en la esquina superior izquierda de la ventana de Xcode.
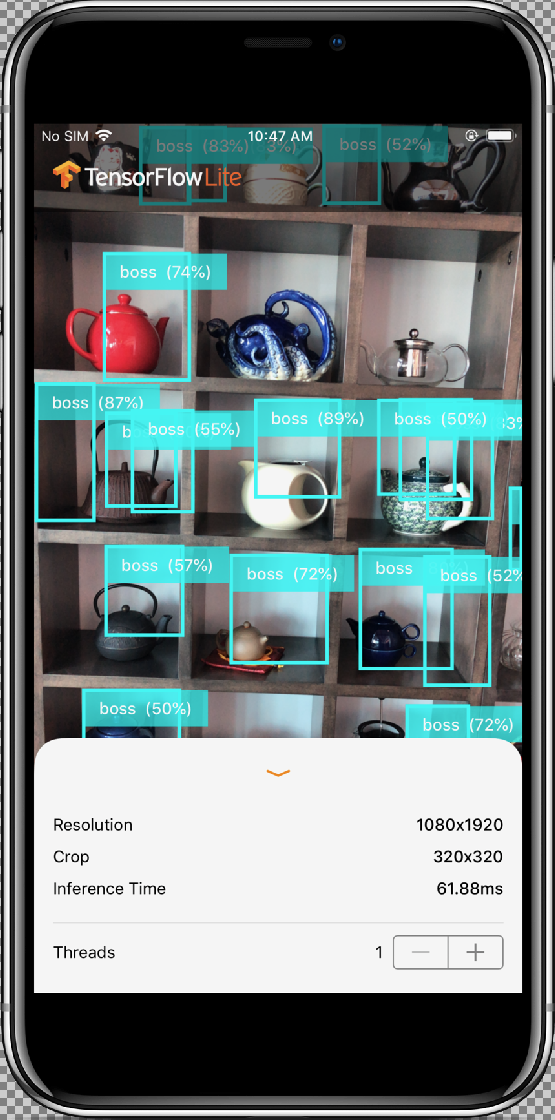
Para probar las modificaciones, mueve la cámara de tu dispositivo a distintos objetos a fin de ver las predicciones en vivo.
Los resultados deberían ser similares a esto:
¿Cómo funciona?
Ahora que la app está en ejecución, observa el código específico de TensorFlow Lite.
Pod de TensorFlowLite
Esta app usa un CocoaPod de TFLite ya compilado. El Podfile incluye el CocoaPod en el proyecto:
# Uncomment the next line to define a global platform for your project platform :ios, '12.0' target 'ObjectDetection' do # Comment the next line if you're not using Swift and don't want to use dynamic frameworks use_frameworks! # Pods for ObjectDetection pod 'TensorFlowLiteSwift' end
El código que interactúa con TF Lite está incluido en el archivo ModelDataHandler.swift. Esta clase controla todos los procesamientos previos de datos y realiza llamadas para ejecutar inferencias en un marco determinado mediante la invocación del Interpreter.
Luego, da formato a las inferencias obtenidas y muestra los N resultados principales de una inferencia correcta.
Explora el código
Las declaraciones de propiedad son el primer bloque de interés (después de las importaciones necesarias). Los parámetros inputShape del modelo de TF Lite (batchSize, inputChannels, inputWidth y inputHeight) se pueden encontrar en tflite_metadata.json. Tendrás este archivo cuando exportes el modelo de TF Lite. Para obtener más información, consulta la guía práctica Exporta modelos de Edge.
El ejemplo de tflite_metadata.json es similar al siguiente código:
{
"inferenceType": "QUANTIZED_UINT8",
"inputShape": [
1, // This represents batch size
512, // This represents image width
512, // This represents image Height
3 //This represents inputChannels
],
"inputTensor": "normalized_input_image_tensor",
"maxDetections": 20, // This represents max number of boxes.
"outputTensorRepresentation": [
"bounding_boxes",
"class_labels",
"class_confidences",
"num_of_boxes"
],
"outputTensors": [
"TFLite_Detection_PostProcess",
"TFLite_Detection_PostProcess:1",
"TFLite_Detection_PostProcess:2",
"TFLite_Detection_PostProcess:3"
]
}
...
Parámetros del modelo:
Reemplaza los siguientes valores según el archivo tflite_metadata.json de tu modelo.
let batchSize = 1 //Number of images to get prediction, the model takes 1 image at a time let inputChannels = 3 //The pixels of the image input represented in RGB values let inputWidth = 300 //Width of the image let inputHeight = 300 //Height of the image ...
init
El método init, que crea el Interpreter con la ruta de acceso de Model y InterpreterOptions, asigna memoria para la entrada del modelo.
init?(modelFileInfo: FileInfo, labelsFileInfo: FileInfo, threadCount: Int = 1) {
let modelFilename = modelFileInfo.name
// Construct the path to the model file.
guard let modelPath = Bundle.main.path(forResource: modelFilename,ofType: modelFileInfo.extension)
// Specify the options for the `Interpreter`.
var options = InterpreterOptions()
options.threadCount = threadCount
do {
// Create the `Interpreter`.
interpreter = try Interpreter(modelPath: modelPath, options: options)
// Allocate memory for the model's input `Tensor`s.
try interpreter.allocateTensors()
}
super.init()
// Load the classes listed in the labels file.
loadLabels(fileInfo: labelsFileInfo)
}
…
runModel
El método runModel realiza las siguientes acciones:
- Ajusta la escala de la imagen de entrada según la relación de aspecto para la que se entrena el modelo.
- Quita el componente Alfa del búfer de imágenes para obtener los datos RGB.
- Copia los datos RGB en el tensor de entrada.
- Ejecuta la inferencia mediante la invocación de
Interpreter. - Obtiene el resultado del intérprete.
- Da formato al resultado.
func runModel(onFrame pixelBuffer: CVPixelBuffer) -> Result? {
Recorta la imagen en el cuadrado más grande del centro y la ajusta según las dimensiones del modelo:
let scaledSize = CGSize(width: inputWidth, height: inputHeight)
guard let scaledPixelBuffer = pixelBuffer.resized(to: scaledSize) else
{
return nil
}
...
do {
let inputTensor = try interpreter.input(at: 0)
Quita el componente Alfa del búfer de imágenes para obtener los datos RGB.
guard let rgbData = rgbDataFromBuffer(
scaledPixelBuffer,
byteCount: batchSize * inputWidth * inputHeight * inputChannels,
isModelQuantized: inputTensor.dataType == .uInt8
) else {
print("Failed to convert the image buffer to RGB data.")
return nil
}
Copia los datos RGB en el Tensor de entrada:
try interpreter.copy(rgbData, toInputAt: 0)
Ejecuta la inferencia mediante la invocación de Interpreter:
let startDate = Date()
try interpreter.invoke()
interval = Date().timeIntervalSince(startDate) * 1000
outputBoundingBox = try interpreter.output(at: 0)
outputClasses = try interpreter.output(at: 1)
outputScores = try interpreter.output(at: 2)
outputCount = try interpreter.output(at: 3)
}
Da formato a los resultados:
let resultArray = formatResults(
boundingBox: [Float](unsafeData: outputBoundingBox.data) ?? [],
outputClasses: [Float](unsafeData: outputClasses.data) ?? [],
outputScores: [Float](unsafeData: outputScores.data) ?? [],
outputCount: Int(([Float](unsafeData: outputCount.data) ?? [0])[0]),
width: CGFloat(imageWidth),
height: CGFloat(imageHeight)
)
...
}
Filtra todos los resultados con una puntuación de confianza menor que el umbral y muestra los N resultados principales en orden descendente:
func formatResults(boundingBox: [Float], outputClasses: [Float],
outputScores: [Float], outputCount: Int, width: CGFloat, height: CGFloat)
-> [Inference]{
var resultsArray: [Inference] = []
for i in 0...outputCount - 1 {
let score = outputScores[i]
Filtra los resultados con una confianza menor que el umbral:
guard score >= threshold else {
continue
}
Obtiene los nombres de las clases de salida para las clases detectadas en la lista de etiquetas:
let outputClassIndex = Int(outputClasses[i])
let outputClass = labels[outputClassIndex + 1]
var rect: CGRect = CGRect.zero
Traduce el cuadro de límite detectado a CGRect.
rect.origin.y = CGFloat(boundingBox[4*i])
rect.origin.x = CGFloat(boundingBox[4*i+1])
rect.size.height = CGFloat(boundingBox[4*i+2]) - rect.origin.y
rect.size.width = CGFloat(boundingBox[4*i+3]) - rect.origin.x
Las esquinas detectadas corresponden a las dimensiones del modelo. Por lo tanto, ajustamos la escala de rect según las dimensiones reales de la imagen.
let newRect = rect.applying(CGAffineTransform(scaleX: width, y: height))
Obtiene el color asignado para la clase:
let colorToAssign = colorForClass(withIndex: outputClassIndex + 1)
let inference = Inference(confidence: score,
className: outputClass,
rect: newRect,
displayColor: colorToAssign)
resultsArray.append(inference)
}
// Sort results in descending order of confidence.
resultsArray.sort { (first, second) -> Bool in
return first.confidence > second.confidence
}
return resultsArray
}
CameraFeedManager
CameraFeedManager.swift administra todas las funciones relacionadas con la cámara.
Inicializa y configura AVCaptureSession:
private func configureSession() {session.beginConfiguration()
Luego, intenta agregar un
AVCaptureDeviceInputy agregabuiltInWideAngleCameracomo entrada de dispositivo para Session.addVideoDeviceInput()
Después intenta agregar un
AVCaptureVideoDataOutput:addVideoDataOutput()
session.commitConfiguration() self.cameraConfiguration = .success }Inicia la sesión.
Detiene la sesión.
Manejo de errores:
- NSNotification.Name.AVCaptureSessionRuntimeError: Esto se publica cuando se produce un error inesperado mientras se ejecuta la instancia
AVCaptureSession. El diccionario userInfo contiene un objetoNSErrorpara la claveAVCaptureSessionErrorKey. - NSNotification.Name.AVCaptureSessionWasInterrupted: esto se publica cuando se produce una interrupción (p. ej., una llamada telefónica, una alarma, etcétera). Cuando corresponda, la instancia
AVCaptureSessiondejará de ejecutarse de forma automática ante la interrupción de la respuesta. El diccionario userInfo contieneAVCaptureSessionInterruptionReasonKeyque indica el motivo de la interrupción. - NSNotification.Name.AVCaptureSessionInterruptionEnded: esto se publica cuando
AVCaptureSessionfinaliza la interrupción. La instancia de sesión puede reanudarse una vez que termine la interrupción, como una llamada telefónica.
La clase InferenceViewController.swift se encarga de que aparezca la siguiente pantalla, en la que deberíamos enfocarnos en la parte destacada.
- Resolution (Resolución): Muestra la resolución del marco actual (imagen de la sesión de video).
- Recortar (Crop): Muestra el tamaño de recorte del marco actual.
- Tiempo de inferencia (Inference Time): Muestra cuánto tiempo tarda el modelo en detectar el objeto.
- Threads (Subprocesos): Muestra la cantidad de subprocesos que están en ejecución.
El usuario puede presionar los signos
+o-para aumentar o disminuir. El recuento de subprocesos actual que usa el intérprete de TensorFlow Lite.
La clase ViewController.swift contiene la instancia de CameraFeedManager, que administra las funciones relacionadas con la cámara y ModelDataHandler. ModelDataHandler maneja el Model (modelo entrenado) y obtiene el resultado para el marco de la imagen de la sesión de video.
private lazy var cameraFeedManager = CameraFeedManager(previewView: previewView)
private var modelDataHandler: ModelDataHandler? =
ModelDataHandler(modelFileInfo: MobileNetSSD.modelInfo, labelsFileInfo: MobileNetSSD.labelsInfo)
Inicia la sesión de la cámara con una llamada al siguiente método:
cameraFeedManager.checkCameraConfigurationAndStartSession()
Cuando cambias el recuento de subprocesos, esta clase vuelve a inicializar el modelo con un nuevo recuento de subprocesos en la función didChangeThreadCount.
La clase CameraFeedManager enviará ImageFrame como CVPixelBuffer a ViewController, que se enviará al modelo para la predicción.
Este método ejecuta pixelBuffer de la cámara en vivo a través de TensorFlow para obtener el resultado.
@objc
func runModel(onPixelBuffer pixelBuffer: CVPixelBuffer) {
Ejecuta el pixelBuffer de la cámara en vivo a través de TensorFlow para obtener el resultado:
result = self.modelDataHandler?.runModel(onFrame: pixelBuffer)
...
let displayResult = result
let width = CVPixelBufferGetWidth(pixelBuffer)
let height = CVPixelBufferGetHeight(pixelBuffer)
DispatchQueue.main.async {
Muestra los resultados mediante la transferencia de InferenceViewController:
self.inferenceViewController?.resolution = CGSize(width: width, height: height) self.inferenceViewController?.inferenceTime = inferenceTime
Dibuja los cuadros de límite y muestra los nombres de las clases y las puntuaciones de confianza:
self.drawAfterPerformingCalculations(onInferences: displayResult.inferences, withImageSize: CGSize(width: CGFloat(width), height: CGFloat(height)))
}
}
Próximos pasos
Ya completaste un instructivo de una app de anotación y detección de objetos para iOS mediante un modelo de Edge. Usaste un modelo entrenado de Edge de Tensorflow Lite para probar una app de detección de objetos antes de modificarla y obtener anotaciones de muestra. Luego, examinaste el código específico de TensorFlow Lite para comprender la funcionalidad subyacente.
Los siguientes recursos pueden ayudarte a seguir aprendiendo sobre los modelos de TensorFlow y AutoML Vision Edge:
- Obtén más información sobre TFLite en la documentación oficial y el repositorio de códigos.
- Prueba otros modelos preparados para TFLite, como un detector de palabras clave por voz y una versión de respuesta inteligente en el dispositivo.
- Obtén más información sobre TensorFlow en general con la documentación de introducción.