Dopo aver creato (addestrato) un modello e averne eseguito il deployment, puoi inviarvi richieste di previsione online (o sincrone).
Esempio di previsione online (singola)
Dopo aver eseguito il deployment del modello addestrato, puoi richiedere una previsione per un'immagine utilizzando il metodo predict oppure utilizzare l'interfaccia utente per ricevere annotazioni sulle previsioni. Il metodo predict applica le etichette ai riquadri di delimitazione degli oggetti nell'immagine.
Durante il deployment del modello è previsto un addebito. Dopo aver effettuato previsioni con il modello addestrato, puoi undeploy del modello se non vuoi più incorrere in addebiti di utilizzo dell'hosting del modello.
UI web
Apri l'interfaccia utente di AutoML Vision Object Detection e fai clic sulla scheda Modelli (con l'icona a forma di lampadina) nella barra di navigazione a sinistra per visualizzare i modelli disponibili.
Per visualizzare i modelli di un altro progetto, seleziona il progetto dall'elenco a discesa in alto a destra nella barra del titolo.
Fai clic sulla riga del modello che vuoi utilizzare per etichettare le immagini.
Se non è stato ancora eseguito il deployment del modello, esegui subito il deployment selezionando Esegui il deployment del modello.
Per utilizzare le previsioni online, devi eseguire il deployment del modello. Il deployment del modello comporta costi. Per ulteriori informazioni, consulta la pagina dei prezzi.
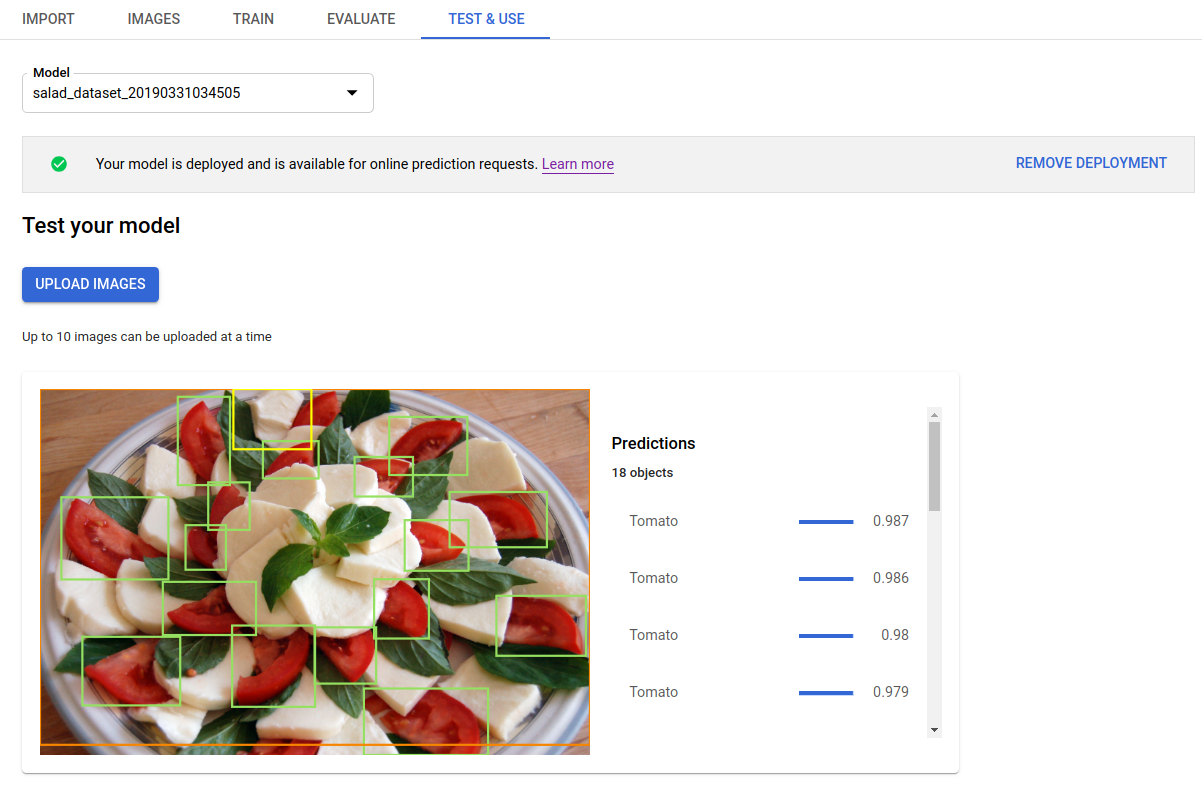
Fai clic sulla scheda Testa e utilizza appena sotto la barra del titolo.
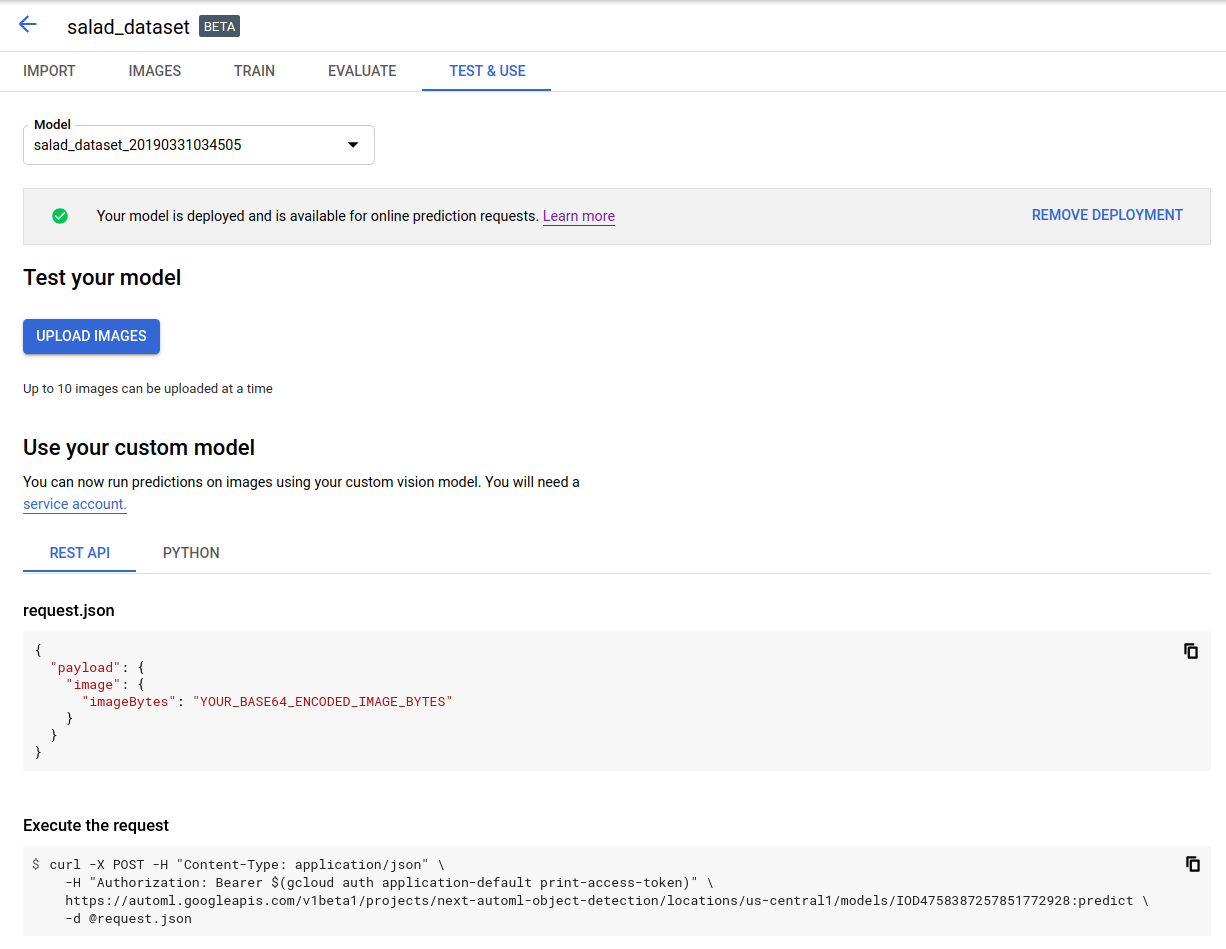
Fai clic su Carica immagini per caricare le immagini da etichettare.
REST
Per testare la previsione, devi prima eseguire il deployment del modello ospitato su cloud.
Prima di utilizzare i dati della richiesta, effettua le seguenti sostituzioni:
- project-id: l'ID del tuo progetto Google Cloud.
- model-id: l'ID del modello, dalla
risposta al momento della creazione del modello. L'ID è l'ultimo elemento del nome del modello.
Ad esempio:
- nome del modello:
projects/project-id/locations/location-id/models/IOD4412217016962778756 - ID modello:
IOD4412217016962778756
- nome del modello:
- base64-encoded-image: la rappresentazione base64 (stringa ASCII) dei dati di immagine binaria. Questa stringa dovrebbe essere simile alla
seguente stringa:
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==. Per saperne di più, consulta l'argomento Codifica Base64.
Considerazioni specifiche sul campo:
scoreThreshold: un valore compreso tra 0 e 1. Verranno visualizzati solo i valori con soglie di punteggio pari almeno a questo valore. Il valore predefinito è 0,5.maxBoundingBoxCount: il numero massimo (limite superiore) di riquadri di delimitazione da restituire in una risposta. Il valore predefinito è 100 e il massimo è 500. Questo valore è soggetto a vincoli delle risorse e potrebbe essere limitato dal server.
Metodo HTTP e URL:
POST https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict
Corpo JSON della richiesta:
{
"payload": {
"image": {
"imageBytes": "BASE64_ENCODED_IMAGE"
}
},
"params": {
"scoreThreshold": "0.5",
"maxBoundingBoxCount": "100"
}
}
Per inviare la richiesta, scegli una delle seguenti opzioni:
arricciatura
Salva il corpo della richiesta in un file denominato request.json ed esegui questo comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict"
PowerShell
Salva il corpo della richiesta in un file denominato request.json ed esegui questo comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/models/MODEL_ID:predict" | Select-Object -Expand Content
L'output viene restituito in formato JSON. Le previsioni del modello di rilevamento di oggetti AutoML Vision sono contenute nel campo payload:
- Il valore
boundingBoxdi un oggetto è specificato da vertici diagonalmente opposti. displayNameè l'etichetta dell'oggetto prevista dal modello Rilevamento di oggetti AutoML Vision.scorerappresenta un livello di confidenza che l'etichetta specificata viene applicata all'immagine. Varia da0(nessuna confidenza) a1(alta confidenza).
{
"payload": [
{
"imageObjectDetection": {
"boundingBox": {
"normalizedVertices": [
{
"x": 0.034553755,
"y": 0.015524037
},
{
"x": 0.941527,
"y": 0.9912563
}
]
},
"score": 0.9997793
},
"displayName": "Salad"
},
{
"imageObjectDetection": {
"boundingBox": {
"normalizedVertices": [
{
"x": 0.11737197,
"y": 0.7098793
},
{
"x": 0.510878,
"y": 0.87987
}
]
},
"score": 0.63219965
},
"displayName": "Tomato"
}
]
}
Go
Prima di provare questo esempio, segui le istruzioni di configurazione per questa lingua nella pagina Librerie client.
Java
Prima di provare questo esempio, segui le istruzioni di configurazione per questa lingua nella pagina Librerie client.
Node.js
Prima di provare questo esempio, segui le istruzioni di configurazione per questa lingua nella pagina Librerie client.
Python
Prima di provare questo esempio, segui le istruzioni di configurazione per questa lingua nella pagina Librerie client.
Linguaggi aggiuntivi
C#: segui le istruzioni di configurazione di C# nella pagina delle librerie client e poi consulta la documentazione di riferimento di AutoML Vision Object Detection per .NET.
PHP: segui le istruzioni per la configurazione dei file PHP nella pagina delle librerie client e consulta la documentazione di riferimento di AutoML Vision Object Detection per PHP.
Ruby: segui le istruzioni di configurazione di Ruby nella pagina delle librerie client e poi visita la documentazione di riferimento di AutoML Vision Object Detection per Ruby.