Después de crear un modelo de AutoML Vision Edge y exportarlo a un depósito de Google Cloud Storage, puedes usar los servicios de RESTful con tus modelos de AutoML Vision Edge y con imágenes de Docker de TF Serving.
Qué compilarás
Los contenedores de Docker pueden ayudarte a implementar modelos de Edge con facilidad en diferentes dispositivos. Puedes ejecutar modelos de Edge si llamas a las API de REST desde los contenedores en el lenguaje que prefieras, con el beneficio adicional de no tener que instalar dependencias o buscar las versiones correctas de TensorFlow.
En este instructivo, podrás experimentar paso a paso la ejecución de modelos de Edge en dispositivos que usan contenedores de Docker.
En este instructivo, se te guiará a través de tres pasos:
- Obtener contenedores ya compilados
- Ejecutar contenedores con modelos de Edge para iniciar las API de REST
- Realizar predicciones
Muchos dispositivos solo tienen CPU, mientras que otros pueden tener GPU para obtener predicciones más rápidas. Por lo tanto, brindamos instructivos con contenedores de CPU y GPU ya compilados.
Objetivos
En esta introducción detallada, usarás muestras de códigos para realizar lo siguiente:
- Obtener el contenedor de Docker
- Iniciar las API de REST mediante contenedores de Docker con modelos de Edge
- Hacer predicciones para obtener resultados analizados
Antes de comenzar
Para completar este instructivo, sigue estos pasos:
- Entrena un modelo exportable de Edge. Sigue la Guía de inicio rápido sobre modelos de dispositivos de Edge para entrenar un modelo de Edge.
- Exporta un modelo de AutoML Vision Edge. Este modelo se entrega con contenedores como API de REST.
- Instala Docker. Este es el software necesario para ejecutar contenedores de Docker.
- Instala el controlador y Docker de NVIDIA (opcional). Si tienes dispositivos con GPU y deseas obtener predicciones más rápidas, puedes realizar este paso opcional.
- Prepara imágenes de prueba. Estas imágenes se enviarán en solicitudes para obtener resultados analizados.
En la siguiente sección, se encuentran los detalles para instalar el software necesario y exportar modelos.
Exporta un modelo de AutoML Vision Edge
Después de entrenar un modelo de Edge, puedes exportarlo a diferentes dispositivos.
Los contenedores admiten modelos de TensorFlow, que se denominan saved_model.pb en la exportación.
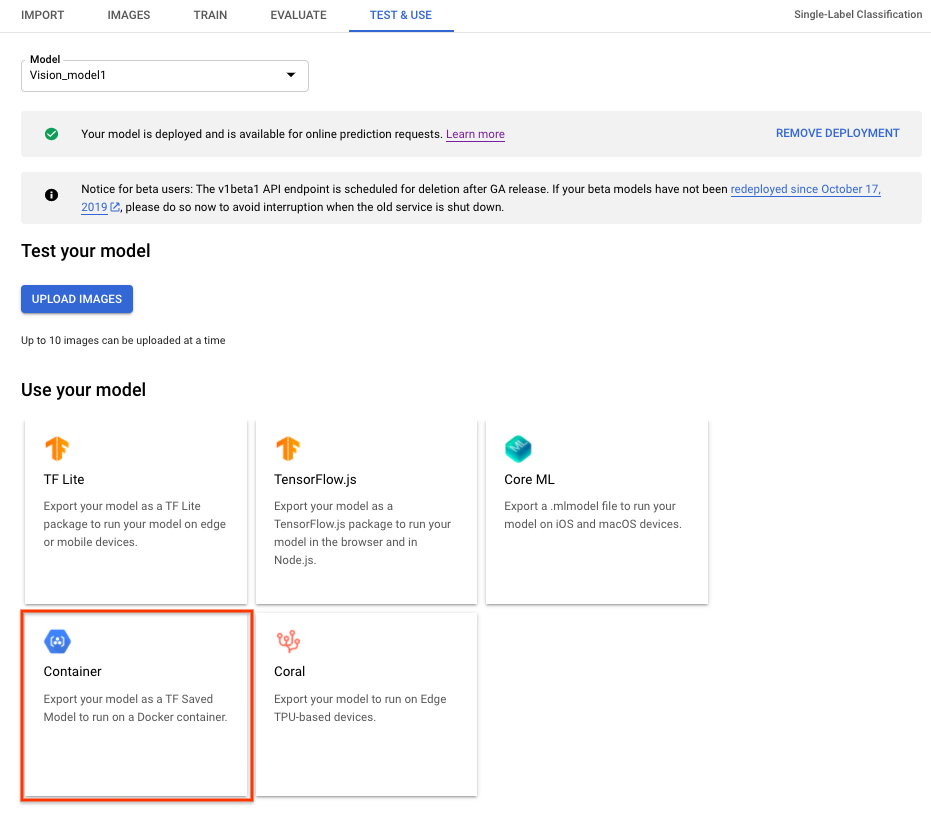
Si quieres exportar un modelo de AutoML Vision Edge para contenedores, selecciona la pestaña Container (Contenedor) en la IU y, luego, exporta el modelo a ${YOUR_MODEL_PATH} en Google Cloud Storage. Este modelo exportado se entrega más adelante con contenedores como API de REST.
Para descargar el modelo exportado de forma local, ejecuta el siguiente comando.
En el ejemplo anterior, se ilustra lo siguiente:
- ${YOUR_MODEL_PATH}: Es la ubicación del modelo en Google Cloud Storage (por ejemplo,
gs://my-bucket-vcm/models/edge/ICN4245971651915048908/2020-01-20_01-27-14-064_tf-saved-model/). - ${YOUR_LOCAL_MODEL_PATH}: Es la ruta local en la que deseas descargar el modelo (por ejemplo,
/tmp).
gsutil cp ${YOUR_MODEL_PATH} ${YOUR_LOCAL_MODEL_PATH}/saved_model.pb
Instala Docker
Docker es un software que se usa para implementar y ejecutar aplicaciones dentro de contenedores.
Instala Docker Community Edition (CE) en tu sistema. Lo usarás para entregar modelos de Edge como API de REST.
Instala el controlador y el DOCKER de NVIDIA (opcional, solo para GPU)
Algunos dispositivos tienen GPU para proporcionar predicciones más rápidas. Se proporciona el contenedor de Docker de GPU compatible con GPU de NVIDIA.
Para ejecutar contenedores de GPU, debes instalar el controlador de NVIDIA y el Docker de NVIDIA en tu sistema.
Ejecuta inferencias de modelos mediante CPU
En esta sección, se brindan instrucciones paso a paso para ejecutar inferencias de modelos mediante contenedores de CPU. Usa el Docker instalado a fin de obtener y ejecutar el contenedor de CPU para entregar los modelos de Edge exportados como API de REST y, luego, envía solicitudes de una imagen de prueba a las API de REST si quieres obtener resultados analizados.
Extrae la imagen de Docker
Primero, usa Docker para obtener un contenedor de CPU ya compilado. Este contenedor ya cuenta con el entorno completo para entregar modelos de Edge exportados, que aún no contiene modelos de Edge.
El contenedor de CPU ya compilado se almacena en Google Container Registry. Antes de solicitar el contenedor, configura una variable de entorno para su ubicación en Google Container Registry:
export CPU_DOCKER_GCR_PATH=gcr.io/cloud-devrel-public-resources/gcloud-container-1.14.0:latest
Después de configurar la variable de entorno para la ruta de acceso de Container Registry, ejecuta la siguiente línea de comandos a fin de obtener el contenedor de CPU:
sudo docker pull ${CPU_DOCKER_GCR_PATH}
Ejecuta el contenedor de Docker
Después de obtener el contenedor existente, ejecuta este contenedor de CPU para que entregue las inferencias del modelo de Edge con las API de REST.
Antes de iniciar el contenedor de CPU, debes establecer las variables del sistema:
- ${CONTAINER_NAME}: Es una string que indica el nombre del contenedor cuando se ejecuta, por ejemplo,
CONTAINER_NAME=automl_high_accuracy_model_cpu. - ${PORT}: Es un número que indica el puerto en tu dispositivo, para luego aceptar llamadas a la API de REST, como
PORT=8501.
Después de configurar las variables, ejecuta Docker en la línea de comandos para que entregue inferencias del modelo de Edge con las API de REST:
sudo docker run --rm --name ${CONTAINER_NAME} -p ${PORT}:8501 -v ${YOUR_MODEL_PATH}:/tmp/mounted_model/0001 -t ${CPU_DOCKER_GCR_PATH}
Una vez que el contenedor se ejecuta de forma correcta, las API de REST ya pueden entregarse en http://localhost:${PORT}/v1/models/default:predict. En la siguiente sección, se detalla cómo enviar solicitudes de predicción a esta ubicación.
Envía una solicitud de predicción
Ahora que el contenedor se está ejecutando de forma correcta, puedes enviar una solicitud de predicción en una imagen de prueba a las API de REST.
Línea de comandos
El cuerpo de la solicitud de línea de comandos contiene image_bytes codificados en base64 y una string key para identificar la imagen determinada. Consulta el tema Codifica en Base64 para obtener más información sobre la codificación de imágenes. El formato del archivo JSON de solicitud es el siguiente:
/tmp/request.json
{
"instances":
[
{
"image_bytes":
{
"b64": "/9j/7QBEUGhvdG9zaG9...base64-encoded-image-content...fXNWzvDEeYxxxzj/Coa6Bax//Z"
},
"key": "your-chosen-image-key"
}
]
}
Después de crear un archivo JSON de solicitud local, puedes enviar tu solicitud de predicción.
Usa el siguiente comando para enviar la solicitud de predicción:
curl -X POST -d @/tmp/request.json http://localhost:${PORT}/v1/models/default:predictRespuestaDebería ver un resultado similar al siguiente:
{
"predictions": [
{
"labels": ["Good", "Bad"],
"scores": [0.665018, 0.334982]
}
]
}
Python
Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Vision Python.
Para autenticarte en AutoML Vision, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Ejecuta inferencias de modelos mediante contenedores de GPU (opcional)
En esta sección, se muestra cómo ejecutar inferencias de modelos mediante contenedores de GPU. Este proceso es muy similar a ejecutar inferencias de modelos mediante una CPU. Las diferencias principales son la ruta de acceso de los contenedores de GPU y la forma en que estos se inician.
Extrae la imagen de Docker
Primero, usa Docker para obtener un contenedor de GPU ya compilado. Este contenedor ya cuenta con el entorno para entregar modelos de Edge exportados con GPU, que aún no contiene modelos de Edge ni controladores.
El contenedor de CPU ya compilado se almacena en Google Container Registry. Antes de solicitar el contenedor, configura una variable de entorno para su ubicación en Google Container Registry:
export GPU_DOCKER_GCR_PATH=gcr.io/cloud-devrel-public-resources/gcloud-container-1.14.0-gpu:latest
Ejecuta la siguiente línea de comandos para obtener el contenedor de GPU:
sudo docker pull ${GPU_DOCKER_GCR_PATH}
Ejecuta el contenedor de Docker
En este paso, se ejecuta el contenedor de GPU para entregar inferencias del modelo de Edge con las API de REST. Debes instalar el controlador y Docker de NVIDIA como se menciona más arriba. También debes establecer las siguientes variables del sistema:
- ${CONTAINER_NAME}: Es una string que indica el nombre del contenedor cuando se ejecuta, por ejemplo,
CONTAINER_NAME=automl_high_accuracy_model_gpu. - ${PORT}: Es un número que indica el puerto en tu dispositivo, para luego aceptar llamadas a la API de REST, como
PORT=8502.
Después de configurar las variables, ejecuta Docker en la línea de comandos para que entregue inferencias del modelo de Edge con las API de REST:
sudo docker run --runtime=nvidia --rm --name "${CONTAINER_NAME}" -v \
${YOUR_MODEL_PATH}:/tmp/mounted_model/0001 -p \
${PORT}:8501 -t ${GPU_DOCKER_GCR_PATH}
Una vez que el contenedor se esté ejecutando de forma correcta, las API de REST se pueden entregar en http://localhost:${PORT}/v1/models/default:predict. En la siguiente sección, se detalla cómo enviar solicitudes de predicción a esta ubicación.
Envía una solicitud de predicción
Ahora que el contenedor se está ejecutando de forma correcta, puedes enviar una solicitud de predicción en una imagen de prueba a las API de REST.
Línea de comandos
El cuerpo de la solicitud de línea de comandos contiene image_bytes codificados en base64 y una string key para identificar la imagen determinada. Consulta el tema Codifica en Base64 para obtener más información sobre la codificación de imágenes. El formato del archivo JSON de solicitud es el siguiente:
/tmp/request.json
{
"instances":
[
{
"image_bytes":
{
"b64": "/9j/7QBEUGhvdG9zaG9...base64-encoded-image-content...fXNWzvDEeYxxxzj/Coa6Bax//Z"
},
"key": "your-chosen-image-key"
}
]
}
Después de crear un archivo JSON de solicitud local, puedes enviar tu solicitud de predicción.
Usa el siguiente comando para enviar la solicitud de predicción:
curl -X POST -d @/tmp/request.json http://localhost:${PORT}/v1/models/default:predictRespuestaDebería ver un resultado similar al siguiente:
{
"predictions": [
{
"labels": ["Good", "Bad"],
"scores": [0.665018, 0.334982]
}
]
}
Python
Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Vision Python.
Para autenticarte en AutoML Vision, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Resumen
En este instructivo, aprendiste a ejecutar modelos de Edge mediante contenedores de Docker de CPU o GPU. Ahora puedes implementar esta solución basada en contenedores en más dispositivos.
¿Qué sigue?
- Obtén más información sobre TensorFlow con la documentación de introducción.
- Obtén más información sobre Tensorflow Serving.
- Aprende a usar TensorFlow Serving con Kubernetes.