Introducción
Imagina que trabajas con una junta de conservación arquitectónica que intenta identificar los vecindarios de tu ciudad que tienen un estilo arquitectónico coherente. Tienes cientos de miles de instantáneas de hogares para categorizar, pero tratar de clasificar a mano todas estas imágenes es un proceso tedioso y propenso a errores. Un pasante etiquetó algunos centenares de ellas hace unos meses, y nadie las ha tocado desde entonces. Sería muy útil si pudieras enseñarle a tu computadora a hacer esto por ti.

¿Por qué el aprendizaje automático (AA) es la herramienta correcta para este problema?
 La programación clásica requiere que el programador especifique las instrucciones paso a paso para que la computadora las siga. Si bien este enfoque funciona a la hora de resolver una amplia variedad de problemas, no es adecuado para clasificar los hogares de la manera que deseas. Hay mucha variación en la composición, los colores, los ángulos y los detalles estilísticos; no parece que sea posible concebir el diseño de un conjunto de reglas paso a paso que puedan decirle a una máquina cómo decidir si una fotografía de una residencia unifamiliar es estilo artesanal o moderno. Es difícil imaginar por dónde empezar. Por fortuna, los sistemas de aprendizaje automático tienen lo necesario para resolver este problema.
La programación clásica requiere que el programador especifique las instrucciones paso a paso para que la computadora las siga. Si bien este enfoque funciona a la hora de resolver una amplia variedad de problemas, no es adecuado para clasificar los hogares de la manera que deseas. Hay mucha variación en la composición, los colores, los ángulos y los detalles estilísticos; no parece que sea posible concebir el diseño de un conjunto de reglas paso a paso que puedan decirle a una máquina cómo decidir si una fotografía de una residencia unifamiliar es estilo artesanal o moderno. Es difícil imaginar por dónde empezar. Por fortuna, los sistemas de aprendizaje automático tienen lo necesario para resolver este problema.
¿La API de Vision o AutoML es la herramienta adecuada para mí?
La API de Vision clasifica las imágenes en miles de categorías predefinidas, detecta rostros y objetos individuales dentro de imágenes, además de encontrar y leer las palabras impresas incluidas en las imágenes. Si deseas detectar rostros, texto y objetos individuales en tu conjunto de datos, o tu necesidad de clasificación de imágenes es bastante genérica, prueba la API de Vision para ver si es lo que necesitas. Sin embargo, si tu caso práctico requiere que uses tus propias etiquetas para clasificar imágenes, vale la pena experimentar con un clasificador personalizado a fin de ver si se ajusta a tus necesidades.
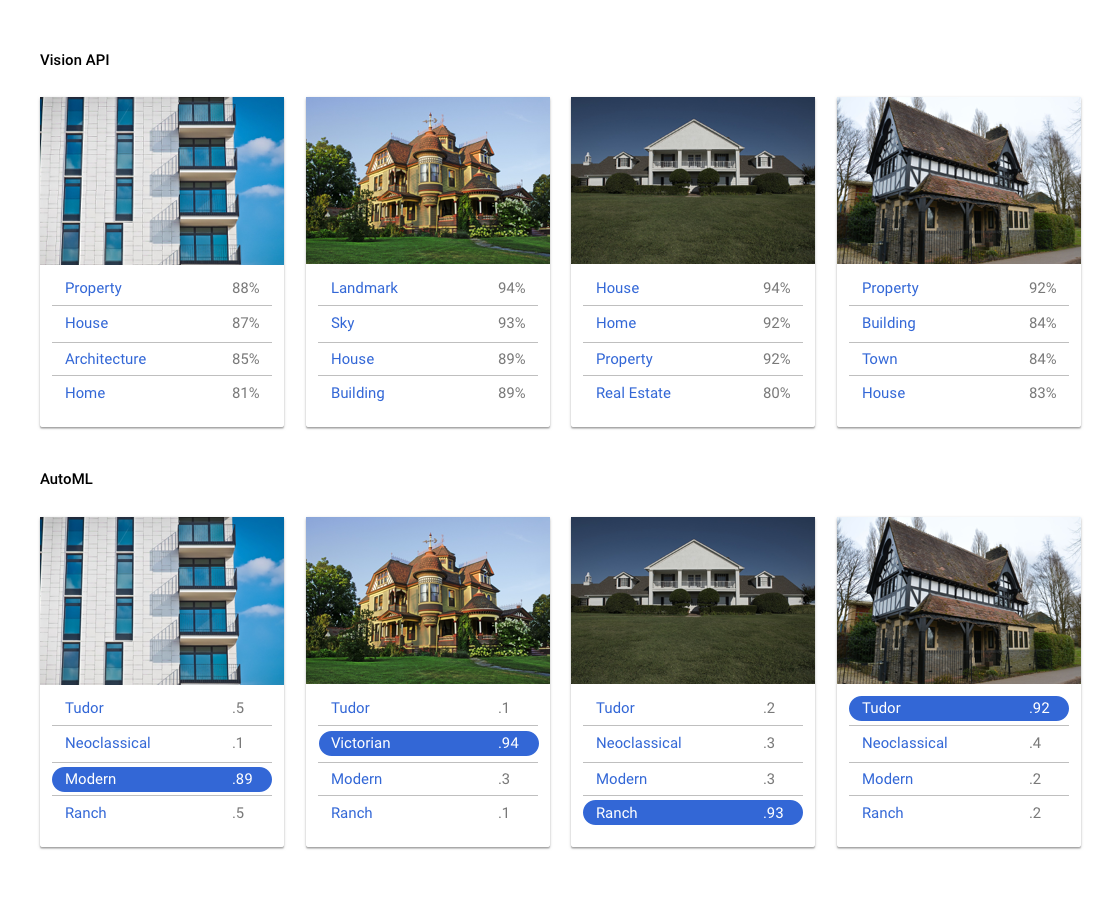
| Probar la API de Vision | Comenzar a usar AutoML |
¿Qué implica el aprendizaje automático en AutoML?
 El aprendizaje automático implica el uso de datos para entrenar algoritmos a fin de lograr un resultado deseado. Los detalles del algoritmo y los métodos de entrenamiento cambian según el caso práctico. Existen muchas subcategorías diferentes de aprendizaje automático; todas ellas resuelven distintos problemas y funcionan con diferentes restricciones.
AutoML Vision te permite realizar aprendizaje supervisado, que consiste en entrenar una computadora para reconocer patrones de datos etiquetados. Mediante el aprendizaje supervisado, podemos entrenar un modelo para reconocer en las imágenes los patrones y el contenido que nos interesan.
El aprendizaje automático implica el uso de datos para entrenar algoritmos a fin de lograr un resultado deseado. Los detalles del algoritmo y los métodos de entrenamiento cambian según el caso práctico. Existen muchas subcategorías diferentes de aprendizaje automático; todas ellas resuelven distintos problemas y funcionan con diferentes restricciones.
AutoML Vision te permite realizar aprendizaje supervisado, que consiste en entrenar una computadora para reconocer patrones de datos etiquetados. Mediante el aprendizaje supervisado, podemos entrenar un modelo para reconocer en las imágenes los patrones y el contenido que nos interesan.
Preparación de datos
Para entrenar un modelo personalizado con AutoML Vision, deberás proporcionar ejemplos etiquetados de los tipos de imágenes (entradas) que deseas clasificar y las categorías o etiquetas (la respuesta) que quieres que predigan los sistemas de AA.
Evalúa tu caso práctico

Para crear el conjunto de datos, comienza siempre con el caso práctico. Puedes empezar con las siguientes preguntas:
- ¿Cuál es el resultado que buscas?
- ¿Qué tipos de categorías necesitarías reconocer para lograr este resultado?
- ¿Es posible que las personas reconozcan esas categorías? Aunque AutoML Vision puede controlar una mayor cantidad de categorías que las que una persona puede recordar y asignar a la vez, si una persona no puede reconocer una categoría específica, entonces AutoML Vision también tendrá dificultades.
- ¿Qué clases de ejemplos reflejarán mejor el tipo y el rango de datos que clasificará tu sistema?
Un principio fundamental en el que se basan los productos de AA de Google es el aprendizaje automático centrado en las personas, un enfoque que destaca las prácticas de IA responsables, incluida la equidad. El objetivo de la equidad en el AA es comprender y evitar un trato injusto o discriminatorio de las personas en relación con su origen étnico, orientación sexual, religión, género, ingresos y otras características asociadas históricamente con la discriminación y la exclusión, en el lugar y el momento en el que se manifiesten en los sistemas algorítmicos o en la toma de decisiones basada en algoritmos. Puedes leer más en nuestra guía y encontrar notas sobre imparcialidad ✽ en los siguientes lineamientos. Te recomendamos que, a medida que avances a través de las pautas para armar el conjunto de datos, consideres la equidad en el aprendizaje automático según sea relevante para tu caso práctico.
Obtén tus datos
 Una vez que estableciste qué datos necesitarás, debes encontrar una manera de obtenerlos. Para comenzar, puedes tener en cuenta todos los datos que recopila tu organización. Es posible que descubras que ya está recopilando los datos que necesitas para entrenar un modelo. En caso de que no tengas los datos que necesitas, puedes obtenerlos de forma manual o subcontratar a un servicio de terceros.
Una vez que estableciste qué datos necesitarás, debes encontrar una manera de obtenerlos. Para comenzar, puedes tener en cuenta todos los datos que recopila tu organización. Es posible que descubras que ya está recopilando los datos que necesitas para entrenar un modelo. En caso de que no tengas los datos que necesitas, puedes obtenerlos de forma manual o subcontratar a un servicio de terceros.
Incluye suficientes ejemplos etiquetados en cada categoría
 El mínimo que se requiere para el entrenamiento de AutoML Vision es de 100 ejemplos de imágenes por categoría o etiqueta. La probabilidad de reconocer con éxito una etiqueta aumenta con la cantidad de ejemplos de alta calidad para cada una; en general, cuantos más datos etiquetados puedas aportar al proceso de entrenamiento, mejor será tu modelo. Selecciona al menos 1,000 ejemplos por etiqueta.
El mínimo que se requiere para el entrenamiento de AutoML Vision es de 100 ejemplos de imágenes por categoría o etiqueta. La probabilidad de reconocer con éxito una etiqueta aumenta con la cantidad de ejemplos de alta calidad para cada una; en general, cuantos más datos etiquetados puedas aportar al proceso de entrenamiento, mejor será tu modelo. Selecciona al menos 1,000 ejemplos por etiqueta.
Distribuye ejemplos de manera equitativa entre las categorías
Es importante recopilar cantidades similares de ejemplos de entrenamiento para cada categoría. Incluso si tienes una gran cantidad de datos que corresponden a una etiqueta, es mejor tener una distribución equitativa para cada una. Para entender por qué, imagina que el 80% de las imágenes que usas cuando compilas tu modelo son imágenes de casas unifamiliares de estilo moderno. Con una distribución de etiquetas tan desequilibrada, es muy probable que tu modelo suponga que es seguro indicar siempre que una foto es de una casa unifamiliar moderna, en lugar de arriesgarse a intentar predecir una etiqueta mucho menos común. Es como escribir una prueba de opción múltiple en la que casi todas las respuestas correctas son “C”. Pronto, el experto sabrá que puede responder “C” sin siquiera mirar la pregunta.

Entendemos que no siempre es posible obtener una cantidad parecida de ejemplos para cada etiqueta. Los ejemplos imparciales y de alta calidad para algunas categorías pueden ser más difíciles de obtener. En esas circunstancias, puedes seguir esta regla general: la etiqueta con el número más bajo de ejemplos debe tener al menos el 10% de los que tiene la etiqueta con el número más alto. Entonces, si la etiqueta más grande tiene 10,000 ejemplos, la etiqueta más pequeña debe tener al menos 1,000 ejemplos.
Captura la variación en tu espacio problemático
Por razones similares, intenta asegurarte de que tus datos capturen la variedad y diversidad del espacio del problema. Cuanto más amplia sea la selección para el proceso de entrenamiento del modelo, más fácil será establecer generalizaciones que contemplen ejemplos nuevos. Por ejemplo, si intentas clasificar fotos de artículos electrónicos de consumo en categorías, cuanto más amplia sea la variedad de artículos a la que se expone el modelo en el entrenamiento, más probable será que pueda distinguir entre un modelo nuevo de tablet, teléfono o laptop, incluso si nunca antes vio ese modelo específico.
Haz coincidir los datos con el resultado previsto para tu modelo

Encuentra imágenes que sean visualmente similares a lo que planeas usar para hacer predicciones. Si intentas clasificar fotos de casas tomadas en un clima nevado de invierno, es probable que no obtengas un buen rendimiento de un modelo entrenado solo con fotos tomadas en un clima soleado, incluso si las etiquetaste de forma correcta, ya que la iluminación y el paisaje pueden ser bastante diferentes y afectar el rendimiento. Lo ideal es que tus ejemplos de entrenamiento sean datos del mundo real extraídos del mismo conjunto de datos que deseas clasificar mediante el modelo.
Considera cómo AutoML Vision usa tu conjunto de datos para crear un modelo personalizado
Tu conjunto de datos contiene conjuntos de entrenamiento, validación y prueba. Si no especificas las divisiones (consulta Prepara tus datos), AutoML Vision usa de forma automática el 80% de tus imágenes para el entrenamiento, el 10% para la validación y el 10% para las pruebas.
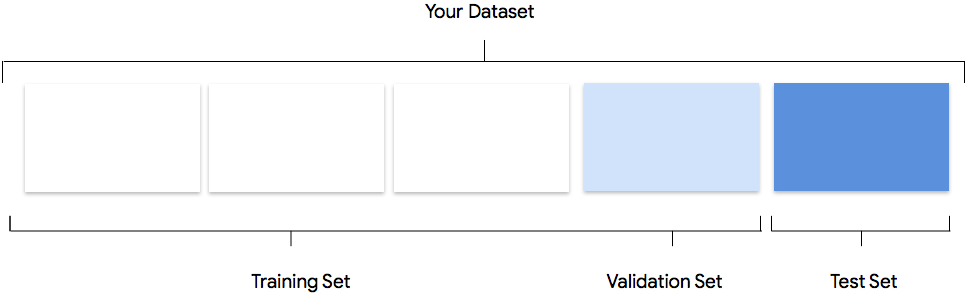
Conjunto de entrenamiento
 La gran mayoría de tus datos deben estar en el conjunto de entrenamiento. Estos son los datos que tu modelo “ve” durante el entrenamiento; se usan para aprender los parámetros del modelo, es decir, el peso de las conexiones entre los nodos de la red neuronal.
La gran mayoría de tus datos deben estar en el conjunto de entrenamiento. Estos son los datos que tu modelo “ve” durante el entrenamiento; se usan para aprender los parámetros del modelo, es decir, el peso de las conexiones entre los nodos de la red neuronal.
Conjunto de validación
 El conjunto de validación, a veces llamado conjunto “dev”, también se usa durante el proceso de entrenamiento. Después de que el framework del modelo de aprendizaje incorpora datos de entrenamiento durante cada iteración del proceso de entrenamiento, usa el rendimiento del modelo en el conjunto de validación para ajustar sus hiperparámetros, que son variables que especifican la estructura del modelo. Si intentaste usar el conjunto de entrenamiento para ajustar los hiperparámetros, es muy probable que el modelo se centre demasiado en tus datos de entrenamiento y le cueste generalizar ejemplos que no coincidan con exactitud. Si usas un conjunto de datos un tanto nuevo para configurar la estructura del modelo, este realizará mejores generalizaciones.
El conjunto de validación, a veces llamado conjunto “dev”, también se usa durante el proceso de entrenamiento. Después de que el framework del modelo de aprendizaje incorpora datos de entrenamiento durante cada iteración del proceso de entrenamiento, usa el rendimiento del modelo en el conjunto de validación para ajustar sus hiperparámetros, que son variables que especifican la estructura del modelo. Si intentaste usar el conjunto de entrenamiento para ajustar los hiperparámetros, es muy probable que el modelo se centre demasiado en tus datos de entrenamiento y le cueste generalizar ejemplos que no coincidan con exactitud. Si usas un conjunto de datos un tanto nuevo para configurar la estructura del modelo, este realizará mejores generalizaciones.
Conjunto de prueba
 El conjunto de prueba no interviene para nada en el proceso de entrenamiento. Una vez que el modelo completa todo su entrenamiento, usamos el conjunto de prueba como un desafío nuevo para tu modelo. El rendimiento de tu modelo en el conjunto de prueba sirve para darte una idea bastante clara de cómo será su rendimiento en datos del mundo real.
El conjunto de prueba no interviene para nada en el proceso de entrenamiento. Una vez que el modelo completa todo su entrenamiento, usamos el conjunto de prueba como un desafío nuevo para tu modelo. El rendimiento de tu modelo en el conjunto de prueba sirve para darte una idea bastante clara de cómo será su rendimiento en datos del mundo real.
División manual
 También puedes dividir tu conjunto de datos. La división manual de datos es una buena opción cuando deseas ejercer más control sobre el proceso o si hay ejemplos específicos que deseas incluir en una parte determinada del ciclo de vida del entrenamiento del modelo.
También puedes dividir tu conjunto de datos. La división manual de datos es una buena opción cuando deseas ejercer más control sobre el proceso o si hay ejemplos específicos que deseas incluir en una parte determinada del ciclo de vida del entrenamiento del modelo.
Prepara tus datos para importarlos

Una vez que elijas entre la división manual y la automática, hay tres formas de agregar datos en AutoML Vision:
- Puedes importar datos con tus imágenes ordenadas y almacenadas en carpetas que correspondan a tus etiquetas.
- Puedes importar datos desde Google Cloud Storage en formato CSV con las etiquetas intercaladas. Para obtener más información, visita nuestra documentación.
- Si tus datos aún no están etiquetados, también puedes subir ejemplos de imágenes sin etiqueta y usar la IU de AutoML Vision para etiquetar cada una.
Evalúa el modelo
Una vez que tu modelo esté entrenado, recibirás un resumen de su rendimiento. Haz clic en “evaluar” o “ver evaluación completa” para ver un análisis detallado.
¿Qué debo tener en cuenta antes de evaluar mi modelo?
 La depuración de un modelo es más bien una depuración de los datos que del modelo en sí. Si en algún momento tu modelo comienza a actuar de manera inesperada mientras evalúas su rendimiento antes y después de enviarlo a producción, debes regresar y verificar los datos para ver dónde podrían realizarse mejoras.
La depuración de un modelo es más bien una depuración de los datos que del modelo en sí. Si en algún momento tu modelo comienza a actuar de manera inesperada mientras evalúas su rendimiento antes y después de enviarlo a producción, debes regresar y verificar los datos para ver dónde podrían realizarse mejoras.
¿Qué tipos de análisis puedo realizar en AutoML Vision?
En la sección de evaluación de AutoML Vision, puedes evaluar el rendimiento de tu modelo personalizado mediante la salida del modelo en los ejemplos de prueba y las métricas comunes del aprendizaje automático. En esta sección, abordaremos el significado de cada uno de estos conceptos.
- La salida del modelo
- El límite de puntuación
- Positivos verdaderos, negativos verdaderos, falsos positivos y falsos negativos
- Precisión y recuperación
- Curvas de precisión y recuperación
- Precisión promedio
¿Cómo interpreto la salida del modelo?
AutoML Vision extrae ejemplos de los datos de prueba para presentarle desafíos nuevos a tu modelo. Para cada ejemplo, el modelo genera una serie de números que reflejan el grado de confianza con el que asocia cada etiqueta con ese ejemplo. Si el número es alto, el modelo tiene una confianza alta en que la etiqueta se debe aplicar a ese documento.

¿Cuál es el umbral de puntuación?
Podemos convertir estas probabilidades en valores binarios de “encendido” y “apagado” si establecemos un umbral de puntuación. El umbral de puntuación se refiere al nivel de confianza que debe tener el modelo para asignar una categoría a un elemento de prueba. El control deslizante del umbral de puntuación en la IU es una herramienta visual que prueba el impacto de diferentes umbrales para todas las categorías y categorías individuales en el conjunto de datos. Si el umbral de puntuación es bajo, tu modelo clasificará más imágenes, pero corres el riesgo de clasificar de forma errónea algunas imágenes en el proceso. Si el umbral de puntuación es alto, tu modelo clasificará menos imágenes, pero tendrá un riesgo menor de clasificar de manera incorrecta las imágenes. Puedes modificar los umbrales por categoría en la IU para experimentar. Sin embargo, cuando uses el modelo en producción, tendrás que aplicar los umbrales óptimos de tu lado.
¿Qué son los verdaderos positivos, los verdaderos negativos, los falsos positivos y los falsos negativos?
Después de aplicar el umbral de puntuación, las predicciones que haga tu modelo entrarán en una de las siguientes cuatro categorías.

Podemos usar estas categorías para calcular la precisión y la recuperación, métricas que nos ayudan a medir la eficacia de nuestro modelo.
¿Qué son la precisión y la recuperación?
La precisión y la recuperación nos ayudan a comprender qué tan bien nuestro modelo captura información y cuánta omite. La precisión nos dice cuántos de todos los ejemplos de prueba a los que se asignó una etiqueta se clasificaron de forma correcta. La recuperación nos dice cuántos de todos los ejemplos de prueba a los que debía asignarse una etiqueta determinada se etiquetaron de forma correcta.


¿Debo optimizar la precisión o la recuperación?
Según tu caso práctico, es posible que debas optimizar la precisión o la recuperación. Analicemos cómo abordar esta decisión con los siguientes dos casos prácticos.
Caso práctico: privacidad en las imágenes
Supongamos que deseas crear un sistema que detecte de forma automática la información sensible y la difumine.

Los falsos positivos en este caso serían objetos que se difuminan por error, lo que puede ser molesto, pero no perjudicial.
Los falsos negativos en este caso serían objetos que se dejaron sin difuminar por error, como una tarjeta de crédito, lo que puede llevar a un robo de identidad.
En este caso, debes optimizar la recuperación. Esta métrica determina cuánto se omite en todas las predicciones realizadas. Es probable que un modelo de recuperación alta etiquete ejemplos apenas relevantes, lo cual es útil para los casos en los que tu categoría tiene pocos datos de entrenamiento.
Caso práctico: búsqueda de fotografías de archivo
Supongamos que deseas crear un sistema que encuentre la mejor fotografía de archivo para una palabra clave determinada.

Un falso positivo en este caso mostraría una imagen irrelevante. Como se supone que tu producto muestra solo las imágenes que mejor coinciden, el resultado obtenido sería un gran fracaso.

Un falso negativo en este caso sería no mostrar una imagen relevante en una búsqueda por palabra clave. Ya que muchos términos de búsqueda tienen miles de fotos con una sólida coincidencia posible, esto no es un problema.
En este caso, debes optimizar la precisión. Esta métrica determina qué tan correctas son todas las predicciones hechas. Es probable que un modelo de alta precisión etiquete solo los ejemplos más relevantes, lo cual es útil para los casos en los que tu clase es común en los datos de entrenamiento.
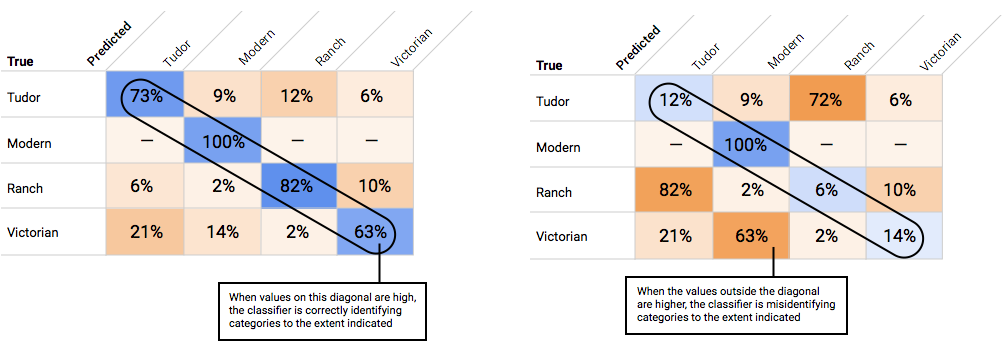
¿Cómo uso la matriz de confusión?
Podemos comparar el rendimiento del modelo en cada etiqueta con una matriz de confusión. En un modelo ideal, todos los valores en la diagonal serán altos y todos los demás valores serán bajos. Esto demuestra que las categorías deseadas se identifican de forma correcta. Si cualquier otro valor es alto, nos da una pista sobre cómo el modelo clasifica las imágenes de prueba de forma errónea.
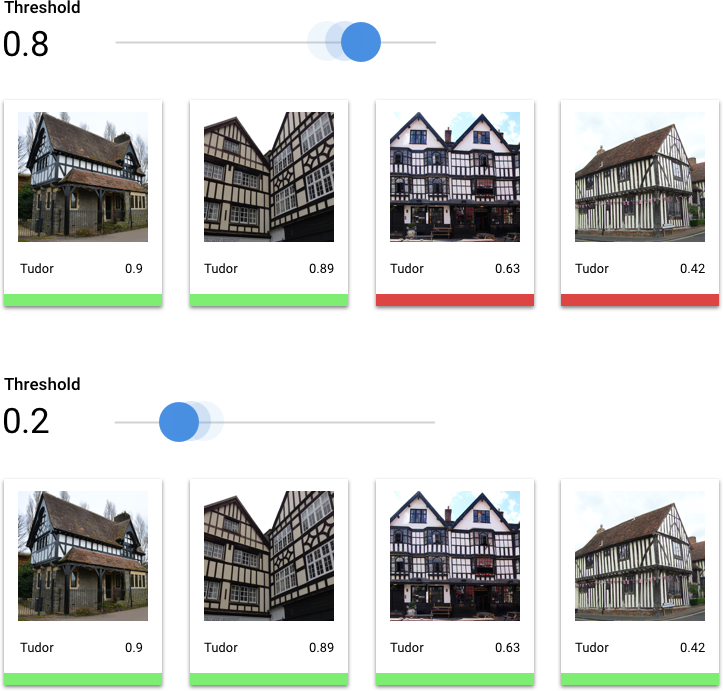
¿Cómo interpreto las curvas de precisión y recuperación?
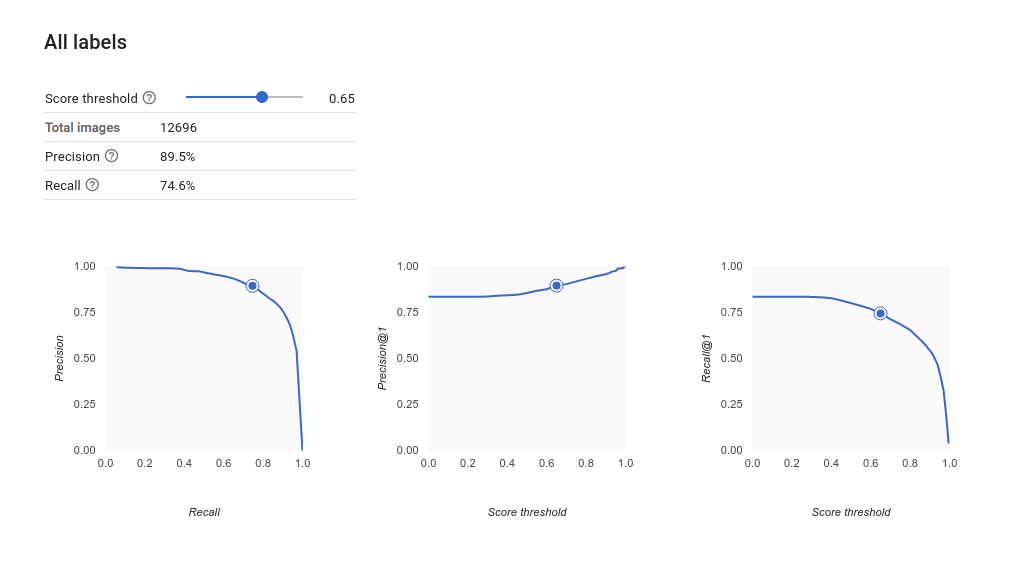
La herramienta de umbral de puntuación te permite explorar cómo el umbral de puntuación elegido afecta la precisión y la recuperación. A medida que arrastras el control deslizante en la barra de umbral de puntuación, puedes ver dónde te sitúa ese umbral en la curva de balance de precisión-recuperación y cómo afecta a tu precisión y recuperación individuales (para modelos multiclase, la única etiqueta que se usa en estos grafos a fin de calcular las métricas de precisión y recuperación es la que tiene la puntuación más alta en el conjunto que mostramos). Esto puede ayudarte a encontrar un buen balance entre falsos positivos y falsos negativos.
Una vez que eliges un umbral aceptable para tu modelo en general, puedes hacer clic en etiquetas individuales y ver dónde se ubica ese umbral en la curva de precisión-recuperación correspondiente. En algunos casos, del resultado podría inferirse que obtienes muchas predicciones incorrectas para pocas etiquetas, lo que tal vez te ayude a elegir un umbral por clase personalizado para esas etiquetas. Por ejemplo, supongamos que revisas tu conjunto de datos de casas y observas que un umbral de 0.5 tiene una precisión y recuperación razonables para todos los tipos de imagen, excepto “Tudor”, tal vez porque es una categoría muy general. En esa categoría, encuentras muchos falsos positivos. En ese caso, puedes decidir usar un umbral de 0.8 solo para “Tudor” cuando llames al clasificador a fin de hacer predicciones.
¿Qué es la precisión promedio?
Una métrica útil para la exactitud del modelo es el área bajo la curva de precisión-recuperación. Mide el rendimiento de tu modelo en todos los umbrales de puntuación. En AutoML Vision, esta métrica se llama precisión promedio. Cuanto más cerca de 1.0 esté esta puntuación, mejor será el rendimiento de tu modelo en el conjunto de prueba; un modelo que adivine al azar para cada etiqueta obtendría una precisión promedio de alrededor de 0.5.
Prueba tu modelo
 AutoML Vision usa el 10% de tus datos de forma automática (o el porcentaje que hayas elegido usar, en caso de una división manual) a fin de probar el modelo, y la página “Evaluar” te informa cómo le fue al modelo con esos datos de prueba. Sin embargo, en caso de que quieras verificar la confianza de tu modelo, hay varias formas de hacerlo. La más fácil es subir algunas imágenes en la página “Predecir” y revisar las etiquetas que el modelo elige para tus ejemplos. Con suerte, el resultado coincidirá con lo esperado. Prueba varios ejemplos de cada tipo de imagen que esperas recibir.
AutoML Vision usa el 10% de tus datos de forma automática (o el porcentaje que hayas elegido usar, en caso de una división manual) a fin de probar el modelo, y la página “Evaluar” te informa cómo le fue al modelo con esos datos de prueba. Sin embargo, en caso de que quieras verificar la confianza de tu modelo, hay varias formas de hacerlo. La más fácil es subir algunas imágenes en la página “Predecir” y revisar las etiquetas que el modelo elige para tus ejemplos. Con suerte, el resultado coincidirá con lo esperado. Prueba varios ejemplos de cada tipo de imagen que esperas recibir.
Si deseas usar tu modelo en tus propias pruebas automatizadas, la página “Predecir” también te indica cómo realizar llamadas al modelo de manera programática.