Preparar tus datos de entrenamiento
En esta página, se describe cómo preparar los datos para entrenar un modelo de seguimiento de objetos de video en AutoML.
Prepara tus videos
En esta página, se describe cómo preparar los datos de entrenamiento y prueba para que AutoML Video Intelligence Object Tracking pueda crear un modelo de anotación de video.
La detección de objetos de AutoML Video Intelligence admite los siguientes formatos de video para entrenar tu modelo o solicitar una predicción.
- .MOV
- .MPEG4
- .MP4
- .AVI
El tamaño máximo de los archivos de video de entrenamiento es de 50 GB y hasta 3 horas de duración. En el contenedor, no se admiten archivos de video individuales con compensaciones horarias o con formato incorrecto.
Los datos de entrenamiento deben ser lo más parecidos posible a los datos sobre los que deseas realizar predicciones. Por ejemplo, si tu caso práctico incluye videos borrosos y de baja resolución (como los de una cámara de seguridad), los datos de entrenamiento deben estar compuestos por videos borrosos y de baja resolución. En general, también deberías tratar de proporcionar videos de entrenamiento con múltiples ángulos, resoluciones y fondos.
Generalmente, los modelos de seguimiento de objetos de AutoML Video no pueden predecir etiquetas que las personas no pueden asignar. Por ejemplo, si no se puede entrenar a una persona para que asigne etiquetas con tan solo mirar el video durante 1 o 2 segundos, es probable que tampoco se pueda entrenar al modelo para que lo haga.
El tamaño mínimo del cuadro de límite es de 10 x 10 píxeles.
Para una resolución de fotogramas de video mucho mayor que 1024 píxeles por 1024 píxeles, puede perderse parte de la calidad de imagen durante el proceso de normalización de fotogramas que usa la detección de objetos de AutoML Video.
Los modelos funcionan mejor cuando hay, como máximo, 100 veces más fotogramas para la etiqueta más común que para la etiqueta menos común. Puedes quitar las etiquetas de frecuencia muy baja de tus conjuntos de datos.
Cada etiqueta única debe estar presente en, al menos, 3 marcos de video distintos. Además, cada etiqueta también debe tener un mínimo de 10 anotaciones.
Por el momento, la cantidad máxima de marcos de video etiquetados en cada conjunto de datos es de 150,000.
Por el momento, la cantidad máxima de cuadros de límite anotados en cada conjunto de datos es de 1,000,000.
La cantidad máxima de etiquetas únicas en cada conjunto de datos está limitada a 1,000.
Tus datos de entrenamiento deben tener al menos 1 etiqueta.
Debes proporcionar, al menos, 100 marcos de video de entrenamiento por etiqueta; en cada marco, todos los objetos de interés deben estar etiquetados. No es necesario etiquetar todos los marcos en los que aparecen los objetos, pero cuantos más marcos se etiqueten, mejor será el modelo. Se recomienda elegir marcos no adyacentes entre sí para que puedan abarcar diferentes tamaños, ángulos, fondos, condiciones de iluminación, etcétera.
Conjuntos de datos de entrenamiento, validación y prueba
Los datos en un conjunto de datos se dividen en tres cuando se entrena un modelo: un conjunto de datos de entrenamiento, uno de validación (opcional) y uno de prueba.
- Un conjunto de datos de entrenamiento se usa para compilar un modelo. Cuando se buscan patrones en los datos de entrenamiento, se prueban múltiples algoritmos y parámetros.
- A medida que se identifican los patrones, el conjunto de datos de validación se utiliza para probar los algoritmos y patrones. Los algoritmos y patrones con mejor rendimiento se eligen a partir de aquellos identificados durante la etapa de entrenamiento.
- Una vez identificados, se comprueba la tasa de errores, la calidad y la exactitud mediante el conjunto de datos de prueba.
Se usa tanto una validación como un conjunto de datos de prueba para evitar sesgos en el modelo. Durante la etapa de validación, se usan los parámetros óptimos del modelo, lo que puede dar como resultado métricas sesgadas. El uso del conjunto de datos de prueba para evaluar la calidad del modelo luego de la etapa de validación proporciona una evaluación imparcial sobre la calidad del modelo.
Para identificar tu conjunto de datos de entrenamiento y prueba, usa archivos CSV.
Crea archivos CSV con los URI de video y etiquetas
Una vez que los archivos se subieron a Cloud Storage, puedes crear archivos CSV que enumeren todos tus datos de entrenamiento y las etiquetas de categoría de esos datos. Los archivos CSV pueden tener cualquier nombre de archivo, deben estar codificados en UTF-8 y deben terminar con la extensión .csv.
Existen tres archivos que puedes usar para entrenar y verificar tu modelo:
| File | Descripción |
|---|---|
| Lista de archivos de entrenamiento de modelos | Contiene rutas de acceso a los archivos CSV de entrenamiento y prueba. Este archivo se usa para identificar las ubicaciones de diferentes archivos CSV que describen tus datos de entrenamiento y prueba. A continuación, se muestran algunos ejemplos del contenido del archivo CSV de la lista de archivos: Ejemplo 1: TRAIN,gs://automl-video-demo-data/traffic_videos/traffic_videos_train.csv TEST,gs://automl-video-demo-data/traffic_videos/traffic_videos_test.csv Ejemplo 2: UNASSIGNED,gs://automl-video-demo-data/traffic_videos/traffic_videos_labels.csv |
| Datos de prueba | Se usa para entrenar el modelo. Contiene URI para archivos de video, la etiqueta que identifica la categoría de objeto, el ID de instancia que identifica la instancia del objeto entre los fotogramas de video en un video (opcional), la compensación horaria del marco de video etiquetado y las coordenadas del cuadro de límite de objetos. Si especificas un archivo CSV de datos de entrenamiento, también debes especificar un archivo CSV de datos sin asignar o de prueba. |
| Datos de prueba | Se usan para probar el modelo durante la fase de entrenamiento. Contienen los mismos campos que los datos de entrenamiento. Si especificas un archivo CSV de datos de prueba, también debes especificar un archivo CSV de datos sin asignar o de entrenamiento. |
| Datos sin asignar | Se usan para entrenar y probar el modelo. Contienen los mismos campos que los datos de entrenamiento. Las filas del archivo no asignado se dividen automáticamente en datos de entrenamiento y de prueba. Por lo general, un 80% corresponde a los datos de entrenamiento y un 20% a los de prueba. Solo puedes especificar un archivo CSV de datos sin asignar sin archivos CSV de entrenamiento y de prueba. También puedes especificar solo los archivos CSV de datos de entrenamiento y de prueba sin un archivo CSV de datos sin asignar. |
Los archivos de entrenamiento, de prueba y sin asignar deben tener una fila de un cuadro de límite de objeto en el conjunto que deseas subir, con las siguientes columnas en cada fila:
El contenido a clasificar o anotar. Este campo contiene un URI de Cloud Storage para el video. Los URI de Cloud Storage distinguen mayúsculas de minúsculas.
Una etiqueta que identifica cómo se categoriza el objeto. Las etiquetas deben comenzar con una letra y solo deben contener letras, números y guiones bajos. El seguimiento de objetos de video en AutoML también te permite usar etiquetas con espacios en blanco.
Un ID de instancia que identifica la instancia de objeto entre los fotogramas de video en un video (opcional). El ID de la instancia es un número entero. Si se proporciona, AutoML Video Object Tracking usa el ID para ajustar, entrenar y evaluar el seguimiento de objetos. Los cuadros delimitadores de la misma instancia de objeto presentes en diferentes fotogramas de video se etiquetan como el mismo ID de instancia. El ID de instancia solo es único en cada video, pero no en el conjunto de datos. Por ejemplo, si dos objetos de dos videos diferentes tienen el mismo ID de instancia, no significa que sean la misma instancia de objeto.
La compensación horaria del marco de video que indica la compensación de duración desde el principio del video. La compensación horaria es un número de punto flotante y las unidades están en segundos.
Un cuadro de límite de un objeto en el marco de video. El cuadro de límite para un objeto se puede especificar de las siguientes maneras:
Mediante 2 vértices que consisten en un conjunto de coordenadas x,y si son puntos diagonalmente opuestos del rectángulo, como se muestra en este ejemplo:
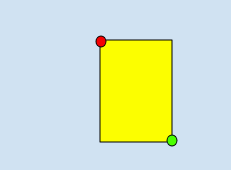
x_relative_min, y_relative_min,,,x_relative_max,y_relative_max,,
- Mediante los 4 vértices:
x_relative_min,y_relative_min,x_relative_max,y_relative_min,x_relative_max,y_relative_max,x_relative_min,y_relative_max
Cada
vertexse especifica mediante valores de coordenadas x, y. Estas coordenadas deben ser un número de punto flotante en el rango del 0 al 1, en el que 0 representa el valor de x o y mínimo, y 1 representa el valor de x o y máximo.Por ejemplo, (0,0) representa la esquina superior izquierda, y (1,1) representa la esquina inferior derecha, un cuadro de límite para toda la imagen se expresa como (0,0,,,1,1,,) o (0,0,1,0,1,1,0,1).
La API de seguimiento de objetos de video en AutoML no requiere un orden de vértices específico. Además, si cuatro vértices especificados no forman un rectángulo paralelo a los bordesde la imagen, la API de seguimiento de objetos de video en AutoML especifica los vértices que forman ese rectángulo.
Ejemplos de archivos de conjuntos de datos CSV
En las siguientes filas, se muestra cómo especificar datos en un conjunto de datos. El ejemplo incluye una ruta de acceso a un video en Cloud Storage, una etiqueta para el objeto, una compensación de tiempo para iniciar el seguimiento y dos vértices diagonales.
video_uri,label,instance_id,time_offset,x_relative_min,y_relative_min, x_relative_max,y_relative_min,x_relative_max,y_relative_max,x_relative_min,y_relative_max
gs://folder/video1.avi,car,,12.90,0.8,0.2,,,0.9,0.3,,
gs://folder/video1.avi,bike,,12.50,0.45,0.45,,,0.55,0.55,,
donde, en la primera fila,
- VIDEO_URI es
gs://folder/video1.avi, - LABEL es
car. - INSTANCE_IDNo especificado,
- TIME_OFFSET es
12.90, - X_RELATIVE_MIN,Y_RELATIVE_MIN son
0.8,0.2, - X_RELATIVE_MAX,Y_RELATIVE_MIN no especificado,
- X_RELATIVE_MAX,Y_RELATIVE_MAX son
0.9,0.3, - X_RELATIVE_MIN,Y_RELATIVE_MAX no se especificaron
Como se mencionó antes, también puedes especificar los cuadros de límite proporcionando los cuatro vértices, como se muestra en los siguientes ejemplos.
gs://folder/video1.avi,car,,12.10,0.8,0.8,0.9,0.8,0.9,0.9,0.8,0.9
gs://folder/video1.avi,car,,12.90,0.4,0.8,0.5,0.8,0.5,0.9,0.4,0.9
gs://folder/video1.avi,car,,12.10,0.4,0.2,0.5,0.2,0.5,0.3,0.4,0.3
No necesitas especificar los datos de validación para verificar los resultados de tu modelo entrenado. El seguimiento de objetos de AutoML Video divide automáticamente las filas identificadas para el entrenamiento en los datos de entrenamiento y validación, en los que el 80% se usa para el entrenamiento y el 20% para la validación.
Soluciona problemas de conjuntos de datos CSV
Si tienes problemas para especificar tu conjunto de datos con un archivo CSV, consulta el archivo CSV a continuación para ver la lista de errores comunes:
- Usar caracteres unicode en las etiquetas. Por ejemplo, los caracteres japoneses no son compatibles.
- Usar espacios y caracteres no alfanuméricos en las etiquetas
- Líneas vacías
- Columnas vacías (líneas con dos comas sucesivas)
- Colocar mayúsculas de manera incorrecta en las rutas de imágenes de Cloud Storage
- Se configuró de manera incorrecta el control de acceso para tus archivos de video. tu cuenta de servicio debe tener acceso de lectura o uno superior, o bien los archivos deben tener acceso público de lectura
- Referencias a archivos que no son de video (como archivos PDF o PSD). Asimismo, los archivos que no son archivos de video, pero que tuvieron un cambio de nombre con una extensión de video, causarán un error
- El URI del video apunta a un bucket diferente que el del proyecto actual. Solo se puede acceder a los videos del bucket del proyecto
- Archivos sin formato CSV