Suivi des objets dans des vidéos
Une fois un modèle créé (entraîné), vous pouvez lui demander d'effectuer une prédiction pour une ou plusieurs vidéos à l'aide de la méthode batchPredict. Vous devez fournir un fichier CSV contenant la liste des vidéos à la méthode batchPredict.
La méthode batchPredict détecte et effectue le suivi des objets que prédit votre modèle afin d'annoter les vidéos.
La durée de vie maximale d'un modèle est de deux ans. Au bout de deux ans, vous devez créer et entraîner un nouveau modèle pour continuer à annoter vos vidéos.
Exemple de prédiction
Pour demander un lot de prédictions à AutoML Video Object Tracking, créez un fichier CSV répertoriant les chemins d'accès Cloud Storage des vidéos que vous souhaitez annoter. Vous pouvez également spécifier une heure de début et une heure de fin pour indiquer à AutoML Video Object Tracking d'annoter seulement une séquence de la vidéo. L'heure de début doit être égale ou supérieure à zéro, et doit être antérieure à l'heure de fin. L'heure de fin doit être supérieure à l'heure de début et inférieure ou égale à la durée de la vidéo.
L'exemple suivant montre comment annoter une vidéo entière en spécifiant les heures de début et de fin comme suit : 0,inf.
gs://my-videos-vcm/cow_video.mp4,0,inf gs://my-videos-vcm/bird_video.mp4,10.00000,15.50000
Vous devez également spécifier le chemin du fichier de sortie dans lequel AutoML Video Object Tracking doit écrire les résultats des prédictions de votre modèle. Ce chemin doit être un bucket et un objet Cloud Storage pour lesquels vous disposez d'autorisations en écriture.
Chaque vidéo peut avoir une durée maximale de 3 heures et une taille de fichier maximale de 50 Go. AutoML Video Object Tracking peut générer des prédictions pour environ 100 heures de vidéo en 12 heures de temps de traitement.
UI Web
- Ouvrez l'interface utilisateur d'AutoML Video Object Tracking.
- Dans la liste affichée, cliquez sur le modèle que vous souhaitez utiliser.
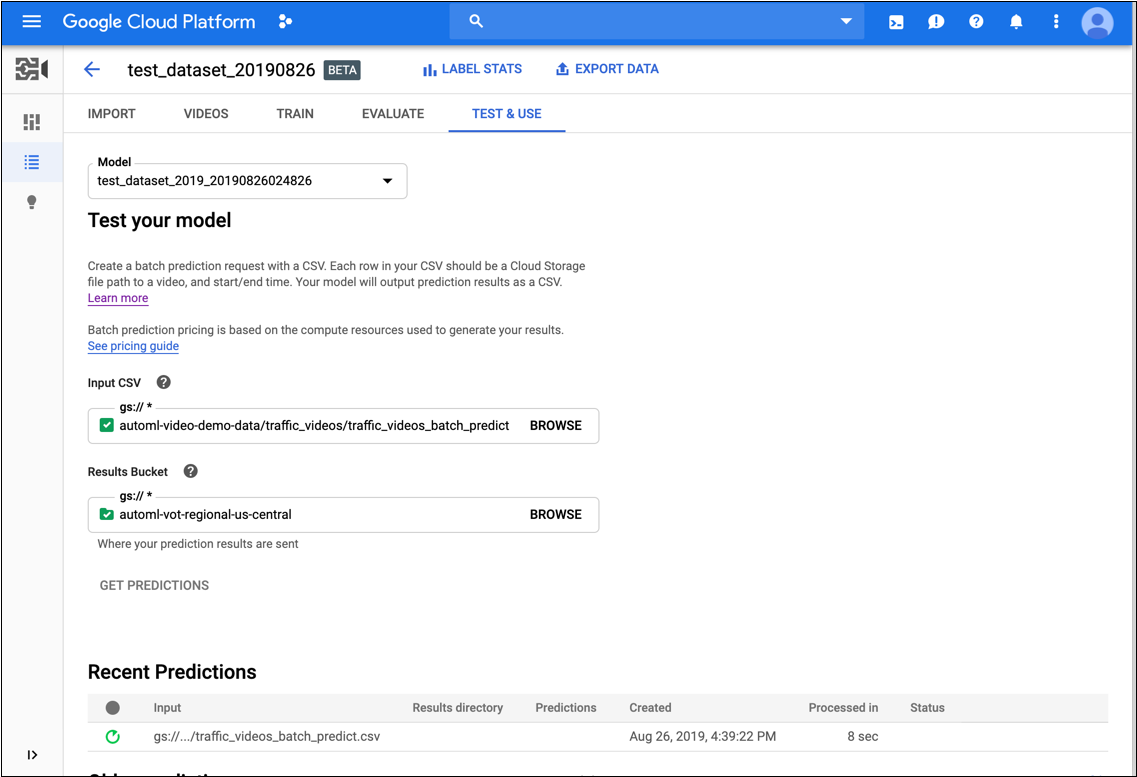
- Dans l'onglet Test & Use (Test et utilisation) du modèle, procédez comme suit :
- Sous Test your model (Tester votre modèle), sélectionnez un fichier CSV à utiliser pour la prédiction. Ce fichier doit fournir la liste des vidéos que vous souhaitez annoter.
Toujours sous Tester votre modèle, sélectionnez un répertoire de votre bucket Cloud Storage où recevoir les résultats des annotations.
Vous voudrez peut-être créer un dossier "résultats" spécifique dans votre bucket Cloud Storage pour stocker les résultats des annotations.
- Cliquez sur Obtenir les prédictions.
L'obtention de prédictions peut prendre un certain temps, selon le nombre de vidéos que vous souhaitez annoter.
Une fois le processus terminé, les résultats apparaissent sur la page du modèle sous Prédictions récentes. Pour afficher les résultats, procédez comme suit :
- Sous Prédictions récentes, dans la colonne Prédictions, cliquez sur Afficher pour la prédiction que vous souhaitez consulter.
- Sous Vidéo, sélectionnez le nom de la vidéo pour laquelle vous souhaitez afficher les résultats.
REST
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- model-id : remplacez cette valeur par l'ID de votre modèle. L'ID est le dernier élément du nom du modèle. Par exemple, si le nom de votre modèle est
projects/project-number/locations/location-id/models/VOT6312181905852727296, l'ID de votre modèle estVOT6312181905852727296. - request-id : attribuez une valeur numérique à ce champ.
- bucket-name : remplacez cette valeur par le nom de votre bucket Cloud Storage. Exemple :
my-project-vcm. - input-file : remplacez cette valeur par le nom du fichier CSV qui identifie les vidéos à annoter.
- output-storage-path : remplacez cette valeur par le chemin d'accès au bucket Cloud Storage où la sortie des prédictions doit être stockée.
AutoML Video Object Tracking crée un sous-dossier pour les résultats dans ce chemin nommé selon le format suivant :
prediction-model_name-timestamp. Le sous-dossier contiendra un fichier de prédiction pour chaque vidéo de la requête de traitement par lot. Vous devez disposer des autorisations en écriture pour ce chemin. - Remarque :
- project-number : numéro de votre projet.
- location-id : région cloud dans laquelle l'annotation doit avoir lieu. Les régions cloud compatibles sont les suivantes :
us-east1,us-west1,europe-west1etasia-east1. Si aucune région n'est spécifiée, une région sera déterminée en fonction de l'emplacement du fichier vidéo.
Méthode HTTP et URL :
POST https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/models/model-id:batchPredict
Corps JSON de la requête :
{
"request_id": "request-id",
"inputConfig": {
"gcsSource": {
"inputUris": ["gs://bucket-name/input-file.csv"]
}
},
"outputConfig": {
"gcsDestination": {
"outputUriPrefix": "gs://output-storage-path"
}
},
"params": {
"score_threshold": "0.0"
}
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-number" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/models/model-id:batchPredict"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-number" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/models/model-id:batchPredict" | Select-Object -Expand Content
VOT1741767155885539328.
Java
Pour vous authentifier auprès du suivi des objets vidéo AutoML, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Node.js
Pour vous authentifier auprès du suivi des objets vidéo AutoML, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Python
Pour vous authentifier auprès du suivi des objets vidéo AutoML, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Obtenir l'état de l'opération de prédiction
Vous pouvez interroger l'état de votre opération de prédiction par lot à l'aide des commandes curl ou PowerShell suivantes.
REST
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- project-number : numéro de votre projet.
- location-id : région cloud dans laquelle l'annotation doit avoir lieu. Les régions cloud compatibles sont les suivantes :
us-east1,us-west1,europe-west1etasia-east1. Si aucune région n'est spécifiée, une région sera déterminée en fonction de l'emplacement du fichier vidéo. - operation-id : ID de l'opération de longue durée créée pour la requête, qui est fourni dans la réponse renvoyée au démarrage de l'opération, par exemple
VOT12345....
Méthode HTTP et URL :
GET https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/operations/operation-id
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Exécutez la commande suivante :
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-number" \
"https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/operations/operation-id"
PowerShell
Exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-number" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/operations/operation-id" | Select-Object -Expand Content
projects/project-number/locations/location-id/operations/operation-id
Une fois la tâche de prédiction par lot terminée, le résultat de la prédiction est stocké dans le bucket Cloud Storage spécifié dans la commande. Chaque séquence vidéo est répertoriée dans un fichier JSON. Les fichiers JSON ont un format semblable à my-video-01.avi.json, où l'extension de fichier .json est ajoutée au nom du fichier d'origine.
{
"inputUris": ["automl-video-demo-data/sample_video.avi"],
"object_annotations": [ {
"annotation_spec": {
"display_name": "Cat",
"description": "Cat"
},
"confidence": 0.43253016
"frames": [ {
"frame": {
"time_offset": {
"seconds": 4,
"nanos": 960000000
},
"normalized_bounding_box": {
"x_min": 0.1,
"y_min": 0.1,
"x_max": 0.8,
"y_max": 0.8
}
}
}, {
"frame": {
"time_offset": {
"seconds": 5,
"nanos": 960000000
},
"normalized_bounding_box": {
"x_min": 0.2,
"y_min": 0.2,
"x_max": 0.9,
"y_max": 0.9
}
}
} ],
"segment": {
"start_time_offset": {
"seconds": 4,
"nanos": 960000000
},
"end_time_offset": {
"seconds": 5,
"nanos": 960000000
}
}
} ],
"error": {
"details": [ ]
}
}