Como anotar vídeos
Depois de treinar um modelo, você pode solicitar uma previsão fornecendo um arquivo CSV para o método batchPredict que lista seus vídeos. O método batchPredict aplica rótulos com base em predições feitas pelo modelo.
A vida útil máxima de um modelo é de dois anos. Em seguida, você precisa treinar um novo modelo.
Exemplo de predição
Para solicitar um lote de predições do AutoML Video, crie um arquivo CSV que liste os caminhos do Cloud Storage para os vídeos que você quer anotar. Você também pode especificar um horário de início e término para instruir a classificação do AutoML Video a anotar apenas um segmento (nível do segmento) do vídeo. O horário de início precisa ser zero ou superior e precisa ser anterior ao horário de término.
O horário de término precisa ser posterior ao horário de início e anterior ou igual à duração do vídeo. Você também pode usar inf para indicar o final de um vídeo.
gs://my-videos-vcm/short_video_1.avi,0.0,5.566667 gs://my-videos-vcm/car_chase.avi,0.0,3.933333 gs://my-videos-vcm/northwest_wildlife_01.avi,0.0,3.7 gs://my-videos-vcm/northwest_wildlife_02.avi,0.0,1.666667 gs://my-videos-vcm/motorcycles_and_cars.avi,0.0,2.633333 gs://my-videos-vcm/drying_paint.avi,0.0,inf
Você também precisa especificar um caminho de arquivo de saída em que o AutoML Video gravará os resultados das predições do seu modelo. Esse caminho precisa ser um bucket e um objeto do Cloud Storage em que você tenha permissões de gravação.
Cada vídeo pode ter até 3 horas de duração com tamanho máximo de arquivo de 50 GB. O AutoML Video pode gerar previsões para aproximadamente 100 horas de vídeo em 12 horas de processamento.
Ao solicitar uma previsão para seus vídeos, você pode definir as seguintes opções na seção params. Se você não especificar nenhuma dessas opções, o limite de pontuação padrão será aplicado, e o segment_classification será usado.
score_threshold: um valor de 0,0 (sem confiança) a 1,0 (muito alta). Quando o modelo faz previsões para um vídeo, ele só produz resultados que tenham pelo menos a pontuação de confiança especificada. O padrão para a API é 0,5.
segment_classification: defina como verdadeiro para ativar a classificação em nível de segmento. O AutoML Video retorna rótulos e as pontuações de confiança deles para todo o trecho de vídeo que você especificou na configuração da solicitação. O padrão é verdadeiro.
shot_classification: defina como verdadeiro para ativar a classificação no nível de imagem. O AutoML Video determina os limites de cada imagem de câmera em todo o trecho do vídeo que você especificou na configuração da solicitação. O AutoML Video Intelligence retorna rótulos e as pontuações de confiança deles para cada imagem detectada, com o horário de início e término delas. O valor padrão é falso.
1s_interval_classification: defina como verdadeiro para ativar a classificação de um vídeo em intervalos de um segundo. O AutoML Video retorna rótulos e pontuações de confiança deles para cada segundo de todo o trecho de vídeo que você especificou na configuração da solicitação. O valor padrão é falso.
IU da Web
- Abra a IU do AutoML Video.
- Na lista exibida, clique no modelo que você quer usar.
- Na guia Testar e usar do modelo, faça o seguinte:
- Em Testar seu modelo, selecione um arquivo CSV que será usado na previsão. No arquivo CSV, é necessário fornecer uma lista de vídeos que você quer anotar.
Ainda em Teste seu modelo, selecione um diretório no bucket do Cloud Storage para receber os resultados da anotação.
Recomendamos que você crie uma pasta específica no bucket do Cloud Storage para armazenar os resultados da anotação. Ao fazer isso, você pode acessar mais facilmente as previsões mais antigas carregando o arquivo
video_classification.csvcontido no diretório de resultados.- Clique em Receber predição.
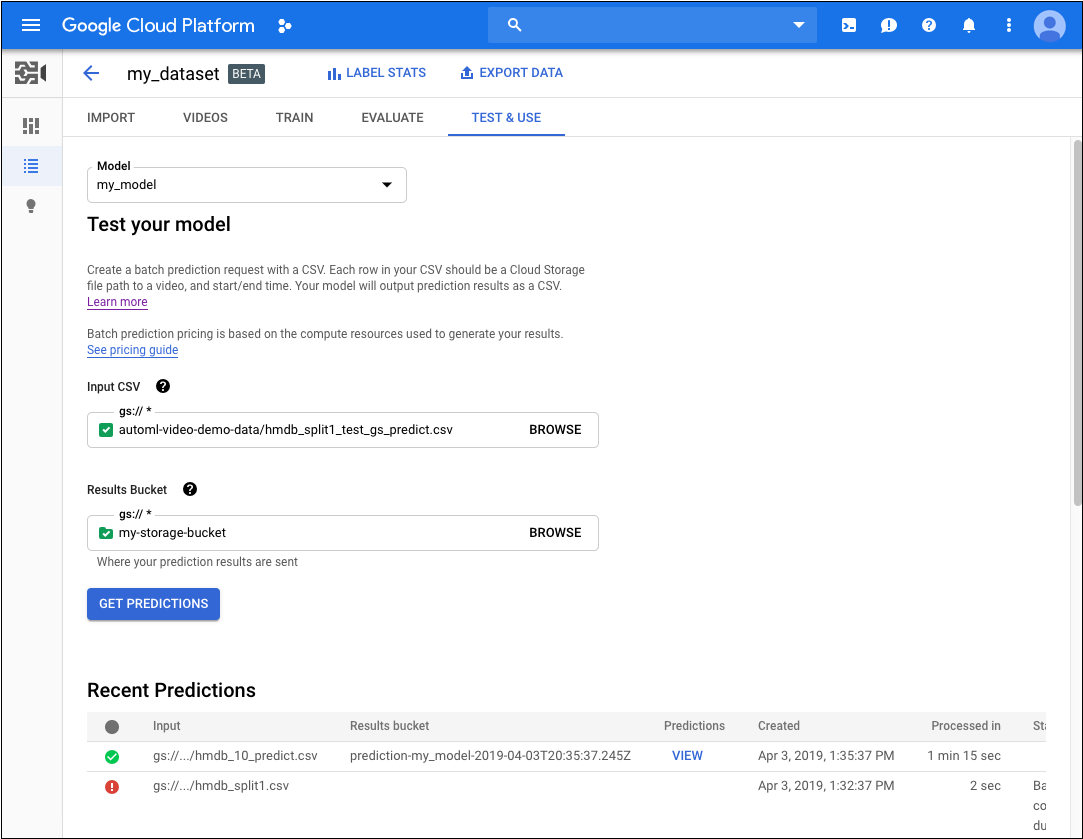
O processo para receber predições leva algum tempo, dependendo do número de vídeos que você quer anotar.
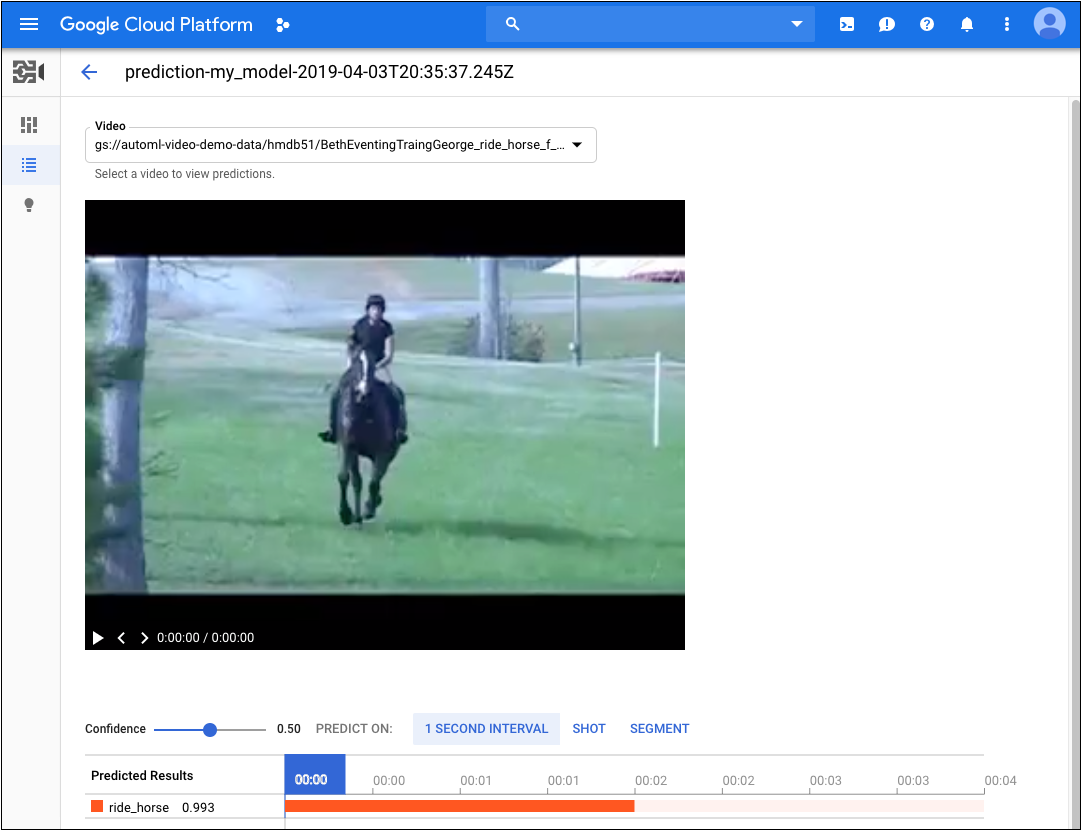
Quando o processo é concluído, os resultados aparecem na página do modelo em Predições recentes. Para ver os resultados, faça o seguinte:
- Em Predições recentes na coluna Predições, clique em Exibir na predição que você quer examinar.
- Em Vídeo, selecione o nome do vídeo com os resultados que você quer ver.
REST
Antes de usar os dados da solicitação, faça as substituições a seguir:
- input-uri: um bucket do Cloud Storage que contém o arquivo que você quer anotar, incluindo o nome do arquivo. Precisa começar com gs://. Por exemplo:
"inputUris": ["gs://automl-video-demo-data/hmdb_split1_test_gs_predict.csv"] - output-bucket substitua pelo nome do bucket no Cloud Storage. Por exemplo:
my-project-vcm - object-id: substitua pelo código da operação de importação de dados.
- Observação:
- project-number: o número do seu projeto
- location-id: a região do Cloud em que a anotação deve ocorrer. As regiões de nuvem compatíveis são:
us-east1,us-west1,europe-west1easia-east1. Se nenhuma região for especificada, uma região será determinada com base na localização do arquivo de vídeo.
Método HTTP e URL:
POST https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/models/model-id:batchPredict
Corpo JSON da solicitação:
{
"inputConfig": {
"gcsSource": {
"inputUris": [input-uri]
}
},
"outputConfig": {
"gcsDestination": {
"outputUriPrefix": "gs://output-bucket/object-id"
}
}
}
Para enviar a solicitação, escolha uma destas opções:
curl
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-number" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/models/model-id:batchPredict "
PowerShell
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-number" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/models/model-id:batchPredict " | Select-Object -Expand Content
Você vai receber um ID de operação para a solicitação de previsão em lote. Por exemplo: VCN926615623331479552.
Dependendo do número de vídeos especificado no arquivo CSV, a tarefa de predição em lote pode levar algum tempo para ser concluída. Quando a tarefa for concluída, você verá done: true no status da operação sem erros listados, conforme mostrado no exemplo a seguir.
{
"name": "projects/project-number/locations/location-id/operations/VCN926615623331479552",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata",
"createTime": "2020-02-11T21:39:19.832131Z",
"updateTime": "2020-02-11T21:43:43.908318Z",
"done": true,
"batchPredictDetails": {
"inputConfig": {
"gcsSource": {
"inputUris": [
"gs://bucket-name/input-file.csv"
]
}
},
"outputInfo": {
"gcsOutputDirectory": "output-storage-path/prediction-test_model_01-2019-01-11T21:39:19.684Z"
}
}
}
}
Quando a tarefa de previsão em lotes é concluída, a saída da previsão é armazenada no bucket do Cloud Storage especificado no seu comando. Há um arquivo JSON para cada trecho de vídeo. Exemplo:
my-video-01.avi.json
{
"input_uri": "automl-video-sample/sample_video.avi",
"segment_classification_annotations": [ {
"annotation_spec": {
"display_name": "ApplyLipstick",
"description": "ApplyLipstick"
},
"segments": [ {
"segment": {
"start_time_offset": {
},
"end_time_offset": {
"seconds": 4,
"nanos": 960000000
}
},
"confidence": 0.43253016
}, {
"segment": {
"start_time_offset": {
},
"end_time_offset": {
"seconds": 4,
"nanos": 960000000
}
},
"confidence": 0.56746984
} ],
"frames": [ ]
} ],
"shot_classification_annotations": [ {
"annotation_spec": {
"display_name": "ApplyLipstick",
"description": "ApplyLipstick"
},
"segments": [ {
"segment": {
"start_time_offset": {
},
"end_time_offset": {
"seconds": 5
}
},
"confidence": 0.43253016
}, {
"segment": {
"start_time_offset": {
},
"end_time_offset": {
"seconds": 5
}
},
"confidence": 0.56746984
} ],
"frames": [ ]
} ],
"one_second_sliding_window_classification_annotations": [ {
"annotation_spec": {
"display_name": "ApplyLipstick",
"description": "ApplyLipstick"
},
"segments": [ ],
"frames": [ {
"time_offset": {
"nanos": 800000000
},
"confidence": 0.54533803
}, {
"time_offset": {
"nanos": 800000000
},
...
"confidence": 0.57945728
}, {
"time_offset": {
"seconds": 4,
"nanos": 300000000
},
"confidence": 0.42054281
} ]
} ],
"object_annotations": [ ],
"error": {
"details": [ ]
}
}
Java
Para se autenticar no AutoML Video, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Node.js
Para se autenticar no AutoML Video, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Python
Para se autenticar no AutoML Video, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.