为视频添加注释
训练模型后,您可以通过向列出视频的 batchPredict 方法提供 CSV 文件来请求预测。batchPredict 方法会根据模型所做的预测应用标签。
模型的最长使用期限为两年。之后,您必须训练新模型。
预测示例
要从 AutoML Video 请求批量预测,请创建一个 CSV 文件,在其中列出了您要添加注释的视频的 Cloud Storage 路径。您还可以指定开始时间和结束时间,让 AutoML Video 仅注释视频片段(片段级别)。开始时间必须等于或大于零,必须早于结束时间。结束时间必须晚于开始时间,并且必须小于或等于视频的时长。您还可以用 inf 指示视频结束。
gs://my-videos-vcm/short_video_1.avi,0.0,5.566667 gs://my-videos-vcm/car_chase.avi,0.0,3.933333 gs://my-videos-vcm/northwest_wildlife_01.avi,0.0,3.7 gs://my-videos-vcm/northwest_wildlife_02.avi,0.0,1.666667 gs://my-videos-vcm/motorcycles_and_cars.avi,0.0,2.633333 gs://my-videos-vcm/drying_paint.avi,0.0,inf
您还必须指定输出文件路径,AutoML Video 会将您模型的预测结果写到该路径下。该路径必须是您有写入权限的 Cloud Storage 存储分区和对象。
每个视频时长不得超过 3 小时,文件大小上限为 50GB。AutoML Video 可在 12 个小时的处理时间内为大约 100 小时的视频生成预测结果。
当您请求对视频进行预测时,可以在 params 部分设置以下选项。如果您未指定以下任何选项,则应用会采用默认分数阈值并使用 segment_classification。
score_threshold - 从 0.0(无置信度)到 1.0(极高置信度)的值。当模型对视频进行预测时,将仅产生至少具有您指定的置信度分数的结果。该 API 的默认值为 0.5。
segment-classification - 设为 true 可启用片段级分类。AutoML Video 会返回您在请求配置中指定的整个视频片段的标签及其置信度分数。默认值为 true。
shot-classification - 设为 true 可启用镜头级分类。AutoML Video 会确定您在请求配置中指定的整个视频片段中每个镜头的边界。然后,AutoML Video Intelligence 会返回检测到的每个镜头的标签及其置信度分数,以及镜头的开始和结束时间。默认值为 false。
1s_interval_classification - 设为 true 可为视频启用以 1 秒钟为间隔执行的分类。AutoML Video 会返回您在请求配置中指定的整个视频片段每一秒的标签及其置信度分数。默认值为 false。
网页界面
- 打开 AutoML Video 界面。
- 从显示的列表中点击要使用的模型。
- 在模型的测试和使用标签页上,执行以下操作:
- 在测试您的模型下,选择要用于预测的 CSV 文件。CSV 文件必须提供要添加注释的视频的列表。
此外,在测试模型下,选择 Cloud Storage 存储分区中的一个目录以接收注释结果。
实际上,您可能想要在 Cloud Storage 存储分区中创建一个特定的“结果”文件夹以用于保存注释结果。 这样,您可以通过加载结果目录中包含的
video_classification.csv文件,更轻松地访问较早的预测结果。- 点击获取预测。
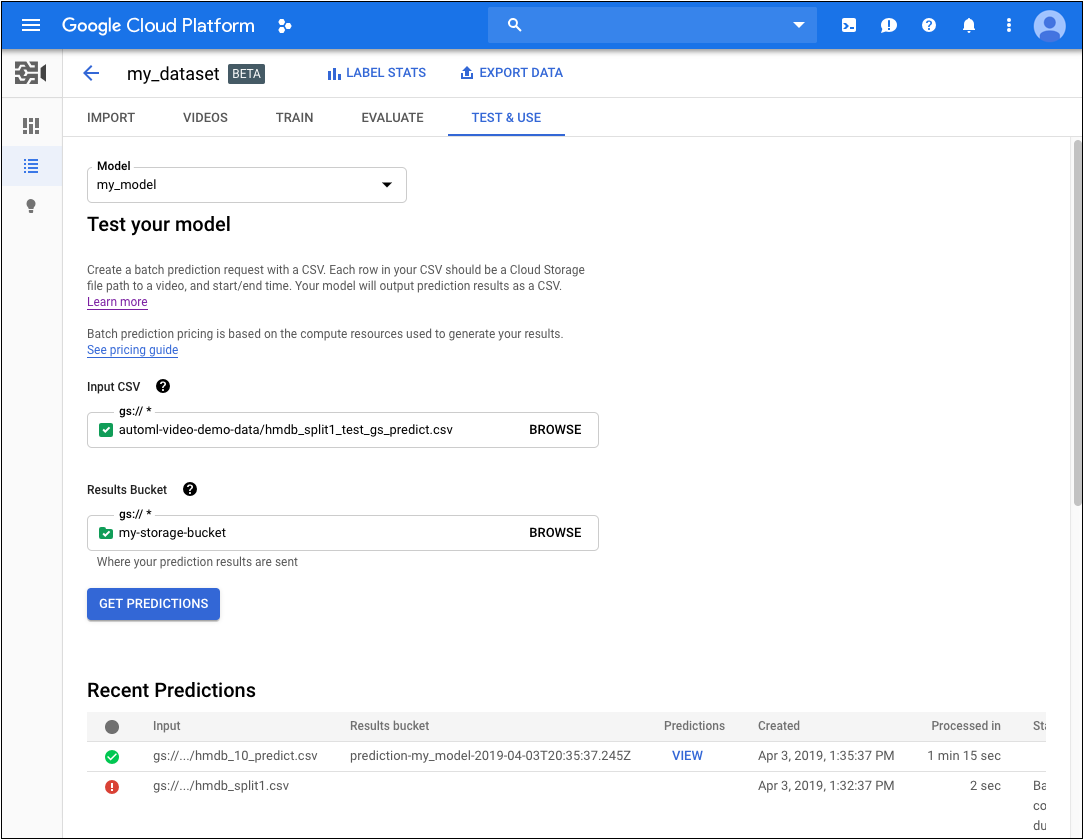
获取预测的过程可能需要一些时间,具体取决于要添加注释的视频数量。
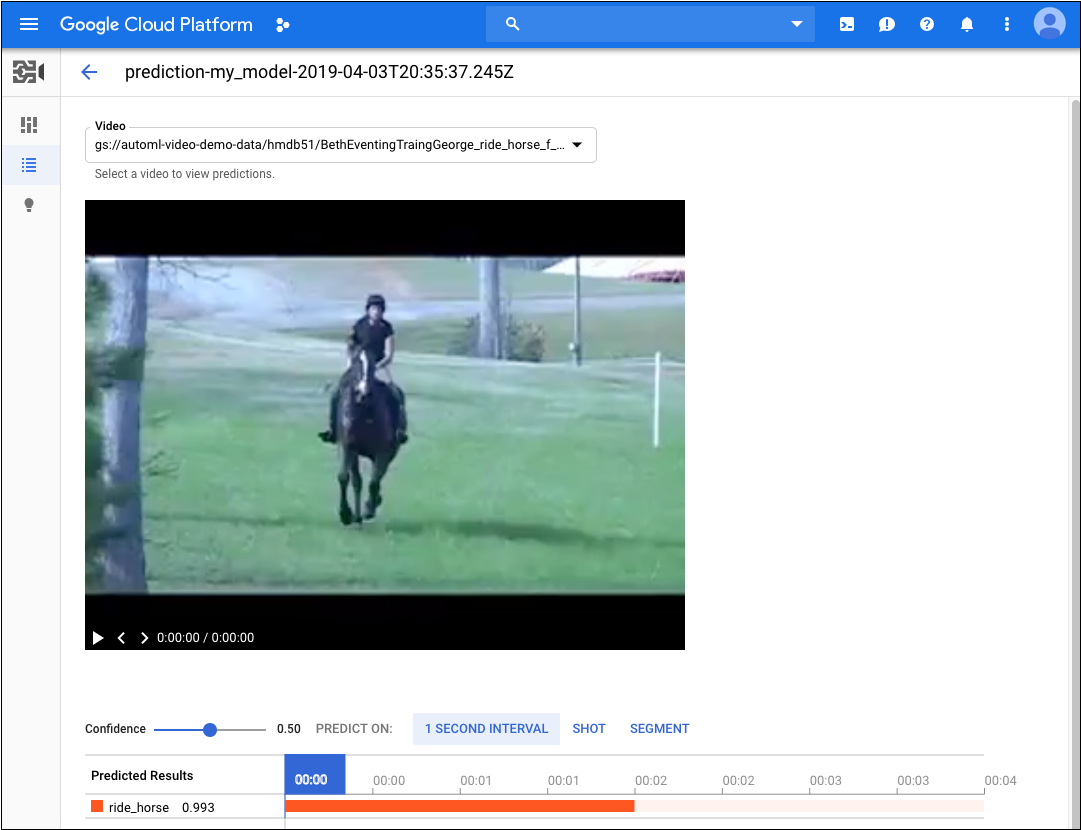
该过程完成后,结果将显示在该模型页面中最近的预测下方。要查看结果,请执行以下操作:
- 在预测列的最近的预测下,点击要查看的预测结果所对应的查看。
- 在视频下,选择要查看其结果的视频的名称。
REST
在使用任何请求数据之前,请先进行以下替换:
- input-uri:包含要添加注释的文件的 Cloud Storage 存储分区(包括文件名)。必须以 gs:// 开头。例如:
"inputUris": ["gs://automl-video-demo-data/hmdb_split1_test_gs_predict.csv"] - 将 output-bucket 替换为您的 Cloud Storage 存储分区名称。例如
my-project-vcm - object-id:替换为导入数据操作的操作 ID。
- 注意:
- project-number:您的项目编号
- location-id:在其中添加注释的 Cloud 区域。支持的云区域为:
us-east1、us-west1、europe-west1、asia-east1。如果未指定区域,系统将根据视频文件位置确定区域。
HTTP 方法和网址:
POST https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/models/model-id:batchPredict
请求 JSON 正文:
{
"inputConfig": {
"gcsSource": {
"inputUris": [input-uri]
}
},
"outputConfig": {
"gcsDestination": {
"outputUriPrefix": "gs://output-bucket/object-id"
}
}
}
如需发送请求,请选择以下方式之一:
curl
将请求正文保存在名为 request.json 的文件中,然后执行以下命令:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-number" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/models/model-id:batchPredict "
PowerShell
将请求正文保存在名为 request.json 的文件中,然后执行以下命令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-number" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://automl.googleapis.com/v1beta1/projects/project-number/locations/location-id/models/model-id:batchPredict " | Select-Object -Expand Content
您应该会收到批量预测请求的操作 ID。例如:VCN926615623331479552。
根据您在 CSV 文件中指定的视频数量,批量预测任务可能需要一些时间才能完成。任务完成后,您将在操作状态中看到 done: true,且无错误列出,如以下示例所示。
{
"name": "projects/project-number/locations/location-id/operations/VCN926615623331479552",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata",
"createTime": "2020-02-11T21:39:19.832131Z",
"updateTime": "2020-02-11T21:43:43.908318Z",
"done": true,
"batchPredictDetails": {
"inputConfig": {
"gcsSource": {
"inputUris": [
"gs://bucket-name/input-file.csv"
]
}
},
"outputInfo": {
"gcsOutputDirectory": "output-storage-path/prediction-test_model_01-2019-01-11T21:39:19.684Z"
}
}
}
}
批量预测任务完成后,预测输出结果将存储在您在命令中指定的 Cloud Storage 存储分区中。每个视频片段都有一个 JSON 文件。例如:
my-video-01.avi.json
{
"input_uri": "automl-video-sample/sample_video.avi",
"segment_classification_annotations": [ {
"annotation_spec": {
"display_name": "ApplyLipstick",
"description": "ApplyLipstick"
},
"segments": [ {
"segment": {
"start_time_offset": {
},
"end_time_offset": {
"seconds": 4,
"nanos": 960000000
}
},
"confidence": 0.43253016
}, {
"segment": {
"start_time_offset": {
},
"end_time_offset": {
"seconds": 4,
"nanos": 960000000
}
},
"confidence": 0.56746984
} ],
"frames": [ ]
} ],
"shot_classification_annotations": [ {
"annotation_spec": {
"display_name": "ApplyLipstick",
"description": "ApplyLipstick"
},
"segments": [ {
"segment": {
"start_time_offset": {
},
"end_time_offset": {
"seconds": 5
}
},
"confidence": 0.43253016
}, {
"segment": {
"start_time_offset": {
},
"end_time_offset": {
"seconds": 5
}
},
"confidence": 0.56746984
} ],
"frames": [ ]
} ],
"one_second_sliding_window_classification_annotations": [ {
"annotation_spec": {
"display_name": "ApplyLipstick",
"description": "ApplyLipstick"
},
"segments": [ ],
"frames": [ {
"time_offset": {
"nanos": 800000000
},
"confidence": 0.54533803
}, {
"time_offset": {
"nanos": 800000000
},
...
"confidence": 0.57945728
}, {
"time_offset": {
"seconds": 4,
"nanos": 300000000
},
"confidence": 0.42054281
} ]
} ],
"object_annotations": [ ],
"error": {
"details": [ ]
}
}
Java
如需向 AutoML Video 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
Node.js
如需向 AutoML Video 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。
Python
如需向 AutoML Video 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。