Introduzione
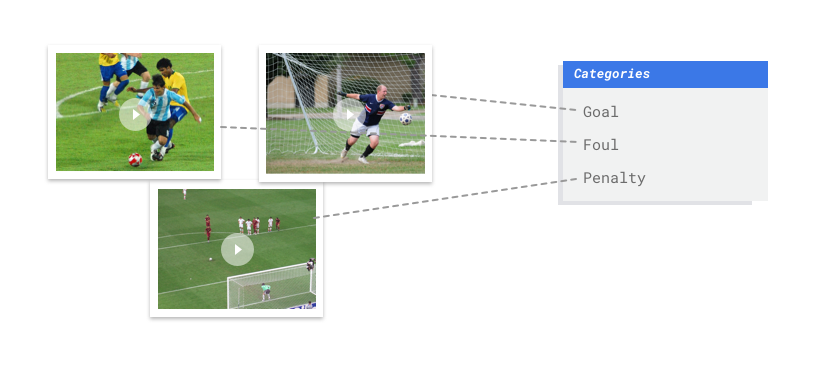
Immagina di essere l'allenatore di una squadra di calcio. Hai una vasta raccolta video di giochi che vorresti utilizzare per studiare i punti di forza e di debolezza della tua squadra. Sarebbe incredibilmente utile compilare azioni come gol, falli e calci di rigore di molte partite in un unico video. Ma ci sono centinaia di ore di video da esaminare e molte azioni da monitorare. Guardare ogni video e contrassegnare manualmente i segmenti per mettere in evidenza ciascuna azione è noioso e dispendioso in termini di tempo. E dovrai fare questo lavoro per ogni stagione. Non sarebbe più facile insegnare a un computer a identificare e segnalare automaticamente queste azioni ogni volta che appaiono in un video?
Perché il machine learning (ML) è lo strumento giusto per risolvere questo problema?
 Per utilizzare la programmazione classica, un programmatore deve specificare le istruzioni passo passo che il computer deve seguire. Considera però il caso d'uso dell'identificazione di azioni specifiche nei giochi di calcio. Le variazioni di colore, angolazione, risoluzione e illuminazione sono così tante che richiederebbero la codifica di un numero eccessivo di regole per indicare a una macchina come prendere la decisione corretta. È difficile immaginare da dove iniziare.
Fortunatamente, il machine learning ha le carte in regola per risolvere questo problema.
Per utilizzare la programmazione classica, un programmatore deve specificare le istruzioni passo passo che il computer deve seguire. Considera però il caso d'uso dell'identificazione di azioni specifiche nei giochi di calcio. Le variazioni di colore, angolazione, risoluzione e illuminazione sono così tante che richiederebbero la codifica di un numero eccessivo di regole per indicare a una macchina come prendere la decisione corretta. È difficile immaginare da dove iniziare.
Fortunatamente, il machine learning ha le carte in regola per risolvere questo problema.
Questa guida illustra in che modo AutoML Video Intelligence Classification può risolvere questo problema, il relativo flusso di lavoro e gli altri tipi di problemi per cui è stata progettata.
Come funziona AutoML Video Intelligence Classification?
 AutoML Video Intelligence Classification è un'attività di apprendimento supervisionato. Ciò significa che
addestra, test e convalida il modello di machine learning con video di esempio
già etichettati. Con un modello addestrato, puoi inserire nuovi video e il modello produrrà segmenti video con etichette. Un'etichetta è una "risposta" prevista dal modello. Ad esempio, un modello addestrato per il caso d'uso del calcio ti consente di inserire nuovi video sul calcio e di generare segmenti video con etichette che descrivono i colpi di azione come "gol", "fallo personale" e così via.
AutoML Video Intelligence Classification è un'attività di apprendimento supervisionato. Ciò significa che
addestra, test e convalida il modello di machine learning con video di esempio
già etichettati. Con un modello addestrato, puoi inserire nuovi video e il modello produrrà segmenti video con etichette. Un'etichetta è una "risposta" prevista dal modello. Ad esempio, un modello addestrato per il caso d'uso del calcio ti consente di inserire nuovi video sul calcio e di generare segmenti video con etichette che descrivono i colpi di azione come "gol", "fallo personale" e così via.
Flusso di lavoro di AutoML Video Intelligence Classification
AutoML Video Intelligence Classification utilizza un flusso di lavoro standard per il machine learning:
- Raccogli i dati: determina i dati necessari per l'addestramento e il test del modello in base al risultato che vuoi ottenere.
- Prepara i dati: assicurati che i dati siano formattati ed etichettati correttamente.
- Addestra: imposta i parametri e crea il modello.
- Valuta: esamina le metriche del modello.
- Esegui il deployment e prevedi: rendi il modello disponibile per l'uso.
Ma prima di iniziare a raccogliere i dati, è bene pensare al problema che stai cercando di risolvere, che determinerà i requisiti dei tuoi dati.
Considera il tuo caso d'uso

Inizia con il tuo problema: qual è il risultato che vuoi ottenere? Quante classi devi prevedere? Una classe è qualcosa che il modello deve imparare a identificare ed è rappresentata nell'output del modello come etichetta (ad esempio, un modello di rilevamento palla avrà due classi: "ball" e "no ball").
A seconda delle tue risposte, AutoML Video Intelligence Classification creerà il modello necessario per risolvere il tuo caso d'uso:
Un modello di classificazione binaria prevede un risultato binario (una di due classi). Utilizzalo per le domande che prevedono sì o no come risposta, ad esempio identificando solo gli obiettivi in una partita di calcio ("È un obiettivo o non un obiettivo?"). In generale, un problema di classificazione binaria richiede meno dati video per l'addestramento rispetto ad altri problemi.
Un modello di classificazione multi-classe prevede una classe da due o più classi discrete. Utilizzalo per classificare i segmenti video. Ad esempio, classificare i segmenti di una raccolta video olimpica per capire quale sport viene mostrato in un determinato momento. L'output fornisce segmenti video assegnati a una singola etichetta, come nuoto o ginnastica.
Un modello di classificazione con più etichette prevede una o più classi di molte classi possibili. Utilizza questo modello per etichettare più classi in un singolo segmento video. Questo tipo di problema spesso richiede più dati di addestramento perché la distinzione tra più classi è più complessa.
L'esempio del calcio precedente richiederebbe una modalità di classificazione con più etichette, perché le classi (azioni come gol, falli personali ecc.) possono avvenire contemporaneamente, il che significa che un singolo segmento video potrebbe richiedere più etichette.
Una nota sull'equità
L'equità è una delle pratiche dell'IA responsabile di Google. L'obiettivo dell'equità è comprendere e prevenire trattamenti ingiusti o pregiudizievoli nei confronti delle persone in base a gruppo etnico, reddito, orientamento sessuale, religione, genere e altre caratteristiche storicamente associate a discriminazione ed emarginazione, nonché a capire quando e dove si manifestano in sistemi algoritmici o processi decisionali assistiti da algoritmi. Mentre leggi questa guida, noterai delle note "fair-aware" che illustrano meglio come creare un modello di machine learning più equo. Scopri di più
Raccogli i tuoi dati
 Dopo aver definito il tuo caso d'uso, dovrai raccogliere i dati video che ti permetteranno di creare il modello che preferisci. I dati raccolti per l'addestramento indicano il tipo di problemi che puoi risolvere. Quanti video puoi usare? I video contengono esempi sufficienti per le classi che vuoi che il modello preveda? Durante la raccolta dei dati video, tieni presente le seguenti considerazioni.
Dopo aver definito il tuo caso d'uso, dovrai raccogliere i dati video che ti permetteranno di creare il modello che preferisci. I dati raccolti per l'addestramento indicano il tipo di problemi che puoi risolvere. Quanti video puoi usare? I video contengono esempi sufficienti per le classi che vuoi che il modello preveda? Durante la raccolta dei dati video, tieni presente le seguenti considerazioni.
Includi un numero sufficiente di video
 In genere, maggiore è il numero di video di addestramento nel set di dati, migliore sarà il risultato. Il numero di video consigliati aumenta anche la complessità del problema che stai cercando di risolvere. Ad esempio, avrai bisogno di meno dati video per un problema di classificazione binaria (previsione di una classe su due) rispetto a un problema con più etichette (previsione di una o più classi da molte).
In genere, maggiore è il numero di video di addestramento nel set di dati, migliore sarà il risultato. Il numero di video consigliati aumenta anche la complessità del problema che stai cercando di risolvere. Ad esempio, avrai bisogno di meno dati video per un problema di classificazione binaria (previsione di una classe su due) rispetto a un problema con più etichette (previsione di una o più classi da molte).
Anche la complessità di cosa stai cercando di classificare può determinare la quantità di dati video di cui hai bisogno. Prendiamo in considerazione il caso d'uso del calcio, ovvero la creazione di un modello per distinguere gli scatti d'azione. Confrontalo con un modello che distingue tra le specie di colibrì. Considera le sfumature e le somiglianze in termini di colore, dimensione e forma: sono necessari più dati di addestramento per far sì che il modello impari a identificare con precisione ogni specie.
Utilizza queste regole come base per comprendere le esigenze minime in termini di dati video:
- 200 esempi di video per classe se hai poche classi e sono distinti
- Oltre 1000 esempi video per classe se hai più di 50 classi o se le classi sono simili
La quantità di dati video richiesti potrebbe essere superiore a quella attualmente disponibile. Prendi in considerazione l'acquisto di altri video tramite un fornitore di terze parti. Ad esempio, potresti acquistare o acquistare altri video sul calcio se non ne hai abbastanza per il tuo modello di identificatore di azioni di gioco.
Distribuisci equamente i video tra le classi
Prova a fornire un numero simile di esempi di addestramento per ogni corso. Il motivo è che: Immagina che l'80% del tuo set di dati sull'allenamento sia costituito da video di calcio con tiri di gol, ma solo il 20% di questi video mostra falli personali o calci di rigore. Con una distribuzione disuguale delle classi, è più probabile che il modello preveda che una data azione è un obiettivo. È un po' come scrivere un test a scelta multipla in cui l'80% delle risposte corrette è "C": il modello più esperto capirà subito che "C" è una buona ipotesi il più delle volte.

Potrebbe non essere possibile fornire lo stesso numero di video per ogni corso. Anche gli esempi imparziali e di alta qualità possono essere difficili per alcune classi. Prova a utilizzare un rapporto 1:10: se la classe più numerosa ha 10.000 video, la più piccola deve avere almeno 1000 video.
Acquisisci variante
I dati dei tuoi video dovrebbero comprendere la diversità dello spazio problematico. Più sono gli esempi diversificati che un modello vede durante l'addestramento, più facilmente può generalizzare a esempi nuovi o meno comuni. Pensa al modello di classificazione delle azioni nel calcio: dovresti includere video con diverse angolazioni di ripresa, di giorno e di notte e di movimenti dei giocatori. Esporre il modello a una varietà di dati migliorerà la sua capacità di distinguere un'azione dall'altra.
Abbina i dati all'output previsto

Trova video di addestramento visivamente simili a quelli che vuoi inserire nel modello per la previsione. Ad esempio, se tutti i video di addestramento vengono girati in inverno o di sera, i pattern di illuminazione e colori di questi ambienti influiranno sul modello. Se poi lo utilizzi per testare i video girati in estate o durante il giorno, potresti non ricevere previsioni accurate.
Considera questi altri fattori: * Risoluzione video * Fotogrammi video al secondo * Angolo della videocamera * Sfondo
Preparare i dati

Dopo aver raccolto i video da includere nel set di dati, devi assicurarti che contengano riquadri di delimitazione con etichette in modo che il modello sappia cosa cercare.
Perché i miei video hanno bisogno di riquadri di delimitazione ed etichette?
In che modo un modello AutoML Video Intelligence Classification impara a identificare i pattern? Questa è la funzione dei riquadri di delimitazione e delle etichette durante l'addestramento. Prendiamo l'esempio del calcio: ogni video di esempio dovrà contenere riquadri di delimitazione intorno alle scene d'azione. Queste caselle devono anche assegnare etichette come "gol", "fallo personale" e "calcio di rigore". In caso contrario, il modello non saprà cosa cercare. Creare caselle di disegno e assegnare etichette ai video di esempio può richiedere tempo. Se necessario, valuta la possibilità di utilizzare un servizio di etichettatura per esternalizzare il lavoro ad altri.
addestra il modello
Dopo aver preparato i dati del video di addestramento, puoi creare un modello di machine learning. Tieni presente che puoi utilizzare lo stesso set di dati per creare modelli di machine learning diversi, anche se hanno tipi di problemi diversi.
Uno dei vantaggi di AutoML Video Intelligence Classification è che i parametri predefiniti ti guideranno verso un modello di machine learning affidabile. Tuttavia, potresti dover regolare i parametri a seconda della qualità dei dati e del risultato che ti aspetti. Ad esempio:
- Tipo di previsione (il livello di granularità dell'elaborazione dei video)
- Frequenza fotogrammi
- Risoluzione
Valuta il modello
 Dopo l'addestramento del modello, riceverai un riepilogo delle sue prestazioni. Le metriche di valutazione del modello si basano sul rendimento del modello rispetto a una sezione del set di dati (il set di dati di convalida). Ci sono un paio di metriche e concetti chiave da considerare
per determinare se il tuo modello è pronto per essere utilizzato nei dati reali.
Dopo l'addestramento del modello, riceverai un riepilogo delle sue prestazioni. Le metriche di valutazione del modello si basano sul rendimento del modello rispetto a una sezione del set di dati (il set di dati di convalida). Ci sono un paio di metriche e concetti chiave da considerare
per determinare se il tuo modello è pronto per essere utilizzato nei dati reali.
Soglia punteggio
Come fa un modello di machine learning a sapere quando un obiettivo da calcio è davvero un obiettivo? A ogni previsione viene assegnato un punteggio di affidabilità, ovvero una valutazione numerica del livello di certezza del modello che un determinato segmento video contiene una classe. La soglia di punteggio è il numero che determina quando un determinato punteggio viene convertito in una decisione di tipo sì o no, ovvero il valore al quale il modello indica "sì, questo numero di confidenza è sufficientemente alto da concludere che il segmento video contiene un obiettivo".

Se la soglia di punteggio è bassa, il modello rischia di etichettare in modo errato i segmenti video. Per questo motivo, la soglia di punteggio deve essere basata su un determinato caso d'uso. Immagina un caso d'uso medico come la diagnosi del cancro, in cui le conseguenze di un'etichettatura erronea sono maggiori dell'etichettatura errata dei video sportivi. Nella diagnosi dei tumori, una soglia di punteggio più alta è appropriata.
Risultati della previsione
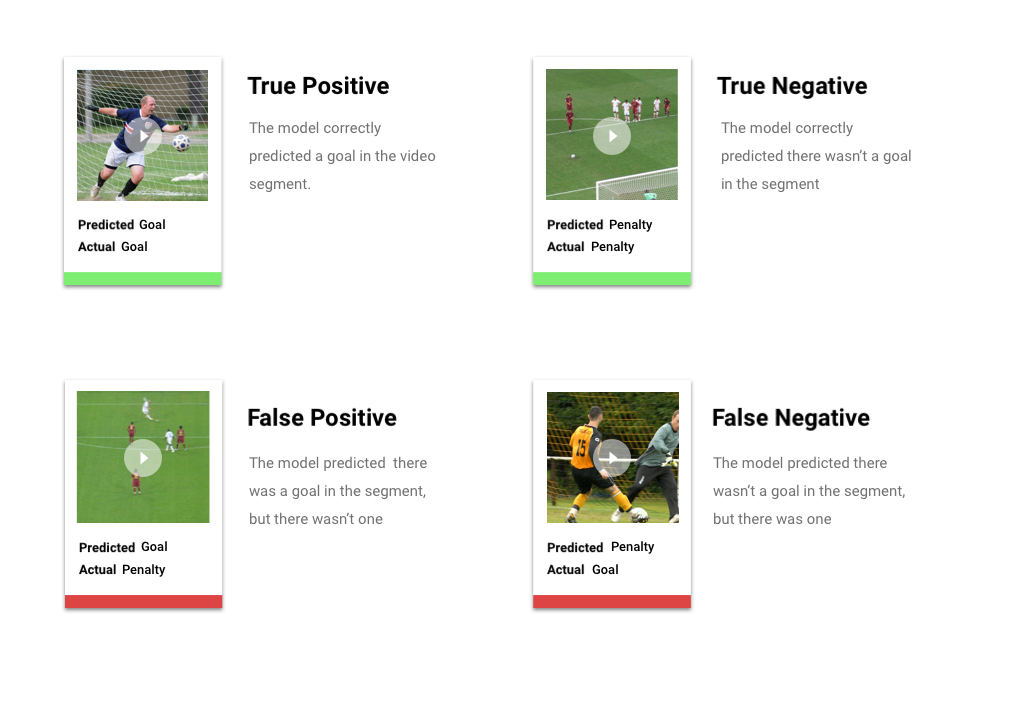
Dopo aver applicato la soglia di punteggio, le previsioni effettuate dal modello rientrano in una di quattro categorie. Per capire queste categorie, supponiamo di aver creato un modello per rilevare se un determinato segmento contiene o meno una porta da calcio. In questo esempio, un obiettivo è la classe positiva (quella che il modello cerca di prevedere).
- Vero positivo: il modello prevede correttamente la classe positiva. Il modello ha previsto correttamente un obiettivo nel segmento video.
- Falso positivo: il modello prevede erroneamente la classe positiva. Il modello ha previsto che un obiettivo era nel segmento, ma non c'era.
- Vero negativo: il modello prevede correttamente la classe negativa. Il modello ha previsto correttamente la mancanza di un obiettivo nel segmento.
- Falso negativo: il modello prevede erroneamente una classe negativa. Il modello prevedeva che il segmento non avesse un obiettivo, ma ce n'era uno.
Precisione e richiamo
Le metriche di precisione e richiamo ti aiutano a capire in che misura il tuo modello sta acquisendo le informazioni e cosa sta omettendo. Scopri di più su precisione e richiamo
- La precisione è la frazione di previsioni positive che sono risultate corrette. Tra tutte le previsioni contrassegnate come "obiettivo", quale frazione conteneva effettivamente un obiettivo?
- Il richiamo è la frazione di tutte le previsioni positive che sono state effettivamente identificate. Di tutti i gol di calcio che si sarebbero potuti identificare, quale frazione era?
A seconda del tuo caso d'uso, potrebbe essere necessario ottimizzare la precisione o il richiamo. Considera i seguenti casi d'uso.
Caso d'uso: informazioni private nei video
Immagina di creare un software che rileva automaticamente le informazioni sensibili in un video e le sfoca. Le conseguenze di falsi risultati possono includere:
- Un falso positivo identifica qualcosa che non deve essere censurato, ma che viene comunque censurato. Questo potrebbe essere fastidioso, ma non dannoso.

- Un falso negativo non identifica le informazioni che devono essere censurate, come il numero di carta di credito. Questo consentirebbe di divulgare informazioni private ed è lo scenario peggiore.
In questo caso d'uso, è fondamentale ottimizzare per il richiamo per garantire che il modello trovi tutti i casi pertinenti. Un modello ottimizzato per il richiamo ha maggiori probabilità di etichettare esempi marginalmente pertinenti, ma anche più propensi a etichettare quelli errati (sfocando più del necessario).
Caso d'uso: ricerca di video stock
Supponiamo che tu voglia creare un software che consenta agli utenti di effettuare ricerche in una raccolta di video in base a una parola chiave. Consideriamo i risultati errati:
- Un falso positivo restituisce un video non pertinente. Dal momento che il tuo sistema sta cercando di fornire solo video pertinenti, il tuo software non sta realmente facendo ciò per cui è stato progettato.

- Un falso negativo non restituisce un video pertinente. Poiché molte parole chiave contengono centinaia di video, questo problema non è un male, in quanto restituisce un video non pertinente.

In questo esempio, ti consigliamo di ottimizzare la precisione per assicurarti che il modello fornisca risultati altamente pertinenti e corretti. È probabile che un modello ad alta precisione etichetta solo gli esempi più pertinenti, ma potrebbero escluderne alcuni. Scopri di più sulle metriche di valutazione del modello
Esegui il deployment del modello
 Quando le prestazioni del modello ti soddisfano, è il momento di utilizzarlo.
AutoML Video Intelligence Classification utilizza la previsione batch, che consente di caricare un file CSV
con i percorsi dei video ospitati su Cloud Storage. Il modello elaborerà ogni previsione video e di output in un altro file CSV. La previsione batch è asincrona, ovvero il modello elaborerà tutte le richieste di previsione prima di restituire i risultati.
Quando le prestazioni del modello ti soddisfano, è il momento di utilizzarlo.
AutoML Video Intelligence Classification utilizza la previsione batch, che consente di caricare un file CSV
con i percorsi dei video ospitati su Cloud Storage. Il modello elaborerà ogni previsione video e di output in un altro file CSV. La previsione batch è asincrona, ovvero il modello elaborerà tutte le richieste di previsione prima di restituire i risultati.