Introduction
Imaginez que vous êtes entraîneur d'une équipe de football. Vous disposez d'une vaste vidéothèque de matchs que vous souhaitez visionner en vue d'étudier les forces et les faiblesses de votre équipe. Pouvoir compiler des actions telles que les buts, les fautes et les tirs au but de plusieurs matchs en une seule vidéo vous serait d'une très grande utilité. Cependant, cela impliquerait des centaines d'heures de visionnage appliqué et de très nombreuses actions à suivre. Qui plus est, visionner chaque vidéo en délimitant manuellement les séquences pour mettre en évidence chaque action est un travail tout aussi fastidieux que chronophage, qui doit être répété à chaque saison. Ne serait-il pas plus facile d'apprendre à un ordinateur à identifier et à signaler automatiquement ces actions lorsqu'elles apparaissent dans une vidéo ?
En quoi un système de machine learning (ML) constitue-t-il un outil adapté pour résoudre ce problème ?
 La programmation classique nécessite qu'un programmeur spécifie des instructions détaillées que l'ordinateur doit suivre. Mais prenons le cas d'utilisation qui consiste à identifier des actions spécifiques dans les matchs de football. Il existe tellement de variations de couleur, d'angle, de résolution et de luminosité qu'il faudrait coder beaucoup trop de règles pour indiquer à une machine comment prendre la bonne décision. Difficile d'imaginer par où commencer.
Heureusement, le machine learning est bien placé pour résoudre ce problème.
La programmation classique nécessite qu'un programmeur spécifie des instructions détaillées que l'ordinateur doit suivre. Mais prenons le cas d'utilisation qui consiste à identifier des actions spécifiques dans les matchs de football. Il existe tellement de variations de couleur, d'angle, de résolution et de luminosité qu'il faudrait coder beaucoup trop de règles pour indiquer à une machine comment prendre la bonne décision. Difficile d'imaginer par où commencer.
Heureusement, le machine learning est bien placé pour résoudre ce problème.
Ce guide explique comment la classification AutoML Video Intelligence peut résoudre ce problème, ainsi que d'autres types de problèmes, et décrit le workflow associé.
Comment fonctionne la classification AutoML Video Intelligence ?
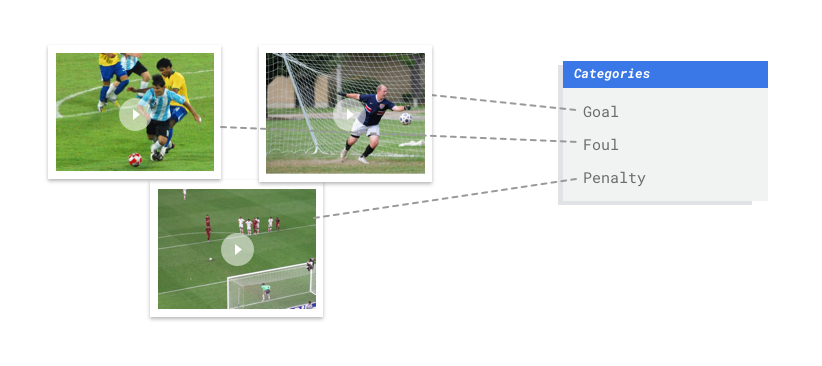
 La classification AutoML Video Intelligence est une tâche d'apprentissage supervisé. Cela signifie que vous entraînez, testez et validez le modèle de machine learning à partir d'exemples vidéo déjà étiquetés. Avec un modèle entraîné, vous pouvez introduire de nouvelles vidéos pour que ce dernier génère des séquences étiquetées. Une étiquette est une "réponse" prédite par le modèle. Par exemple, dans le cas du football, un modèle entraîné vous permettrait d'introduire de nouvelles vidéos de football et de générer des séquences vidéo étiquetées décrivant des actions telles que le "but", la "faute personnelle", etc.
La classification AutoML Video Intelligence est une tâche d'apprentissage supervisé. Cela signifie que vous entraînez, testez et validez le modèle de machine learning à partir d'exemples vidéo déjà étiquetés. Avec un modèle entraîné, vous pouvez introduire de nouvelles vidéos pour que ce dernier génère des séquences étiquetées. Une étiquette est une "réponse" prédite par le modèle. Par exemple, dans le cas du football, un modèle entraîné vous permettrait d'introduire de nouvelles vidéos de football et de générer des séquences vidéo étiquetées décrivant des actions telles que le "but", la "faute personnelle", etc.
Workflow de la classification AutoML Video Intelligence
La classification AutoML Video Intelligence repose sur un workflow de machine learning standard :
- Collecte de données : vous déterminez les données dont vous avez besoin pour entraîner et tester votre modèle en fonction du résultat que vous souhaitez obtenir.
- Préparation des données : vous vérifiez que vos données sont correctement formatées et étiquetées.
- Entraînement : vous définissez les paramètres et construisez votre modèle.
- Évaluation : vous examinez les métriques du modèle.
- Déploiement et prédiction : vous rendez votre modèle disponible à l'utilisation.
Avant de commencer à collecter des données, vous devez toutefois réfléchir au problème que vous essayez de résoudre. Cela vous permettra de déterminer vos besoins en termes de données.
Considérer votre cas d'utilisation

Commencez par réfléchir à votre problème : quel résultat souhaitez-vous obtenir ? Combien de classes avez-vous besoin de prédire ? Une classe est un élément que votre modèle doit apprendre à identifier et qui est représenté dans les résultats sous forme d'étiquette (par exemple, un modèle de détection de ballon aura deux classes : "ballon" et "aucun ballon").
En fonction des réponses, la classification AutoML Video Intelligence crée le modèle nécessaire pour trouver une solution à votre cas d'utilisation :
Un modèle de classification binaire prédit un résultat binaire (l'une des deux classes). Il convient aux questions de type "oui" ou "non", par exemple pour identifier seulement les buts d'un match de foot ("s'agit-il d'un but ou non ?). En général, un problème de classification binaire nécessite moins de données vidéo à traiter que les autres types de problèmes.
Un modèle de classification à classes multiples prédit une classe à partir de deux classes discrètes ou plus. Utilisez cette option pour classifier les séquences vidéo. Par exemple, la classification des séquences vidéo d'une vidéothèque des Jeux olympiques permet de déterminer quel sport est présenté à un moment donné. Le résultat assigne des séquences vidéo à une seule étiquette, par exemple la natation ou la gymnastique.
Un modèle de classification à étiquettes multiples prédit une ou plusieurs classes parmi plusieurs classes possibles. Utilisez ce modèle pour étiqueter plusieurs classes au sein d'une seule séquence vidéo. Souvent, ce type de problème nécessite davantage de données d'entraînement parce que la distinction entre plusieurs classes est plus complexe.
Dans l'exemple précédent du football, un mode de classification à étiquettes multiples se justifie parce que les classes (actions telles que buts, fautes personnelles, etc.) peuvent se dérouler simultanément, ce qui signifie qu'une seule séquence vidéo peut requérir plusieurs étiquettes.
Un mot sur l'équité
L'équité est l'un des principes fondamentaux des pratiques de Google en matière d'IA responsable. L'objectif de promouvoir l'équité consiste à comprendre et prévenir les traitements injustes ou préjudiciables envers les personnes, fondés sur la race, le revenu, l'orientation sexuelle, la religion, le sexe, ainsi que toute autre caractéristique historiquement associée à la discrimination et à la marginalisation. Plus précisément, il s'agit de savoir quand et où ces traitements se manifestent dans les systèmes algorithmiques ou les processus décisionnels basés sur des algorithmes. En lisant ce guide, vous trouverez des remarques intitulées "Pensez équité" qui expliquent précisément comment créer un modèle de machine learning plus équitable. En savoir plus
Collecter les données
 Une fois que vous avez établi votre cas d'utilisation, vous devez collecter les données vidéo qui vous permettront de créer le modèle souhaité. Les données que vous collectez pour l'entraînement déterminent le type de problèmes que vous pouvez résoudre. Combien de vidéos pouvez-vous utiliser ? Les vidéos contiennent-elles suffisamment d'exemples pour les classes que le modèle doit prédire ? Lorsque vous collectez les données de vos vidéos, tenez compte des points suivants.
Une fois que vous avez établi votre cas d'utilisation, vous devez collecter les données vidéo qui vous permettront de créer le modèle souhaité. Les données que vous collectez pour l'entraînement déterminent le type de problèmes que vous pouvez résoudre. Combien de vidéos pouvez-vous utiliser ? Les vidéos contiennent-elles suffisamment d'exemples pour les classes que le modèle doit prédire ? Lorsque vous collectez les données de vos vidéos, tenez compte des points suivants.
Inclure suffisamment de vidéos
 En règle générale, plus votre ensemble de données contient de vidéos d'entraînement, plus le résultat sera fiable. Le nombre de vidéos recommandé dépend également de la complexité du problème que vous essayez de résoudre. Par exemple, vous aurez besoin de moins de données vidéo pour un problème de classification binaire (prédiction d'une classe sur deux) que pour un problème à étiquettes multiples (prédiction d'une ou de plusieurs classes parmi de nombreuses autres).
En règle générale, plus votre ensemble de données contient de vidéos d'entraînement, plus le résultat sera fiable. Le nombre de vidéos recommandé dépend également de la complexité du problème que vous essayez de résoudre. Par exemple, vous aurez besoin de moins de données vidéo pour un problème de classification binaire (prédiction d'une classe sur deux) que pour un problème à étiquettes multiples (prédiction d'une ou de plusieurs classes parmi de nombreuses autres).
La complexité des éléments que vous essayez de classifier peut également déterminer la quantité de données vidéo dont vous avez besoin. Prenons le cas d'utilisation du football, où il s'agit de créer un modèle pour distinguer les actions de tir. Comparez cela à un modèle distinguant les espèces de colibris. Examinez les nuances et les similitudes de couleur, de taille et de forme : vous auriez besoin de davantage de données d'entraînement pour que le modèle sache comment identifier chaque espèce avec précision.
Utilisez ces règles comme référence pour déterminer la quantité de données vidéo dont vous aurez besoin.
- 200 exemples vidéo par classe si vous avez peu de classes et qu'elles sont distinctes
- Plus de 1 000 exemples vidéo par classe si vous avez plus de 50 classes ou si les classes sont semblables les unes aux autres
La quantité de données vidéo requise peut être supérieure à celle dont vous disposez actuellement. Envisagez d'obtenir davantage de vidéos auprès d'un fournisseur tiers. Par exemple, vous pourriez acquérir ou obtenir davantage de vidéos de football si vous n'en avez pas suffisamment pour entraîner votre modèle d'identificateur d'actions de match.
Répartir équitablement les vidéos entre les classes
Essayez de fournir un nombre semblable d'exemples d'entraînement pour chaque classe. Voici pourquoi : imaginez que les 80 % de votre ensemble de données d'entraînement soient des vidéos de football contenant des tirs au but, mais que seulement 20 % des vidéos décrivent des fautes personnelles ou des penalties. Lorsque les classes sont réparties de manière aussi inégale, le modèle est plus susceptible de prédire qu'une action donnée est un but. C'est comme si vous conceviez un test à choix multiples où 80 % des réponses correctes sont "C" : le modèle avisé comprendra rapidement que la plupart du temps, "C" est sans doute la bonne réponse.

Vous ne pourrez peut-être pas générer un nombre égal de vidéos pour chaque classe. De même, pour certaines classes, il peut être difficile d'obtenir des exemples non biaisés de grande qualité. Vous devez donc essayer de respecter un rapport de 1:10 : si la classe la plus nombreuse compte 10 000 vidéos, alors la plus petite devrait en contenir au moins 1 000.
Capturer les nuances
Vos données vidéo doivent capturer la diversité de votre espace-problème. Plus un modèle traite des exemples diversifiés au cours de son entraînement, plus il peut facilement se généraliser à des exemples nouveaux ou moins courants. Pensez au modèle de classification des actions de football : il vous faudra inclure des vidéos présentant divers angles de caméra, des heures diurnes et nocturnes, ainsi qu'une variété de mouvements de joueurs. L'exposition du modèle à des données diversifiées améliorera sa capacité à distinguer une action d'une autre.
Faire correspondre les données aux résultats souhaités

Recherchez des vidéos d'entraînement visuellement similaires aux vidéos que vous prévoyez d'introduire dans le modèle de prédiction. Par exemple, si toutes vos vidéos d'entraînement sont prises en hiver ou en soirée, les caractéristiques d'éclairage et de couleur de ces environnements affecteront votre modèle. Si vous l'utilisez ensuite pour tester des vidéos prises en été ou en plein jour, vous risquez d'obtenir des prédictions inexactes.
Tenez compte de ces facteurs supplémentaires : *résolution vidéo *images vidéo par seconde *angle de caméra *arrière-plan
Préparer vos données

Une fois que vous avez collecté les vidéos que vous souhaitez inclure dans votre ensemble de données, vous devez vous assurer qu'elles contiennent des cadres de délimitation et des étiquettes afin que le modèle sache ce qu'il doit rechercher.
Pourquoi mes vidéos ont-elles besoin de cadres de délimitation et d'étiquettes ?
Comment un modèle de classification AutoML Video Intelligence apprend-il à identifier des schémas ? C'est ce à quoi servent les cadres de délimitation et les étiquettes pendant l'entraînement. Prenons l'exemple du football : chaque exemple vidéo devra contenir des cadres de délimitation autour des scènes d'action. Ces cadres doivent également porter des étiquettes telles que "but", "faute personnelle" ou "penalty". Sinon, le modèle ne saura pas quoi rechercher. Dessiner des cadres de délimitation et attribuer des étiquettes à vos exemples vidéo peut prendre du temps. Au besoin, envisagez de faire appel à un service d'étiquetage pour impartir ce travail à d'autres personnes.
Entraîner le modèle
Une fois vos données vidéo d'entraînement préparées, vous êtes prêt à créer un modèle de machine learning. Sachez que vous pouvez utiliser le même ensemble de données pour créer différents modèles de machine learning, même s'ils concernent différents types de problèmes.
L'un des avantages de la classification AutoML Video Intelligence est que les paramètres par défaut vous guideront vers un modèle de machine learning fiable. En revanche, vous devrez peut-être les ajuster en fonction de la qualité de vos données et du résultat recherché. Exemple :
- Type de prédiction (niveau de granularité selon lequel vos vidéos sont traitées)
- Fréquence d'images
- Solution
Évaluer le modèle
 Après avoir entraîné le modèle, vous recevez un résumé de ses performances. Les métriques d'évaluation du modèle sont basées sur ses performances par rapport à une tranche de votre ensemble de données (ensemble de données de validation). Il existe plusieurs métriques et concepts clés à prendre en compte pour déterminer si votre modèle est prêt à traiter des données réelles.
Après avoir entraîné le modèle, vous recevez un résumé de ses performances. Les métriques d'évaluation du modèle sont basées sur ses performances par rapport à une tranche de votre ensemble de données (ensemble de données de validation). Il existe plusieurs métriques et concepts clés à prendre en compte pour déterminer si votre modèle est prêt à traiter des données réelles.
Seuil de score
Comment un modèle de machine learning sait-il qu'un tir au but est réellement un but ? Un score de confiance est attribué à chaque prédiction. Il s'agit d'une évaluation numérique de la certitude du modèle qu'une séquence vidéo donnée contient une classe. Le seuil de score est le nombre qui détermine le moment où un score donné est converti en décision positive ou négative, c'est-à-dire la valeur à laquelle votre modèle indique "oui, ce nombre de confiance est suffisamment élevé pour conclure que cette séquence vidéo contient un but".

Si le seuil de score est bas, votre modèle risque de ne pas étiqueter correctement les séquences vidéo. C'est pourquoi ce seuil devrait être déterminé en fonction d'un cas d'utilisation donné. Par exemple, imaginez un cas d'utilisation médicale tel que la détection du cancer, où les conséquences d'un mauvais étiquetage sont plus lourdes que celles de l'étiquetage incorrect de vidéos sportives. La détection du cancer justifie donc un seuil de score plus élevé.
Résultats de prédiction
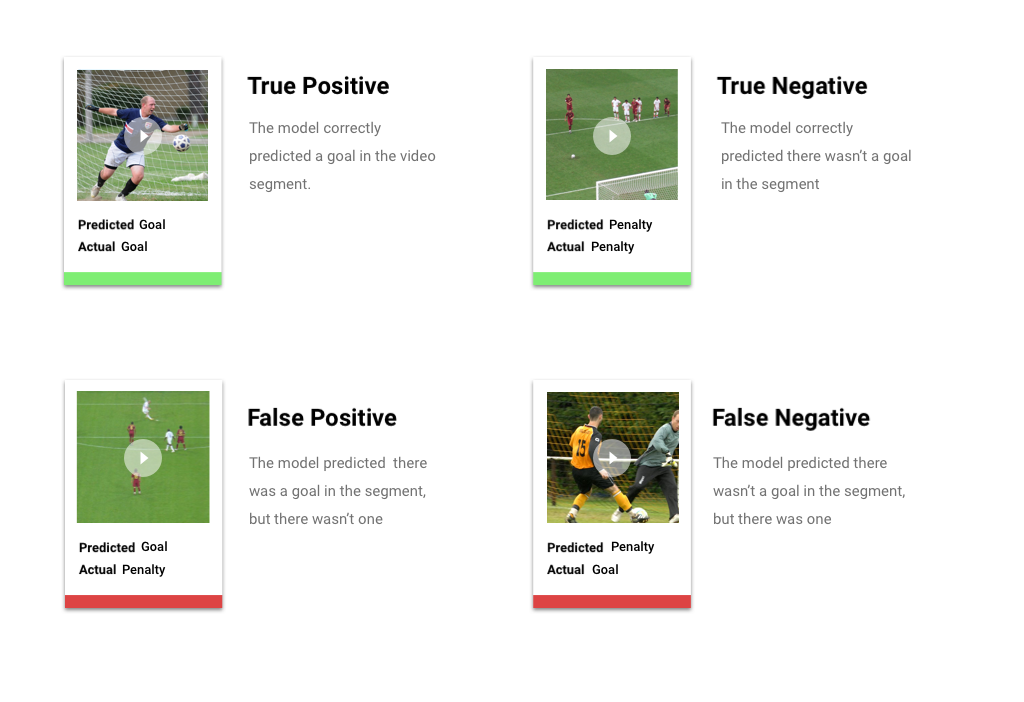
Après l'application du seuil de score, les prédictions effectuées par votre modèle entrent dans l'une des quatre catégories ci-dessous. Pour comprendre ces catégories, imaginons que vous ayez construit un modèle permettant de détecter si une séquence donnée contient un but au football (ou non). Dans cet exemple, le but correspond à la classe positive (ce que le modèle tente de prédire).
- Vrai positif : le modèle prédit correctement la classe positive. Le modèle a correctement prédit la présence d'un but dans la séquence vidéo.
- Faux positif : le modèle prédit incorrectement la classe positive. Le modèle a prédit la présence d'un but dans la séquence, mais en réalité il n'y en avait pas.
- Vrai négatif : le modèle prédit correctement la classe négative. Le modèle a prédit correctement l'absence de but dans la séquence.
- Faux négatif : le modèle prédit incorrectement une classe négative. Le modèle a prédit l'absence de but dans la séquence, alors qu'en réalité il y en avait un.
Précision et rappel
Les métriques de précision et de rappel permettent d'évaluer la capacité de votre modèle à capturer des informations et à en laisser certaines de côté. En savoir plus sur la précision et le rappel
- La précision est la fraction des prédictions positives qui étaient correctes. Parmi toutes les prédictions étiquetées "but", quelle fraction contient réellement un but ?
- Le rappel est la fraction de toutes les prédictions positives qui ont été réellement identifiées. Parmi tous les buts de football qui auraient pu être identifiés, quelle fraction de ces buts l'ont été ?
Selon votre cas d'utilisation, vous devrez peut-être optimiser la précision ou le rappel. Voici quelques exemples de cas d'utilisation.
Cas d'utilisation : informations personnelles contenues dans des vidéos
Imaginez que vous développiez un logiciel qui détecte et floute automatiquement les informations sensibles dans une vidéo. Les faux résultats peuvent inclure les conséquences suivantes :
- Un faux positif identifie un élément qui n'a pas besoin d'être censuré, mais qui l'est quand même. Cela pourrait être gênant mais pas préjudiciable.

- Un faux négatif ne permet pas d'identifier les informations à censurer, telles qu'un numéro de carte de crédit. Cela aurait pour effet de divulguer des informations personnelles, ce qui constitue le pire des cas.
Dans ce cas d'utilisation, il est essentiel d'optimiser le rappel pour s'assurer que le modèle détecte tous les éléments pertinents. Un modèle optimisé pour le rappel est plus susceptible d'étiqueter des exemples marginalement pertinents, mais également plus susceptible d'étiqueter des exemples incorrects (floutant plus d'informations que nécessaire).
Cas d'utilisation : recherche au sein d'une vidéothèque
Supposons que vous souhaitiez créer un logiciel permettant aux utilisateurs de lancer une recherche dans une vidéothèque à partir d'un mot clé. Considérons les résultats incorrects :
- Un faux positif renvoie une vidéo non pertinente. Étant donné que votre système tente de renvoyer seulement des vidéos pertinentes, il ne fait pas vraiment ce pour quoi il a été conçu.

- Un faux négatif ne renvoie pas une vidéo pourtant pertinente. Étant donné que de nombreux mots clés renvoient des centaines de vidéos, ce problème n'est pas aussi grave que de renvoyer une vidéo non pertinente.

Dans cet exemple, il faudra optimiser la précision pour que votre modèle renvoie des résultats à la fois très pertinents et corrects. Un modèle de haute précision ne traitera probablement que les exemples les plus pertinents, mais peut en laisser certains de côté. En savoir plus sur les métriques d'évaluation de modèle
Déployer le modèle
 Lorsque vous êtes satisfait des performances de votre modèle, il est temps de l'utiliser dans la réalité.
La classification AutoML Video Intelligence s'appuie sur la prédiction par lot, ce qui vous permet d'importer un fichier CSV avec des chemins de fichiers vers des vidéos hébergées sur Cloud Storage. Votre modèle traitera chaque vidéo et générera les prédictions dans un autre fichier CSV. La prédiction par lot est asynchrone, ce qui signifie que le modèle traitera toutes les requêtes de prédiction avant de générer les résultats.
Lorsque vous êtes satisfait des performances de votre modèle, il est temps de l'utiliser dans la réalité.
La classification AutoML Video Intelligence s'appuie sur la prédiction par lot, ce qui vous permet d'importer un fichier CSV avec des chemins de fichiers vers des vidéos hébergées sur Cloud Storage. Votre modèle traitera chaque vidéo et générera les prédictions dans un autre fichier CSV. La prédiction par lot est asynchrone, ce qui signifie que le modèle traitera toutes les requêtes de prédiction avant de générer les résultats.