はじめに
想像してみてください。あなたはサッカーチームのコーチをしています。数々の試合を収録した大規模な動画ライブラリがあり、これを活用してチームの強みと弱みを研究したいと思っています。さまざまな試合の動画からゴール、ファウル、ペナルティ キックなどのアクションを集めて 1 本の動画に編集すれば、非常に役立つはずです。けれども、レビュー対象の動画は何百時間にもおよび、追跡するアクションも数多くあります。動画を 1 つずつ観て、各アクションを明確にするために手作業でセグメントにマークを付ける作業は面倒で、時間もかかります。 さらに、この作業は毎シーズン行わなければなりません。 それよりも、動画に特定のアクションが表れるたびに自動的に識別してフラグを立てるよう、コンピュータに学習させるほうが楽だと思いませんか。
機械学習(ML)がこの問題に適したツールである理由
 従来型のプログラミングでは、コンピュータに従わせる詳細な手順をプログラマーが指定しなければなりません。でも、サッカーの試合で特定のアクションを識別する場合はどうでしょうか。色、視点、解像度、照明など、考慮すべき要素は多岐にわたるため、コーディングによってマシンに正しい判断を指示するには、ルールの数が多すぎます。どこから手を付ければよいか想像もつかないほどです。こうした問題を解決するのに打って付けなのが、機械学習システムです。
従来型のプログラミングでは、コンピュータに従わせる詳細な手順をプログラマーが指定しなければなりません。でも、サッカーの試合で特定のアクションを識別する場合はどうでしょうか。色、視点、解像度、照明など、考慮すべき要素は多岐にわたるため、コーディングによってマシンに正しい判断を指示するには、ルールの数が多すぎます。どこから手を付ければよいか想像もつかないほどです。こうした問題を解決するのに打って付けなのが、機械学習システムです。
このガイドでは、AutoML Video Intelligence Classification でこの問題を解決する仕組みとそのワークフローを説明します。また、AutoML Video Intelligence で解決することを目的とする他の種類の問題についても説明します。
AutoML Video Intelligence Classification の仕組み
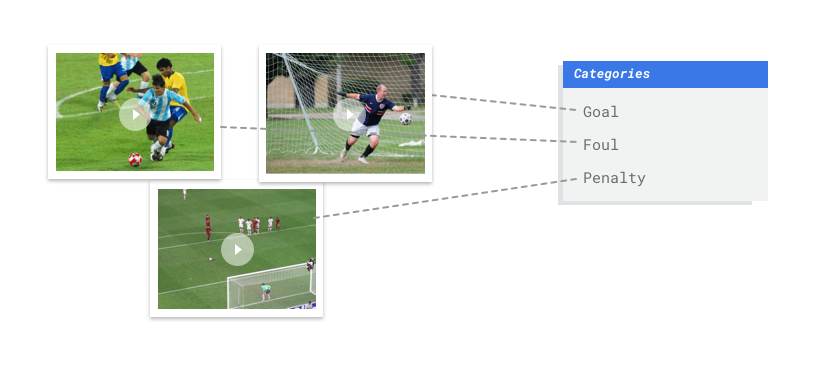
 AutoML Video Intelligence Classification は教師あり学習タスクです。これは、あらかじめラベルが付けられたサンプル動画を使用して、機械学習モデルをトレーニング、テスト、検証することを意味します。トレーニング済みのモデルに新しい動画を入力すると、モデルからラベル付きの動画セグメントが出力されます。ラベルとは、モデルによって予測された「解答」のことです。たとえば、サッカーの試合の分析用のトレーニング済みモデルに対して新しい動画を提供すると、アクション ショットを説明する「goal」、「personal foul」などのラベルが付いた動画セグメントが出力されるといった具合です。
AutoML Video Intelligence Classification は教師あり学習タスクです。これは、あらかじめラベルが付けられたサンプル動画を使用して、機械学習モデルをトレーニング、テスト、検証することを意味します。トレーニング済みのモデルに新しい動画を入力すると、モデルからラベル付きの動画セグメントが出力されます。ラベルとは、モデルによって予測された「解答」のことです。たとえば、サッカーの試合の分析用のトレーニング済みモデルに対して新しい動画を提供すると、アクション ショットを説明する「goal」、「personal foul」などのラベルが付いた動画セグメントが出力されるといった具合です。
AutoML Video Intelligence Classification のワークフロー
AutoML Video Intelligence Classification は、次の標準的な機械学習ワークフローに従います。
- データの収集: 達成したい結果に向けて、モデルのトレーニング用データとテスト用データを選定します。
- データの準備: データを適切にフォーマットし、ラベルを付けます。
- トレーニング: パラメータを設定してモデルを構築します。
- 評価: モデルの指標を確認します。
- デプロイと予測: モデルを利用できるようにします。
ただし、実際にデータを収集する前に、解決しようとしている問題について検討し、データの要件を把握しておく必要があります。
ユースケースの検討

まずは問題に目を向けて、達成する必要のある結果を考えてください。予測する必要があるクラスはいくつありますか。クラスとは、モデルに識別方法を学習させる対象であり、モデルの出力にラベルとして表されます(たとえば、ボールを検出するモデルには、「ball」と「no ball」という 2 つのクラスが必要です)。
ユーザーが目的とする結果に基づいて、AutoML Video Intelligence Classification はユースケースを解決するために必要なモデルを作成します。
バイナリ分類モデルは、2 択の結果(2 つのクラスのうちのいずれか)を予測します。たとえば、サッカーの試合におけるゴールシーンの判別(「これはゴールかどうか」)など、「はい」か「いいえ」で答えられる質問には、このモデルを使用します。通常、バイナリ分類問題に必要となる動画データの量は、他の問題よりも少なくなります。
マルチクラス分類モデルは、複数の異なるクラスから、そのうちの 1 つを予測します。動画セグメントを分類するには、このモデルを使用します。たとえば、オリンピックの動画ライブラリのセグメントを分類して、どのスポーツが映されているかを特定するとします。この場合の出力は、「swimming」、「gymnastics」といった単一のラベルが割り当てられた動画セグメントになります。
マルチラベル分類モデルは、多数の考えられるクラスから 1 つ以上のクラスを予測します。単一の動画セグメントに複数のクラスでラベルを付けるには、このモデルを使用します。 通常、多数のクラスを区分けするのは困難な作業なので、この種類の問題にはより多くのトレーニング データが必要になります。
上述のサッカーの例では、複数のクラス(ゴール、パーソナル ファウルなどのアクション)が同時に発生する可能性があります。つまり、単一の動画セグメントに複数のラベルが必要になるため、この例にはマルチラベル分類モードが適しています。
公平性に関する注記
公平性は、Google の責任ある AI への取り組みの 1 つとなっています。公平性の目的とは、過去に差別や過小評価の対象になった人種、収入、性的志向、宗教、性別などの特性を理解し、そのような特性がアルゴリズム システムやアルゴリズムによる意思決定に現れる場合に、不公平で偏見的な扱いを防止することです。このガイドには、より公平な機械学習モデルの作成方法について詳しく説明する、「公平性の認識」という注記を記載しています。詳細
データの収集
 ユースケースを確立したら、必要なモデルを作成するために使用する動画データを収集します。トレーニング用に収集するデータから、解決できる問題の種類がわかります。使用できる動画は何本あるか、それらの動画には、モデルに予測させるクラスのサンプルが十分に含まれているかなど、検討を重ねます。また、動画データを収集するときは、次の点に注意してください。
ユースケースを確立したら、必要なモデルを作成するために使用する動画データを収集します。トレーニング用に収集するデータから、解決できる問題の種類がわかります。使用できる動画は何本あるか、それらの動画には、モデルに予測させるクラスのサンプルが十分に含まれているかなど、検討を重ねます。また、動画データを収集するときは、次の点に注意してください。
十分な動画を含める
 一般に、データセットに含まれるトレーニング用の動画が多いほど、正確な結果を得られます。どれくらいの数の動画を収集すればよいかは、解決しようとしている問題の複雑さによっても増減します。たとえば、バイナリ分類問題(2 つのクラスのうちのいずれかを予測)に必要な動画データの量は、マルチラベル分類問題(多数のクラスから 1 つ以上のクラスを予測)の場合よりも少なくなります。
一般に、データセットに含まれるトレーニング用の動画が多いほど、正確な結果を得られます。どれくらいの数の動画を収集すればよいかは、解決しようとしている問題の複雑さによっても増減します。たとえば、バイナリ分類問題(2 つのクラスのうちのいずれかを予測)に必要な動画データの量は、マルチラベル分類問題(多数のクラスから 1 つ以上のクラスを予測)の場合よりも少なくなります。
必要な動画データの量は、分類しようとしている対象の複雑さによっても左右されます。サッカーのユースケースでアクション ショットを区別するモデルを構築する場合を考えてみましょう。このモデルを、ハチドリの種を区別するモデルと比較してください。 色、大きさ、形の微妙な違いや類似点を考えると、それぞれの種を正確に識別する方法をモデルに学習させるためには、より多くのトレーニング データが必要になります。
必要最小限の動画データの量を見積もる際には、次のルールを指針とします。
- クラスの数が少なく、それぞれ特徴的な場合は、クラスあたり 200 本の動画サンプル
- 50 個を超えるクラスがある場合、またはクラスが互いに類似している場合は、クラスあたり 1,000 本以上の動画サンプル
必要な動画データの量が、手元にある動画より多い場合もあります。その場合は、サードパーティ プロバイダから追加の動画を入手することを検討してください。たとえば、試合のアクション識別モデルに必要な動画が不足しているとしたら、サッカーの動画を購入または入手できます。
クラス間で均等に動画を配分する
各クラスに同等の数のトレーニング サンプルを用意するようにしてください。たとえば、トレーニング データセットに含まれるサッカー動画のうちの 80% がゴールショットを映したもので、パーソナル ファウルやペナルティ キックの動画は 20% しかない場合を考えてみてください。このような不均等なクラスの配分だと、モデルが特定のアクションをゴールであると予測する確率が高くなります。これは、正解の 80% が「C」である多肢選択式テストを作成するのと似ています。「機転が利く」モデルならば、ほとんどの回答が「C」であることを突き止めてしまいます。

各クラスに同等の数の動画を調達できないことがあります。クラスによっては、高品質でバイアスのないサンプルを用意するのが難しい場合もあります。そのような場合は、1:10 の比率に従うようにしてください。つまり、サンプル数が最も多いクラスに 10,000 本の動画があるとしたら、サンプル数が最も少ないクラスには、少なくても 1,000 本の動画を用意します。
バリエーションを考慮する
動画データには、問題空間に多様性を持たせてください。モデルのトレーニングで使用するサンプルが多様であればあるほど、目新しいサンプルや一般的ではないサンプルにも対応できる汎用化されたモデルが実現されます。たとえば、サッカーのアクション分類モデルでは、サンプルにさまざまなカメラアングル、日中と夜間、選手の多様な動きを含める必要があります。モデルを多様なデータに触れさせることで、モデルがアクションを区別する能力が高まります。
意図する出力にデータを合わせる

予測対象としてモデルに入力する予定の動画と視覚的に似ているトレーニング用動画を見つけます。たとえば、トレーニング用動画のすべてが冬または夜間に撮影されたものである場合、こうした環境での照明と色のパターンがモデルに影響を与えます。このモデルを使用して夏または日中に撮影された動画をテストすると、正確な予測は得られないでしょう。
次の要素も検討してください。 * 動画の解像度 * 1 秒あたりの動画フレーム数 * カメラアングル * 背景
データの準備

データセットに含める動画を集めたら、モデルが何を探せばよいのか把握できるよう、動画に境界ボックスとラベルを含める必要があります。
動画に境界ボックスとラベルが必要な理由
AutoML Video Intelligence Classification モデルはパターンを識別することをどのようにして学習するのでしょうか。トレーニング中にその学習の手段となるのが、境界ボックスとラベルです。サッカーの例では、各サンプル動画にアクション ショットを囲む境界ボックスが含まれていなければなりません。境界ボックスには、該当するアクションに割り当てられた「goal」、「personal foul」、「penalty kick」などのラベルも必要です。 このようにしなければ、モデルは何を探すべきかわかりません。 サンプル動画にボックスを描画してラベルを割り当てる作業には時間がかかる場合があります。必要に応じて、ラベル付けサービスを利用してその作業を外部に委託することを検討してください。
モデルのトレーニング
トレーニング用の動画データを準備したら、機械学習モデルの作成に取り掛かることができます。モデルで解決する問題のタイプが異なるとしても、同じデータセットを使用してさまざまな機械学習モデルを作成できます。
AutoML Video Intelligence Classification の利点の 1 つは、デフォルトのパラメータを頼りに信頼性の高い機械学習モデルを作成できることです。ただし、データの品質と求めている結果に応じてパラメータを調整しなければならない場合もあります。 例:
- 予測タイプ(動画を処理する粒度)
- フレームレート
- 解像度
モデルの評価
 モデルのトレーニングが完了すると、モデルのパフォーマンスの概要が表示されます。モデルの評価指標は、データセット(検証用データセット)のスライスに対するモデルのパフォーマンスに基づきます。モデルが実際のデータで使用できる状態になっているかどうかを判断する際には、検討すべき主な指標とコンセプトがいくつかあります。
モデルのトレーニングが完了すると、モデルのパフォーマンスの概要が表示されます。モデルの評価指標は、データセット(検証用データセット)のスライスに対するモデルのパフォーマンスに基づきます。モデルが実際のデータで使用できる状態になっているかどうかを判断する際には、検討すべき主な指標とコンセプトがいくつかあります。
スコアの基準値
機械学習モデルは、特定の動画の種類がゴールであることをどのようにして判断しているのでしょうか。各予測には、信頼スコアが割り当てられます。信頼スコアは、モデルの確実性を表す数値評価で、所定の動画セグメントに指定したクラスが含まれている確度を示します。スコアしきい値は、所定のスコアが「はい / いいえ」という肯否に結び付けられるポイント(数値)です。つまり、「信頼スコアの数値がこれだけ高ければ、この動画セグメントはゴールシーンである」とモデルで結論付けることができます。

スコアしきい値が低いと、モデルが動画セグメントに誤ったラベルを付けるリスクがあります。このため、スコアしきい値は特定のユースケースに基づいて設定しなければなりません。医療の癌検出においてラベルを貼り違えるのと、スポーツ動画でのミスでは事の重大性は大きく異なります。癌検出などのミスが許されない用途では、スコアしきい値を高く設定してください。
予測結果
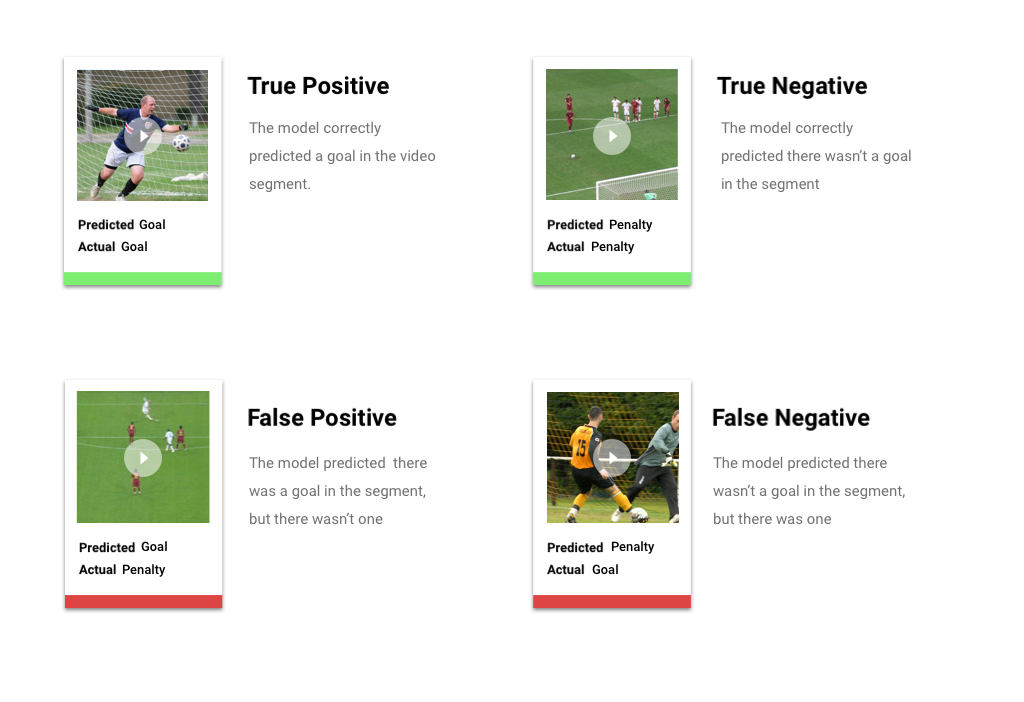
スコアしきい値を適用した後のモデルによる予測は、4 つのカテゴリのうちの 1 つに分類されます。これらのカテゴリを理解するために、特定のセグメントがサッカーのゴールシーンであるかどうかを検出するモデルについて考えてみましょう。 この例では、ゴールは陽性のクラス(モデルが予測しようとしているクラス)です。
- 真陽性: モデルは陽性のクラスを正しく予測している。モデルは動画セグメントがゴールシーンであると正しく予測しました。
- 偽陽性: モデルは陽性のクラスを誤って予測している。モデルはセグメントがゴールシーンであると予測しましたが、実際にはゴールシーンではありませんでした。
- 真陰性: モデルは陰性のクラスを正しく予測している。モデルはセグメントがゴールシーンでないと正しく予測しました。
- 偽陰性: モデルは陰性のクラスを誤って予測している。モデルはセグメントがゴールシーンでないと予測しましたが、実際にはゴールシーンでした。
適合率と再現率
適合率と再現率は、モデルがどの程度適切に情報を取得しているか、そしてどれだけの情報を除外しているかを把握するのに役立ちます。適合率と再現率の詳細
- 適合率は、肯定の予測のうち、正しかった予測の割合です。つまり、「ゴール」のラベルが付けられたすべての予測のうち、実際にゴールシーンが含まれていた予測の割合を示します。
- 再現率は、すべての肯定の予測のうち、実際に識別された予測の割合です。つまり、識別できるはずのゴールシーンのうち、実際に識別された割合を示します。
ユースケースに応じて、適合率または再現率の最適化が必要になる場合があります。以下のようなユースケースが考えられます。
ユースケース: 動画に含まれる個人情報
たとえば、動画に含まれる機密情報を自動的に検出し、その情報をぼかすソフトウェアを作成しているとします。誤った結果には、次の影響が伴います。
- この場合の偽陽性は、ぼかす必要がない情報が識別され、ぼかされてしまうことです。目障りですが、弊害はありません。

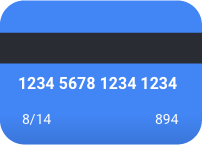
- この場合の偽陰性は、クレジット カード番号のような、ぼかさなければならない情報の識別に失敗することです。これは個人情報の漏洩につながるため、最悪のシナリオです。
このユースケースでは、モデルが関連するケースをすべて検出できるよう、再現率を高くする必要があります。再現率の高いモデルでは、関連性の低いサンプルだけでなく、誤ったサンプルにもラベルが付けられる可能性(ぼかす必要がない情報もぼかされる可能性)が高くなります。
ユースケース: ストック動画の検索
ユーザーがキーワードで動画ライブラリを検索できるソフトウェアを作成するとします。この場合の誤った結果を考えてみましょう。
- この場合の偽陽性は、関連性のない動画が返されることです。このシステムでは関連する動画だけを結果として返すことを目的としているため、ソフトウェアはその目的を果たしていないことになります。

- この場合の偽陰性は、関連する動画が返されないことです。多くのキーワードは何百本もの動画に関連するため、関連性のない動画が返されるほど問題ではありません。

この例では、モデルが関連性のある正しい結果を出すよう、適合率を高くする必要があります。適合率の高いモデルでは、最も関連性の高いサンプルにのみラベルが付けられる可能性が高くなりますが、一部の適切なサンプルも除外されることがあります。モデルの評価指標の詳細
モデルのデプロイ
 モデルのパフォーマンスが満足のいくものになったら、モデルの使用を開始します。
AutoML Video Intelligence Classification が使用するバッチ予測では、Cloud Storage でホストされている動画のパスを指定した CSV ファイルをアップロードできます。モデルは各動画を処理し、別の CSV ファイルに予測を出力します。バッチ予測は非同期オペレーションです。つまり、モデルはすべての予測リクエストを処理してから、結果を出力します。
モデルのパフォーマンスが満足のいくものになったら、モデルの使用を開始します。
AutoML Video Intelligence Classification が使用するバッチ予測では、Cloud Storage でホストされている動画のパスを指定した CSV ファイルをアップロードできます。モデルは各動画を処理し、別の CSV ファイルに予測を出力します。バッチ予測は非同期オペレーションです。つまり、モデルはすべての予測リクエストを処理してから、結果を出力します。