LangChain en Vertex AI (versión preliminar) te permite usar la biblioteca de código abierto LangChain para compilar aplicaciones basadas en IA generativa personalizadas y usar Vertex AI para modelos, herramientas e implementación. Con LangChain en la IA de Vertex (vista previa), puedes hacer lo siguiente:
- Seleccionar el modelo de lenguaje grande (LLM) con el que deseas trabajar.
- Definir herramientas para acceder a APIs externas.
- Estructurar la interfaz entre el usuario y los componentes del sistema en un framework de organización.
- Implementar el framework en un entorno de ejecución administrado.
Ventajas
- Personalizable: Mediante las interfaces estandarizadas de LangChain, se puede adoptar LangChain en Vertex AI para compilar diferentes tipos de aplicaciones. Puedes personalizar la lógica de tu aplicación y, también, incorporar cualquier framework, lo que proporciona un alto grado de flexibilidad.
- Simplifica la implementación: LangChain en Vertex AI usa las mismas APIs que LangChain para interactuar con LLM y compilar aplicaciones. LangChain en Vertex AI simplifica y acelera la implementación con LLM de Vertex AI, ya que el entorno de ejecución de Reasoning Engine admite la implementación de un solo clic para generar una API compatible basada en tu biblioteca.
- Integración en los ecosistemas de Vertex AI: Reasoning Engine para LangChain en Vertex AI usa la infraestructura de Vertex AI y los contenedores compilados previamente para ayudarte a implementar tu aplicación de LLM. Puedes usar la API de Vertex AI para integrar en modelos de Gemini, llamadas a funciones y extensiones.
- Seguro, privado y escalable: Puedes usar una sola llamada al SDK en lugar de administrar el proceso de desarrollo por tu cuenta. El entorno de ejecución administrado de Reasoning Engine te libera de tareas como el desarrollo del servidor de aplicaciones, la creación de contenedores y la configuración de autenticación, IAM y escalamiento. Vertex AI controla el ajuste de escala automático, la expansión regional y las vulnerabilidades de los contenedores.
Casos de uso
Para obtener más información sobre LangChain en Vertex AI con ejemplos de extremo a extremo, consulta los siguientes recursos:
Componentes del sistema
La compilación y la implementación de una aplicación de IA generativa personalizada con OSS LangChain y la IA de Vertex consta de cuatro componentes:
| Componente | Descripción |
|---|---|
| LLM |
Cuando envías una consulta a tu aplicación personalizada, el LLM procesa la consulta y proporciona una respuesta. Puedes elegir definir un conjunto de herramientas que se comunique con APIs externas y proporcionarlas al modelo. Mientras se procesa una consulta, el modelo delega ciertas tareas a las herramientas. Esto implica una o más llamadas de modelo a modelos base o ajustados. Para obtener más información, consulta Versiones de modelo y ciclo de vida. |
| Herramienta |
Puedes elegir definir un conjunto de herramientas que se comunique con APIs externas (por ejemplo, una base de datos) y proporcionarlas al modelo. Mientras se procesa una consulta, el modelo puede delegar ciertas tareas a las herramientas. La implementación a través del entorno de ejecución administrado de IA de Vertex está optimizada para usar herramientas basadas en las llamadas a funciones de Gemini, pero admite la herramienta LangChain y las llamadas a funciones. Para obtener más información sobre las llamadas a funciones de Gemini, consulta Llamadas a funciones. |
| Framework de organización |
LangChain en Vertex AI te permite usar el framework de organización de LangChain en Vertex AI. Usa LangChain para decidir qué tan determinística debería ser tu aplicación. Si ya usas LangChain, puedes usar tu código de LangChain existente para implementar tu aplicación en la IA de Vertex. De lo contrario, puedes crear tu propio código de la aplicación y estructurarlo en un framework de organización que aproveche las plantillas de LangChain de IA de Vertex. Para obtener más información, consulta Desarrolla una aplicación. |
| Entorno de ejecución administrado | LangChain en la IA de Vertex te permite implementar tu aplicación en un entorno de ejecución administrado de Reasoning Engine. Este entorno de ejecución es un servicio de IA de Vertex que tiene todos los beneficios de la integración a IA de Vertex: seguridad, privacidad, observabilidad y escalabilidad. Puedes producir y escalar tu aplicación con una llamada a la API, que te permite convertir rápidamente los prototipos probados de forma local en implementaciones listas para la empresa. Para obtener más información, consulta Implementa una aplicación. |
Existen muchas formas diferentes de prototipar y compilar aplicaciones personalizadas de IA generativa que usan capacidades de agente mediante herramientas de capas, funciones personalizadas y modelos, como Gemini. Cuando llegue el momento de mover la aplicación a la producción, deberás considerar cómo implementar y administrar el agente y sus componentes subyacentes.
Con los componentes de LangChain en Vertex AI, el objetivo es ayudarte a enfocarte y personalizar los aspectos de las capacidades del agente que más te interesan, como las funciones personalizadas, el comportamiento del agente y los parámetros del modelo, mientras Google se encarga de la implementación, el escalamiento del empaquetado y las versiones. Si trabajas en un nivel inferior de la pila, es posible que debas administrar más de lo que deseas. Si trabajas en un nivel superior de la pila, es posible que no tengas tanto control para los desarrolladores como para.
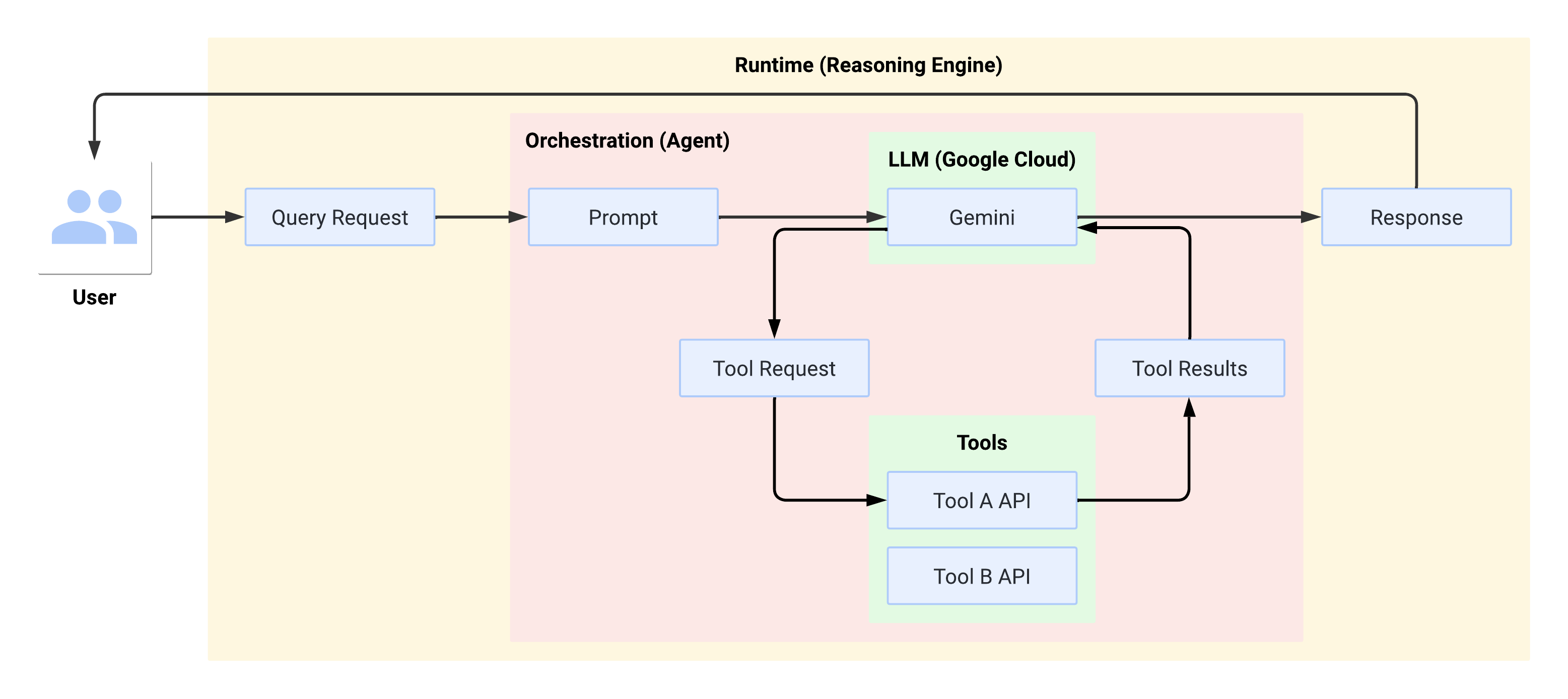
Flujo del sistema en el entorno de ejecución
Cuando el usuario realiza una consulta, el agente definido la formatea en un mensaje para el LLM. El LLM procesa el mensaje y determina si desea usar alguna de las herramientas.
Si el LLM elige usar una herramienta, genera un FunctionCall con el nombre y los parámetros con los que se debe llamar a la herramienta. El agente invoca la herramienta con el FunctionCall y proporciona los resultados de la herramienta al LLM.
Si el LLM elige no usar ninguna herramienta, genera contenido que el agente retransmite al usuario.
En el siguiente diagrama, se ilustra el flujo del sistema en el entorno de ejecución:
Crea e implementa una aplicación de IA generativa
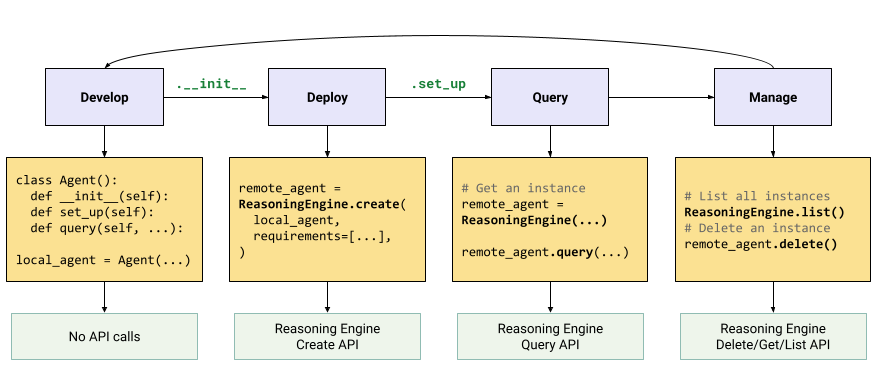
El flujo de trabajo para compilar aplicaciones de IA generativa es el siguiente:
| Pasos | Descripción |
|---|---|
| 1. Configura el entorno | Configura tu proyecto de Google e instala la versión más reciente del SDK de Vertex AI para Python. |
| 2. Desarrollar una aplicación | Desarrolla una aplicación LangChain que se pueda implementar en Reasoning Engine. |
| 3. Implemente la aplicación | Implementa la aplicación en Reasoning Engine |
| 4. Use la aplicación | Consulta a Reasoning Engine para obtener una respuesta. |
| 5. Administra la aplicación implementada | Administra y borra las aplicaciones que implementaste en Reasoning Engine. |
| 6. Personaliza una plantilla de aplicación (opcional) | Personaliza una plantilla para aplicaciones nuevas. |
Los pasos se ilustran en el siguiente diagrama: