LangChain su Vertex AI (anteprima) consente di utilizzare la libreria open source LangChain per creare applicazioni di AI generativa personalizzate e utilizzare Vertex AI per modelli, strumenti e deployment. Con LangChain su Vertex AI (anteprima), puoi svolgere le seguenti operazioni:
- Seleziona il modello linguistico di grandi dimensioni (LLM) con cui vuoi lavorare.
- Definisci gli strumenti per accedere alle API esterne.
- Struttura l'interfaccia tra l'utente e i componenti di sistema in un framework di orchestrazione.
- Esegui il deployment del framework in un runtime gestito.
Vantaggi
- Personalizzabile: utilizzando le interfacce standardizzate di LangChain, LangChain su Vertex AI può essere adottato per creare diversi tipi di applicazioni. Puoi personalizzare la logica della tua applicazione e incorporare qualsiasi framework, in modo da garantire un elevato grado di flessibilità.
- Semplifica il deployment: LangChain su Vertex AI utilizza le stesse API di LangChain per interagire con gli LLM e creare applicazioni. LangChain su Vertex AI semplifica e velocizza il deployment con gli LLM di Vertex AI poiché il runtime del motore di ragionamento supporta il deployment con un solo clic per generare un'API conforme in base alla tua libreria.
- Integrazione con gli ecosistemi Vertex AI: Reasoning Engine per LangChain su Vertex AI utilizza l'infrastruttura e i container predefiniti di Vertex AI per aiutarti a eseguire il deployment della tua applicazione LLM. Puoi utilizzare l'API Vertex AI per eseguire l'integrazione con i modelli Gemini, le chiamate di funzione e le estensioni.
- Sicuro, privato e scalabile: puoi utilizzare una singola chiamata SDK anziché gestire autonomamente il processo di sviluppo. Il runtime gestito di Reasoning Engine ti libera da attività come lo sviluppo di server di applicazioni, la creazione di container e la configurazione di autenticazione, IAM e scalabilità. Vertex AI gestisce la scalabilità automatica, l'espansione regionale e le vulnerabilità dei container.
Casi d'uso
Per scoprire di più su LangChain su Vertex AI con esempi end-to-end, consulta le seguenti risorse:
Componenti di sistema
La creazione e il deployment di un'applicazione di AI generativa personalizzata utilizzando LangChain open source e Vertex AI sono costituiti da quattro componenti:
| Componente | Descrizione |
|---|---|
| LLM |
Quando invii una query alla tua applicazione personalizzata, l'LLM la elabora e fornisce una risposta. Puoi scegliere di definire un insieme di strumenti che comunicano con API esterne e fornirli al modello. Durante l'elaborazione di una query, il modello delega determinate attività agli strumenti. Ciò implica una o più chiamate ai modelli di base o ottimizzati. Per scoprire di più, consulta la sezione Versioni e ciclo di vita dei modelli. |
| Strumento |
Puoi scegliere di definire un insieme di strumenti che comunicano con API esterne (ad esempio un database) e fornirli al modello. Durante l'elaborazione di una query, il modello può delegare determinate attività agli strumenti. Il deployment tramite il runtime gestito di Vertex AI è ottimizzato per l'utilizzo di strumenti basati su Chiamate di funzioni Gemini, ma supporta le chiamate di funzioni/strumenti LangChain. Per scoprire di più sulle chiamate di funzione di Gemini, consulta Chiamata di funzione. |
| Framework di orchestrazione |
LangChain su Vertex AI ti consente di utilizzare il framework di orchestrazione LangChain in Vertex AI. Utilizza LangChain per decidere quanto deve essere deterministica la tua applicazione. Se utilizzi già LangChain, puoi utilizzare il codice LangChain esistente per eseguire il deployment dell'applicazione su Vertex AI. In caso contrario, puoi creare il tuo codice dell'applicazione e strutturarlo in un framework di orchestrazione che sfrutta i modelli LangChain di Vertex AI. Per scoprire di più, consulta Sviluppare un'applicazione. |
| Runtime gestito | LangChain su Vertex AI ti consente di eseguire il deployment della tua applicazione in un runtime gestito di Reasoning Engine. Questo runtime è un servizio Vertex AI che offre tutti i vantaggi dell'integrazione di Vertex AI: sicurezza, privacy, osservabilità e scalabilità. Puoi eseguire il deployment in produzione e scalare la tua applicazione con una chiamata API, trasformando rapidamente i prototipi testati localmente in implementazioni pronte per le aziende. Per scoprire di più, consulta Eseguire il deployment di un'applicazione. |
Esistono molti modi diversi per realizzare prototipi e creare applicazioni di IA generativa personalizzate che utilizzano funzionalità di agenti sovrapponendo strumenti e funzioni personalizzate a modelli come Gemini. Quando è il momento di spostare la tua applicazione in produzione, devi considerare come eseguire il deployment e gestire l'agente e i relativi componenti sottostanti.
L'obiettivo dei componenti di LangChain su Vertex AI è aiutarti a concentrarti e personalizzare gli aspetti delle funzionalità dell'agente che ti interessano maggiormente, come funzioni personalizzate, comportamento dell'agente e parametri del modello, mentre Google si occupa del deployment, del packaging e delle versioni. Se lavori a un livello inferiore della pila, potresti dover gestire più di quanto vorresti. Se lavori a un livello superiore della pila, potresti non avere il controllo dello sviluppatore che vorresti.
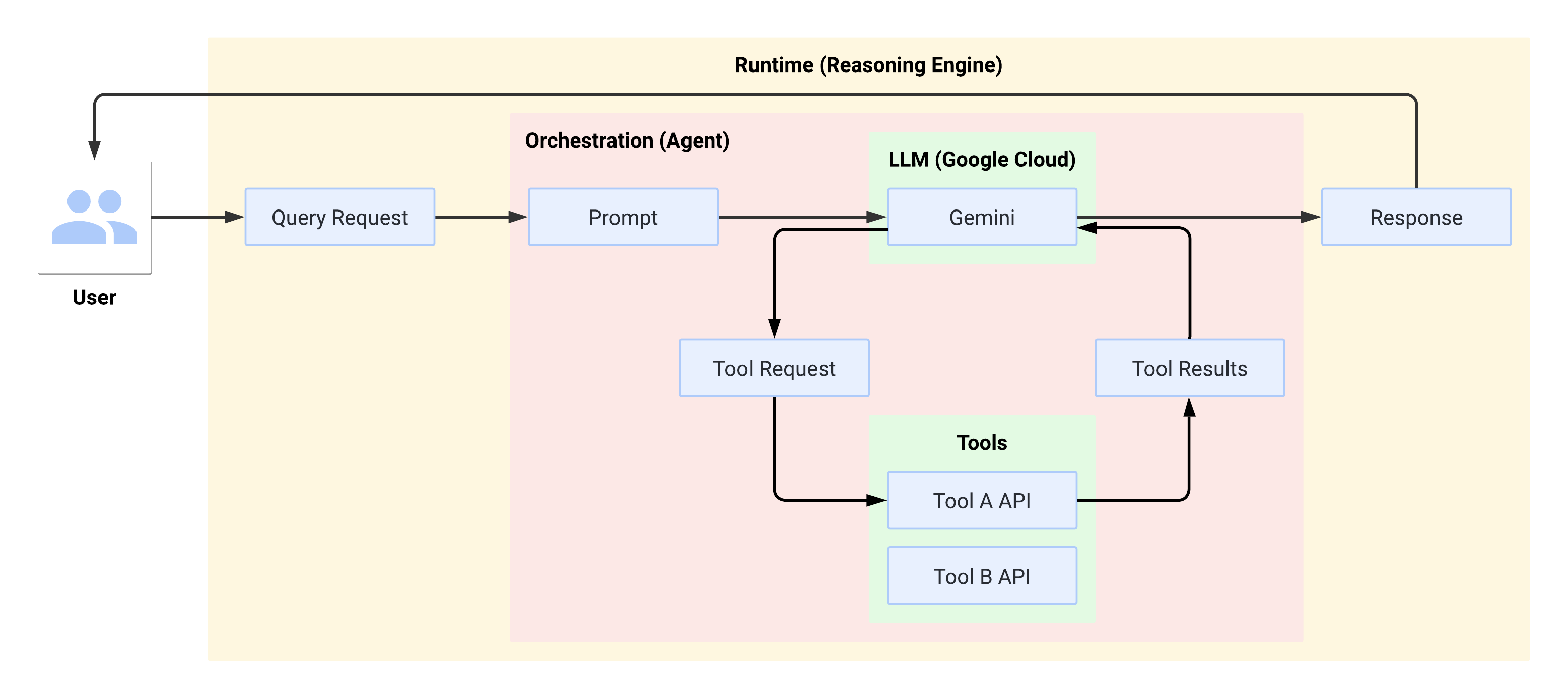
Flusso di sistema in fase di esecuzione
Quando l'utente effettua una query, l'agente definito la formatta in un prompt per il LLM. L'LLM elabora il prompt e determina se vuole utilizzare uno degli strumenti.
Se l'LLM sceglie di utilizzare uno strumento, genera un FunctionCall con il nome
e i parametri con cui deve essere chiamato lo strumento. L'agente richiama lo strumento con FunctionCall e restituisce i risultati dello strumento all'LLM.
Se l'LLM sceglie di non utilizzare alcuno strumento, genera contenuti che vengono ritrasmessi dall'agente all'utente.
Il seguente diagramma illustra il flusso di sistema in fase di esecuzione:
Crea e distribuisci un'applicazione di AI generativa
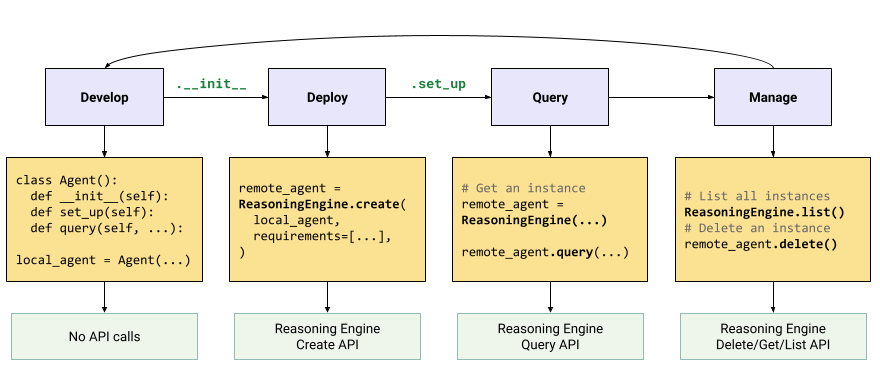
Il flusso di lavoro per creare applicazioni di AI generativa è il seguente:
| Passaggi | Descrizione |
|---|---|
| 1. Configura l'ambiente | Configura il tuo progetto Google e installa la versione più recente dell'SDK Vertex AI per Python. |
| 2. Sviluppare un'applicazione | Sviluppare un'applicazione LangChain che può essere implementata in Reasoning Engine. |
| 3. Esegui il deployment dell'applicazione | Esegui il deployment dell'applicazione su Reasoning Engine. |
| 4. Utilizzare l'applicazione | Chiedi al motore di ragionamento delle query una risposta. |
| 5. Gestire l'applicazione di cui è stato eseguito il deployment | Gestisci ed elimina le applicazioni di cui hai eseguito il deployment in Reasoning Engine. |
| 6. (Facoltativo) Personalizzare un modello di applicazione | Personalizzare un modello per le nuove applicazioni. |
I passaggi sono illustrati nel seguente diagramma:
Prezzi
La struttura dei prezzi si basa sulle ore di vCPU e sulle ore di GiB utilizzate durante l'elaborazione delle richieste, l'avvio e l'arresto dei container. Ciò significa che ti verranno addebitati sia le risorse di calcolo (vCPU) sia quelle di memoria consumate dai tuoi carichi di lavoro.
Ti consigliamo di eliminare le risorse non utilizzate per evitare di incorrere in costi indesiderati.