Nesta página, descrevemos o que é e como funciona o Vertex AI RAG Engine.
| Descrição | Console |
|---|---|
| Para saber como usar o SDK da Vertex AI para executar tarefas do mecanismo de RAG da Vertex AI, consulte o início rápido de RAG para Python. |
Visão geral
O mecanismo de RAG da Vertex AI, um componente da plataforma Vertex AI, facilita a geração aumentada de recuperação (RAG). O mecanismo RAG da Vertex AI também é um framework de dados para desenvolver aplicativos de modelo de linguagem grande (LLM) ampliados por contexto. A ampliação de contexto ocorre quando você aplica um LLM aos seus dados. Isso implementa a geração de recuperação aumentada (RAG, na sigla em inglês).
Um problema comum com os LLMs é que eles não entendem o conhecimento particular, ou seja, os dados da sua organização. Com o mecanismo RAG da Vertex AI, é possível enriquecer o contexto do LLM com mais informações particulares, porque o modelo pode reduzir a alucinação artificial e responder a perguntas com mais precisão.
Ao combinar outras fontes de conhecimento com o conhecimento atual que os LLMs têm, um contexto melhor é fornecido. O contexto aprimorado com a consulta melhora a qualidade da resposta do LLM.
A imagem a seguir ilustra os principais conceitos para entender o mecanismo de RAG da Vertex AI.
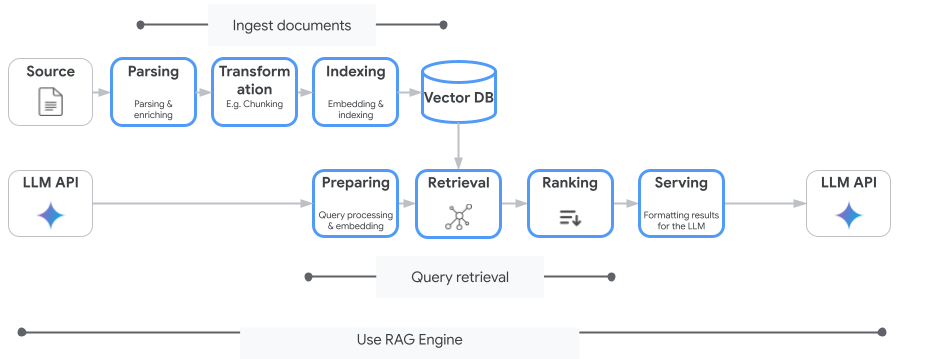
Esses conceitos são listados na ordem do processo de geração aumentada por recuperação (RAG).
Ingestão de dados: receba dados de diferentes fontes. Por exemplo, arquivos locais, Cloud Storage e Google Drive.
Transformação de dados: conversão dos dados na preparação para indexação. Por exemplo, os dados são divididos em partes.
Embedding: representações numéricas de palavras ou partes de texto. Esses números captam o significado semântico e o contexto do texto. Palavras ou textos semelhantes ou relacionados costumam ter embeddings semelhantes, o que significa que estão mais próximos no espaço vetorial de alta dimensão.
Indexação de dados: o mecanismo de RAG da Vertex AI cria um índice chamado corpus. O índice estrutura a base de conhecimento para que seja otimizado para pesquisa. Por exemplo, o índice é como um índice detalhado de um grande livro de referência.
Recuperação: quando um usuário faz uma pergunta ou fornece uma solicitação, o componente de recuperação no mecanismo de RAG da Vertex AI pesquisa na base de conhecimento para encontrar informações relevantes para a consulta.
Geração: as informações recuperadas se tornam o contexto adicionado à consulta do usuário original como um guia para que o modelo de IA generativa gere respostas factuais baseadas e relevantes.
Regiões compatíveis
O mecanismo de RAG da Vertex AI está disponível nas seguintes regiões:
| Região | Local | Descrição | Etapa do lançamento |
|---|---|---|---|
us-central1 |
Iowa | As versões v1 e v1beta1 são compatíveis. |
Lista de permissões |
us-east4 |
Virgínia | As versões v1 e v1beta1 são compatíveis. |
GA |
europe-west3 |
Frankfurt, Alemanha | As versões v1 e v1beta1 são compatíveis. |
GA |
europe-west4 |
Eemshaven, Países Baixos | As versões v1 e v1beta1 são compatíveis. |
GA |
us-central1mudou paraAllowlist. Se quiser testar o mecanismo RAG da Vertex AI, tente outras regiões. Se você planeja integrar seu tráfego de produção aous-central1, entre em contato comvertex-ai-rag-engine-support@google.com.
Excluir o mecanismo RAG da Vertex AI
Os exemplos de código a seguir demonstram como excluir um mecanismo RAG da Vertex AI para o console Google Cloud , Python e REST:
Parâmetros e exemplos de código da API versão 1 (v1).
Parâmetros e exemplos de código da API v1beta1.
Enviar feedback
Para conversar com o suporte do Google, acesse o grupo de suporte do mecanismo de RAG da Vertex AI.
Para enviar um e-mail, use o endereço
vertex-ai-rag-engine-support@google.com.
A seguir
- Para saber como usar o SDK da Vertex AI para executar tarefas do mecanismo de RAG da Vertex AI, consulte Início rápido da RAG para Python.
- Para saber mais sobre o embasamento, consulte Visão geral do embasamento.
- Para saber mais sobre as respostas da RAG, consulte Saída de recuperação e geração do mecanismo de RAG da Vertex AI.
- Para saber mais sobre a arquitetura RAG: