L'API Gemini in Vertex AI ti consente di inviare input multimodali come testo, immagini e video come parte del prompt ai modelli Gemini. Questa pagina fornisce le best practice per la progettazione di prompt multimodali e come risolvere i problemi se i prompt non funzionano come previsto. Per indicazioni generali sulla progettazione dei prompt, consulta le strategie di progettazione dei prompt consigliate o l'elenco seguente di best practice specifiche per la modalità multimodale.
Principi fondamentali della progettazione dei prompt
Utilizzare istruzioni specifiche
I prompt chiari e dettagliati forniscono i risultati migliori. Se hai in mente un output specifico, includi questo requisito nel prompt per aumentare la probabilità di ottenere l'output corretto.
Anche quando un prompt sembra chiaro alla persona che lo ha scritto, potrebbe essere specificato in modo insufficiente. Per personalizzare il comportamento del modello, considera come potrebbe essere interpretato il prompt e assicurati che le istruzioni che fornisci siano specifiche e chiare.
Se hai incluso l'immagine di un tabellone aeroportuale di seguito nel prompt, chiedere al modello di "descrivere questa immagine" potrebbe generare una descrizione generale. Se vuoi che il modello analizzi l'ora e la città dall'immagine, includi la richiesta direttamente nel prompt.
| Prompt | Risposta del modello |
|---|---|

Descrivi questa immagine. |
L'immagine mostra un tabellone degli arrivi e delle partenze di un aeroporto. |
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
Parse the time and city from the airport board shown in this image into a list. |
|
Aggiungi esempi
Il modello può accettare più input da utilizzare come esempi per comprendere l'output che desideri. L'aggiunta di questi esempi può aiutare il modello a identificare i pattern e applicare la relazione tra le immagini e le risposte fornite al nuovo esempio. Questo metodo è chiamato apprendimento"few-shot".
Nell'esempio seguente, l'output iniziale è una frase completa che contiene anche il paese (Brasile). Se l'output preferito è solo la città, non il paese, l'aggiunta di esempi few-shot al prompt può guidare il modello a rispondere in questo formato.
| Prompt | Risposta del modello |
|---|---|

Determina la città insieme al punto di riferimento. |
Il punto di riferimento è la statua del Cristo Redentore a Rio de Janeiro, in Brasile. |
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
Determina la città insieme al punto di riferimento. 
|
città: Roma, punto di riferimento: il Colosseo. |

|
città: Pechino, punto di riferimento: Città Proibita |
|
|
città: Rio de Janeiro, punto di riferimento: statua del Cristo Redentore |
Suddividi le attività complesse in attività più piccole
Per attività complesse, come quelle che richiedono sia la comprensione visiva sia il ragionamento, suddividi l'attività in passaggi più piccoli e semplici o chiedi direttamente al modello di procedere passo dopo passo nel prompt.
| Prompt | Risposta del modello |
|---|---|

Quando finirà la carta igienica? |
Presto ti rimarranno solo 3 rotoli. |
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
|
Anche i problemi di matematica o altri tipi di problemi con enunciato possono essere suddivisi in attività più piccole.
| Prompt | Risposta |
|---|---|

Qual è il quarto termine della sequenza? |
-135 |
La risposta del modello non è corretta. Prova a chiedere al modello di analizzare il problema prima di rispondere al prompt.
| Prompt | Risposta |
|---|---|
|
Analizza prima la formula nell'immagine. In base alla formula, rispondi alla domanda "Qual è il quarto termine della sequenza?". |
Fai clic per espandere il risultato$$b(n) = b(n-1) * (-3)$$ $$b(1) = 15$$
Pertanto, il quarto termine della sequenza è -405. |
Per rendere la risposta ancora più snella, puoi chiedere al modello di analizzare il prompt passo dopo passo.
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
Qual è il quarto termine della sequenza? Pensa passo dopo passo. |
Il primo termine è 15. Il secondo termine è b(1) * (-3) = 15 * (-3) = -45. Il terzo termine è b(2) * (-3) = -45 * (-3) = 135. Il quarto termine è b(3) * (-3) = 135 * (-3) = -405. |
Specifica il formato di output
Quando è richiesto un determinato formato, puoi indicare al modello di utilizzarlo per l'output.
| Prompt | Risposta del modello |
|---|---|
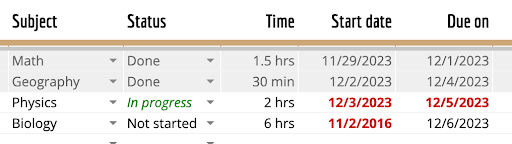
Analizza la tabella in questa immagine nel formato Markdown |
| Subject | Status | Time | Start date | Due on |
|-----------|-------------|---------|------------|------------|
| Math | Done | 1.5 hrs | 11/29/2023 | 12/1/2023 |
| Geography | Done | 30 min | 12/2/2023 | 12/4/2023 |
| Physics | In progress | 2 hrs | 12/3/2023 | 12/5/2023 |
| Biology | Not started | 6 hrs | 11/2/2016 | 12/6/2023 |
|
| Prompt | Risposta del modello |
|---|---|

Fornisci un elenco di tutti i seguenti attributi: ingredienti, tipo di cucina, vegetariano o meno, in formato JSON |
|
Risolvere i problemi relativi a un prompt multimodale
La risoluzione dei problemi di un prompt può comportare il miglioramento del linguaggio del prompt, la direzione del focus del prompt o la regolazione dei parametri. Questi diversi approcci possono portare a risultati migliori, soprattutto dopo aver determinato la causa principale del problema.
Concentrarsi sulla parte pertinente di un'immagine
Per migliorare la risposta, indica quali parti dell'immagine sono più pertinenti al prompt.
| Prompt | Risposta del modello |
|---|---|

Per quanti giorni dureranno questi pannolini per un bambino? |
I pannolini dureranno 198 giorni prima di esaurirsi. |
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
Per quanto tempo mi dureranno questi pannolini prima che finiscano? Utilizza il peso indicato sulla confezione per determinare l'età del bambino e il numero totale di pannolini nella confezione. Dividi il numero totale per il numero di pannolini che il bambino usa al giorno. |
La confezione contiene 198 pannolini. La confezione indica che i pannolini sono adatti a un bambino di peso compreso tra 10 e 17 kg. Il bambino medio in questa fascia di peso ha probabilmente un'età compresa tra 1 e 2 anni. Un bambino di 2 anni in genere usa 6 pannolini al giorno, quindi i pannolini dureranno circa 33 giorni (198/6). |
Personalizzare la risposta del modello in base all'input
Chiedi al modello di descrivere le immagini prima di eseguire l'attività nel prompt.
| Prompt | Risposta del modello |
|---|---|



Cosa hanno in comune queste immagini? |
Tutte e quattro le immagini sono esempi di fotografia paesaggistica. |
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
Per prima cosa, descrivi in dettaglio i contenuti di ogni immagine. Che cosa hanno in comune queste immagini? |
La prima immagine mostra una persona che prepara una valigia. La seconda immagine mostra un corridoio vuoto in un centro commerciale. La terza immagine mostra un rotolo di carta igienica. La quarta immagine mostra un mare scuro e tempestoso. Il punto in comune tra queste immagini è che sono tutte esempi di spazi liminali. Gli spazi liminali sono luoghi o situazioni che si trovano tra due altri luoghi o situazioni. Sono spesso caratterizzati da un senso di incertezza o ambiguità. La prima immagine mostra la persona tra la casa e il viaggio. La seconda immagine mostra il corridoio tra due negozi. La terza immagine è di carta igienica, che può rappresentare un bagno. Il bagno è uno spazio di transizione tra la sfera privata e quella pubblica. È un luogo in cui ci prepariamo a entrare o uscire dal mondo esterno. La quarta immagine mostra il mare in condizioni di calma e tempesta. Gli spazi liminali possono essere sia entusiasmanti che inquietanti. Possono essere un luogo di nuovi inizi o di fine. Possono essere un luogo di riflessione o di azione. |
Puoi chiedere esplicitamente al modello di fare riferimento ai contenuti dell'immagine.
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
Cosa hanno in comune queste immagini? Fai riferimento ai contenuti delle immagini nella risposta. |
Tutte le immagini sono correlate ai viaggi. La prima immagine mostra una persona che prepara una valigia, la seconda mostra un corridoio vuoto in un centro commerciale, la terza mostra una pila di carta igienica e la quarta mostra un mare scuro e tempestoso. Queste immagini sono tutte correlate ai viaggi perché sono tutte cose che le persone hanno bisogno o utilizzano quando viaggiano. La prima immagine mostra una persona che prepara una valigia, un'attività che si svolge quando si parte per un viaggio. La seconda immagine mostra un corridoio vuoto in un centro commerciale, un luogo in cui le persone vanno spesso ad acquistare cose per i loro viaggi. La terza immagine mostra una pila di carta igienica, un oggetto che le persone usano spesso quando viaggiano. La quarta immagine mostra un mare scuro e tempestoso, qualcosa che le persone incontrano spesso quando viaggiano. |
Gli stessi suggerimenti valgono per l'output creativo. Chiedi esplicitamente al modello di includere aspetti dell'immagine, in modo da migliorare l'output.
| Prompt | Risposta del modello |
|---|---|

Puoi scrivermi una poesia su questa immagine? |
Little bunny, so soft and brown,
Hopping through the field, up and down.
Your ears so long, your tail so small,
You're the cutest creature of them all.You nibble on the grass, so green and sweet,
And hop away when you see me.
But I'll always be your friend,
Little bunny, until the very end. |
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
Puoi scrivermi una poesia descrittiva e drammatica su questa immagine e includere la posizione? |
Little bunny on the green,
Ears so long, so keen.
What do you see out there,
In the distance, where you stare?Is it the ocean blue,
Sparkling in the sun's hue?
Or the waves that crash and roar,
A rhythm that you adore?Little bunny, tell me true,
What captures your attention so?
Is it the salty breeze,
Or the seagulls' cries that please?Perhaps it's the vastness of it all,
A world so big and small.
A place where dreams can roam,
And adventures can be sown.Little bunny, I wonder what you dream,
As you sit on the grass, so serene.
Do you yearn to explore the deep,
Or stay on land, where you can leap?Whatever it may be, little bunny,
Keep that spark of wonder burning brightly.
For in your dreams and aspirations,
Lies a world waiting for your creation. |
Determinare il motivo dell'errore del prompt
Un prompt può non riuscire perché il modello non ha compreso l'immagine o perché non ha eseguito i passaggi di ragionamento corretti in seguito. Per distinguere tra questi motivi, chiedi al modello di descrivere cosa c'è nell' immagine.
In questo esempio, se il modello risponde con uno snack che sembra sorprendente se abbinato al tè (come i popcorn), determina innanzitutto se il modello ha riconosciuto che l'immagine contiene tè.
| Prompt | Richiesta di risoluzione dei problemi |
|---|---|

Qual è uno snack che posso preparare in 1 minuto e che si abbini bene a questo? |
Descrivi i contenuti di questa immagine. |
Chiedere al modello di spiegare il suo ragionamento può aiutare a restringere la parte del ragionamento che non ha funzionato, se presente.
| Prompt | Richiesta di risoluzione dei problemi |
|---|---|
|
Qual è uno snack che posso preparare in 1 minuto e che si abbini bene a questo? |
Qual è uno snack che posso preparare in 1 minuto e che si abbini bene a questo? Spiega perché. |
Ottimizzare i parametri di campionamento
In ogni richiesta, invii al modello non solo il prompt multimodale, ma anche un insieme di parametri di campionamento. Il modello può generare risultati diversi per valori di parametro diversi. Sperimenta con i diversi parametri per ottenere i valori migliori per l'attività. I parametri modificati più di frequente sono i seguenti:
Temperatura
La temperatura viene utilizzata per il campionamento durante la generazione della risposta, che si verifica quando vengono applicati i parametri top-P e top-K. La temperatura controlla il grado di casualità nella selezione dei token. Le temperature basse sono ideali per prompt che richiedono risposte più deterministiche e meno aperte o creative, mentre le temperature più alte possono portare a risultati più diversificati o creativi. Una temperatura pari a 0 è deterministica, il che significa che è più probabile che venga selezionata la risposta con la probabilità più alta.
Per la maggior parte dei casi d'uso, inizia con una temperatura di 0,4. Se hai bisogno di risultati più creativi, aumenta la temperatura. Se noti allucinazioni chiare, riduci la temperatura.
Top-P
Top-P cambia il modo in cui il modello seleziona i token per l'output. I token vengono selezionati dal più probabile al meno probabile finché la somma delle loro probabilità non corrisponde al valore di Top-P. Ad esempio, se i token A, B e C hanno una probabilità di 0,6, 0,3 e 0,1 e il valore di top-P è 0,9, il modello seleziona A o B come token successivo utilizzando la temperatura ed esclude C come candidato.
Specifica un valore più basso per risposte meno casuali e un valore più alto per risposte più casuali. Il valore predefinito di top-P è 1.0.
Passaggi successivi
- Prova un tutorial di avvio rapido utilizzando Vertex AI Studio o l'API Vertex AI.
- Per iniziare a utilizzare l'API Gemini in Vertex AI, consulta la guida rapida all'API Gemini in Vertex AI.