Mit der Gemini API in Vertex AI können Sie multimodale Eingaben wie Text, Bilder und Videos als Teil Ihres Prompts an Gemini-Modelle senden. Auf dieser Seite finden Sie Best Practices für das Erstellen multimodaler Prompts und Informationen zur Fehlerbehebung, wenn Ihre Prompts nicht wie erwartet funktionieren. Allgemeine Anleitungen zum Design von Prompts finden Sie unter Empfohlene Strategien für das Prompt-Design. Die folgende Liste enthält multimodale Best Practices.
Grundlagen des Prompt-Designs
Spezifische Anweisungen verwenden
Klare und detaillierte Prompts führen zu den besten Ergebnissen. Wenn Sie eine bestimmte Ausgabe im Hinterkopf haben, sollten Sie diese Anforderung in den Prompt aufnehmen, damit Sie die gewünschte Ausgabe erhalten.
Auch wenn eine Prompt der Person, die sie geschrieben hat, klar erscheint, ist sie möglicherweise nicht ausreichend spezifiziert. Überlegen Sie beim Anpassen des Modellverhaltens, wie Ihre Aufforderung interpretiert werden könnte, und achten Sie darauf, dass die von Ihnen angegebenen Anweisungen spezifisch und klar sind.
Wenn Sie das Bild eines Flughafenboards unten in Ihren Prompt aufgenommen haben und das Modell nur auffordern, „Dieses Bild beschreiben“, könnte es eine allgemeine Beschreibung generieren. Wenn das Modell die Zeit und die Stadt aus dem Bild parsen soll, können Sie diese Anfrage direkt in den Prompt einfügen.
| Prompt | Modellantwort |
|---|---|

Beschreibe dieses Bild. |
Auf dem Bild ist eine Anzeige für Ankunfts- und Abflugfinfos für den Flughafen zu sehen. |
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
Parsen Sie die Uhrzeit und die Stadt vom Flughafenanzeige in dem Bild in eine Liste. |
|
Beispiele hinzufügen
Das Modell kann mehrere Eingaben akzeptieren, die es als Beispiele für das Verständnis der gewünschten Ausgabe verwenden kann. Wenn Sie diese Beispiele hinzufügen, kann das Modell die Muster leichter identifizieren und die Beziehung zwischen den angegebenen Bildern und Antworten auf das neue Beispiel anwenden. Dies wird als Few-Shot-Lernen bezeichnet.
Im folgenden Beispiel ist die ursprüngliche Ausgabe ein vollständiger Satz, der auch das Land (Brasilien) enthält. Wenn die bevorzugte Ausgabe nur die Stadt und nicht das Land ist, können Sie dem Modell mit Few-Shot-Beispielen in Ihrem Prompt zeigen, dass es in diesem Format antworten soll.
| Eingabeaufforderung | Modellantwort |
|---|---|

Stadt und Sehenswürdigkeit ermitteln: |
Die Sehenswürdigkeit ist die Cristo Redentor-Statue in Rio de Janeiro, Brasilien. |
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
Stadt und Sehenswürdigkeit ermitteln: 
|
Stadt: Rom, Sehenswürdigkeit: Kolosseum. |

|
Stadt: Peking, Sehenswürdigkeit: Verbotene Stadt |
|
|
Stadt: Rio de Janeiro, Sehenswürdigkeit: Cristo Redentor-Statue |
Komplexe Aufgaben in kleinere Aufgaben aufteilen
Bei komplexen Aufgaben wie Aufgaben, die sowohl visuelles Verständnis als auch Logik erfordern, sollten Sie die Aufgabe in kleinere, einfachere Schritte aufteilen oder das Modell in der Prompt direkt bitten, Schritt für Schritt vorzugehen.
| Prompt | Modellantwort |
|---|---|

Wann habe ich kein Toilettenpapier mehr? |
Bald sind nur noch 3 Rollen übrig. |
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
|
Mathematische Aufgaben oder andere Arten von Wortproblemen können auch in kleinere Aufgaben unterteilt werden.
| Eingabeaufforderung | Antwort |
|---|---|

Was ist der vierte Begriff in der Sequenz? |
-135 |
Die Antwort des Modells ist falsch. Sie können das Modell beispielsweise bitten, das Problem zu parsen, bevor es den Prompt beantwortet.
| Eingabeaufforderung | Antwort |
|---|---|
|
Parsen Sie zuerst die Formel im Bild. Beantworte dann anhand der Formel: „Was ist der vierte Begriff in der Folge?“. |
Klicken Sie, um das Ergebnis zu maximieren$$b(n) = b(n-1) * (-3)$$ $$b(1) = 15$$
Daher ist der vierte Begriff in der Sequenz -405. |
Wenn Sie die Antwort noch optimieren möchten, können Sie das Modell bitten, die Eingabeaufforderung Schritt für Schritt zu durchdenken.
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
Was ist der vierte Begriff in der Sequenz? Detaillierte Anleitung |
Der erste Begriff ist 15. Der zweite Begriff ist b(1) * (-3) = 15 * (-3) = -45. Der dritte Begriff ist b(2) * (-3) = -45 * (-3) = 135. Der vierte Begriff ist b(3) * (-3) = 135 * (-3) = -405. |
Ausgabeformat angeben
Wenn ein bestimmtes Format erforderlich ist, können Sie das Modell anweisen, dieses Format für die Ausgabe zu verwenden.
| Prompt | Modellantwort |
|---|---|
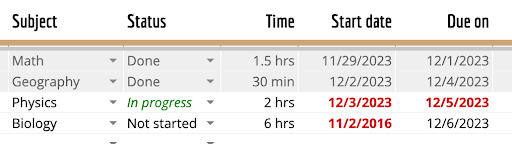
Die Tabelle in diesem Bild in das Markdown-Format parsen |
| Subject | Status | Time | Start date | Due on |
|-----------|-------------|---------|------------|------------|
| Math | Done | 1.5 hrs | 11/29/2023 | 12/1/2023 |
| Geography | Done | 30 min | 12/2/2023 | 12/4/2023 |
| Physics | In progress | 2 hrs | 12/3/2023 | 12/5/2023 |
| Biology | Not started | 6 hrs | 11/2/2016 | 12/6/2023 |
|
| Eingabeaufforderung | Modellantwort |
|---|---|

Geben Sie eine Liste aller folgenden Attribute an: Zutaten, Art der Küche, vegetarisch oder nicht, im JSON-Format |
|
Fehlerbehebung bei einem multimodalen Prompt
Bei der Fehlerbehebung eines Prompts kann es darum gehen, die Sprache Ihres Prompts zu verbessern, den Fokus Ihres Prompts zu lenken oder Parameter anzupassen. Diese unterschiedlichen Ansätze können zu besseren Ergebnissen führen, insbesondere nachdem die Ursache des Problems ermittelt wurde.
Fokus auf den relevanten Teil eines Bildes legen
Um die Antwort zu verbessern, können Sie angeben, welche Teile des Bildes für den Prompt am relevantesten sind.
| Prompt | Modellantwort |
|---|---|

Wie viele Tage halten diese Windeln für ein Baby? |
Die Windel halten 198 Tage, bevor sie aufgebraucht sind. |
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
Wie lange halten diese Windeln? Verwenden Sie das auf dem Feld angezeigte Gewicht, um das Alter des Kindes zu bestimmen. Verwenden Sie dann die Gesamtzahl der Windeln im Feld. Teilen Sie die Gesamtzahl durch die Anzahl der Windeln, die das Kind pro Tag benötigt. |
Die Verpackung enthält 198 Windeln. Die Verpackung besagt, dass die Windel für ein Kind mit einem Gewicht von 22-37 lbs gedacht sind. Das durchschnittliche Kind in diesem Gewichtbereich ist wahrscheinlich zwischen 1 und 2 Jahren alt. Eine Zweijährige braucht in der Regel sechs Windeln pro Tag, daher halten sie etwa 33 Tage (198/6). |
Antwort des Modells an die Eingabe anpassen
Bitten Sie das Modell, die Bilder zu beschreiben, bevor es die Aufgabe im Prompt ausführt.
| Prompt | Modellantwort |
|---|---|



Was haben diese Bilder gemeinsam? |
Alle vier Bilder sind Beispiele für Bilder im Querformat. |
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
Beschreiben Sie zuerst im Detail, was die einzelnen Bilder enthalten. Was haben diese Bilder gemeinsam? |
Das erste Bild zeigt eine Person, die einen Koffer verpackt, das zweite zeigt einen leeren Flur in einem Einkaufszentrum, das dritte Bild zeigt einen Rolle von Toilettenpapier und das vierte Bild ein dunkles und stürmisches Meer. Die Gemeinsamkeiten zwischen diesen Bildern sind, dass sie alle Beispiele für Grenzbereiche sind. Grenzbereich sind Orte oder Situationen, die zwischen zwei anderen Orten oder Situationen liegen. Sie sind oft durch ein Gefühl von Unsicherheit oder Mehrdeutigkeit gekennzeichnet. Das erste Bild zeigt die Person, die zwischen der zu Hause und einer Reise steht. Die zweite Abbildung zeigt den Flur zwischen zwei Geschäften. Das dritte Bild ist Toilettenpapier, das ein Bad darstellen kann. Ein Badezimmer ist ein Übergangsraum zwischen privaten und öffentlichen Bereichen. Es ist ein Ort, an dem wir uns darauf vorbereiten, die Außenwelt zu betreten und zu verlassen. Das vierte Bild zeigt das Meer zwischen Ruhe und Sturm. Grenzbereiche können sowohl interessant als auch unübersichtlich sein. Sie können ein Ort für einen neuen Anfang oder ein Ort mit Endungen sein. Sie können ein Ort der Reflexion oder ein Handlungsort sein. |
Sie können das Modell explizit auffordern, auf den Inhalt des Bildes zu verweisen.
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
Was haben diese Bilder gemeinsam? In der Antwort auf den Inhalt der Bildern verweisen |
Alle Bilder beziehen sich auf Reisen. Das erste Bild zeigt eine Person, die einen Koffer packt, das zweite einen leeren Flur in einem Einkaufszentrum, das dritte einen Stapel Toilettenpapier und das vierte ein dunkles und stürmisches Meer. Diese Bilder beziehen sich alle auf Reisen, da es alles ist, was Nutzer auf Reisen brauchen oder verwenden. Das erste Bild zeigt eine Person, die einen Koffer packt. Das ist etwas, was Menschen vor einer Reise tun. Das zweite Bild zeigt einen leeren Flur in einem Einkaufszentrum, in dem Nutzer häufig Dinge für Ihre Reisen kaufen. Das dritte Bild zeigt einen Stapel von Toilettenpapier, das Menschen häufig auf Reisen verwenden. Das vierte Bild zeigt ein dunkles und stürmisches Meer. Dies ist eines der Dinge, auf die Menschen häufig auf Reisen treffen. |
Dieselben Tipps gelten auch für die Creative-Ausgabe. Fordern Sie das Modell explizit auf, Aspekte aus dem Bild zu berücksichtigen. Das kann die Ausgabe verbessern.
| Prompt | Modellantwort |
|---|---|

Kannst du mir ein Gedicht zu diesem Bild schreiben? |
Little bunny, so soft and brown,
Hopping through the field, up and down.
Your ears so long, your tail so small,
You're the cutest creature of them all.You nibble on the grass, so green and sweet,
And hop away when you see me.
But I'll always be your friend,
Little bunny, until the very end. |
| Aktualisierter Prompt | Verbesserte Reaktion |
|---|---|
|
Können Sie mir ein beschreibendes und pathetisches Gedicht zu diesem Bild schreiben und den Standort einbeziehen? |
Little bunny on the green,
Ears so long, so keen.
What do you see out there,
In the distance, where you stare?Is it the ocean blue,
Sparkling in the sun's hue?
Or the waves that crash and roar,
A rhythm that you adore?Little bunny, tell me true,
What captures your attention so?
Is it the salty breeze,
Or the seagulls' cries that please?Perhaps it's the vastness of it all,
A world so big and small.
A place where dreams can roam,
And adventures can be sown.Little bunny, I wonder what you dream,
As you sit on the grass, so serene.
Do you yearn to explore the deep,
Or stay on land, where you can leap?Whatever it may be, little bunny,
Keep that spark of wonder burning brightly.
For in your dreams and aspirations,
Lies a world waiting for your creation. |
Ermitteln, warum der Prompt fehlgeschlagen ist
Eine Eingabeaufforderung kann fehlschlagen, weil das Modell das Bild überhaupt nicht verstanden hat oder weil es danach nicht die richtigen logischen Schritte ausgeführt hat. Um zwischen diesen Logiken zu unterscheiden, bitten Sie das Modell, den Inhalt des Bildes zu beschreiben.
Wenn das Modell in diesem Beispiel mit Snacks antwortet, die bei Kombination mit Tee (z. B. Popcorn) überraschend sind, können Sie zuerst eine Fehlerbehebung durchführen, um festzustellen, ob das Modell richtig erkannt hat, dass das Bild Tee zeigt.
| Prompt | Prompt zur Fehlerbehebung |
|---|---|

Welchen Snack kann ich in einer Minute machen, der dazu gut passe würde? |
Beschreiben Sie den Inhalt des Bildes. |
Wenn Sie das Modell auffordern, seine Logik zu erklären, kann das helfen, einzugrenzen, welcher Teil der Logik aufgeschlüsselt wurde.
| Prompt | Prompt zur Fehlerbehebung |
|---|---|
|
Welchen Snack kann ich in einer Minute machen, der dazu gut passe würde? |
Welchen Snack kann ich in einer Minute machen, der dazu gut passe würde? Bitte erläutere, warum. |
Parameter für die Stichprobenerhebung optimieren
In jeder Anfrage senden Sie nicht nur den multimodalen Prompt, sondern auch eine Reihe von Stichprobenparametern an das Modell. Das Modell kann für verschiedene Parameterwerte unterschiedliche Ergebnisse generieren. Experimentieren Sie mit den verschiedenen Parametern, um die besten Werte für die Aufgabe zu erhalten. Am häufigsten angepasste Parameter sind:
Temperatur
Die Temperatur wird für die Probenahme während der Antwortgenerierung verwendet. Dies passiert, wenn Top-P und Top-K angewendet werden. Die Temperatur bestimmt den Grad der Zufälligkeit bei der Tokenauswahl. Niedrigere Temperaturen eignen sich für Prompts, die deterministischere und weniger offene oder kreative Reaktionen erfordern, während höhere Temperaturen zu vielfältigeren oder kreativen Ergebnissen führen können. Eine Temperatur von 0 ist deterministisch, d. h., die Antwort mit der höchsten Wahrscheinlichkeit wird am wahrscheinlichsten ausgewählt.
Für die meisten Anwendungsfälle empfiehlt es sich, mit einer Temperatur von 0,4 zu beginnen. Wenn Sie mehr kreative Ergebnisse benötigen, erhöhen Sie die Temperatur. Wenn Sie deutliche Halluzinationen beobachten, senken Sie die Temperatur.
Top-P
Der Wert „Top-P“ ändert, wie das Modell Tokens für die Ausgabe auswählt. Tokens werden vom wahrscheinlichsten bis zum am wenigsten wahrscheinlichen Token ausgewählt, bis die Summe ihrer Wahrscheinlichkeiten dem Wert von „Top-P“ entspricht. Beispiel: Wenn die Tokens A, B und C eine Wahrscheinlichkeit von 0,6, 0,3 und 0,1 haben und der Wert von „Top-P“ 0,9 ist, wählt das Modell entweder A oder B als nächstes Token aus (mithilfe der Temperatur) und berücksichtigt C nicht.
Geben Sie einen niedrigeren Wert für weniger zufällige Antworten und einen höheren Wert für zufälligere Antworten an. Der Standardwert von „Top-P“ ist 1,0.
Nächste Schritte
- Wagen Sie sich an eine Kurzeinführung mit Generative AI Studio oder der Vertex AI API.
- Eine Einführung in die Verwendung der Gemini API in Vertex AI finden Sie in der Kurzanleitung für die Gemini API in Vertex AI.