Questa pagina fornisce una panoramica della regolazione dei modelli di testo e di chat e dell'estrazione dei modelli di testo. Scopri i tipi di ottimizzazione disponibili e come funziona la distillazione. Scopri anche i vantaggi della regolazione e della distillazione, nonché scenari in cui potresti voler regolare o distillare un modello di testo.
Ottimizzare i modelli
Per ottimizzare un modello di testo, puoi scegliere uno dei seguenti metodi:
Ottimizzazione supervisionata: i modelli di generazione di testo e chat di testo supportano l'ottimizzazione supervisionata. L'ottimizzazione supervisionata di un modello di testo è una buona opzione quando l' output del modello non è complesso ed è relativamente facile da definire. L'ottimizzazione supervisionata è consigliata per la classificazione, l'analisi del sentiment, l'estrazione delle entità, il riepilogo di contenuti non complessi e la scrittura di query specifiche per dominio. Per i modelli di codice, l'ottimizzazione supervisionata è l'unica opzione. Per scoprire come ottimizzare un modello di testo con l'ottimizzazione supervisionata, consulta Ottimizzare i modelli di testo con l'ottimizzazione supervisionata.
Ottimizzazione dell'apprendimento per rinforzo con feedback umano (RLHF): il modello di base per la generazione di testo e alcuni modelli di trasferimento di Flan da testo a testo (Flan-T5) supportano l'ottimizzazione RLHF. L'ottimizzazione RLHF è una buona opzione quando l'output del modello è complesso. L'ottimizzazione RLHF funziona bene sui modelli con obiettivi a livello di sequenza che non sono facilmente differenziabili con l'ottimizzazione supervisionata. La regolazione RLHF è consigliata per la risposta alle domande, il riassunto di contenuti complessi e la creazione di contenuti, ad esempio con la riscrittura. Per scoprire come ottimizzare un modello di testo con l'ottimizzazione RLHF, consulta Ottimizzare i modelli di testo con l'ottimizzazione RLHF.
Vantaggi dell'ottimizzazione del modello di testo
I modelli di testo ottimizzati vengono addestrati su più esempi di quelli che possono essere inseriti in un prompt. Per questo motivo, dopo aver ottimizzato un modello preaddestrato, puoi fornire meno esempi nel prompt rispetto a quanto faresti con il modello preaddestrato originale. Richiedere meno esempi comporta i seguenti vantaggi:
- Latenza inferiore nelle richieste.
- Vengono utilizzati meno token.
- Una latenza inferiore e un numero inferiore di token riducono il costo dell'inferenza.
Distillazione del modello
Oltre all'ottimizzazione supervisionata e RLHF, Vertex AI supporta la distillazione dei modelli. La distillazione è il processo di addestramento di un modello studente più piccolo su un modello insegnante più grande per imitare il comportamento del modello più grande riducendone le dimensioni.
Esistono diversi tipi di distillazione del modello, tra cui:
- In base alle risposte: addestrare il modello studente in base alle probabilità di risposta del modello insegnante.
- In base alle funzionalità: addestra il modello studente a imitare i livelli interni del modello insegnante.
- In base alle relazioni: addestrare il modello dello studente sulle relazioni nei dati di input o di output del modello dell'insegnante.
- Auto-distillazione: i modelli insegnante e studente hanno la stessa architettura e il modello si auto-insegna.
Vantaggi della distillazione passo passo
I vantaggi della distillazione passo passo includono:
- Precisione migliorata: è stato dimostrato che la distillazione passo passo supera il prompt few-shot standard sugli LLM.
- Un LLM distillato può ottenere risultati sulle attività finali specifiche degli utenti simili a quelli di LLM molto più grandi.
- Supera i vincoli dei dati. Puoi utilizzare DSS con un set di dati di prompt non etichettato con solo poche migliaia di esempi.
- Impronte di hosting più piccole.
- Latenza di inferenza ridotta.
Distillare la procedura passo passo utilizzando Vertex AI
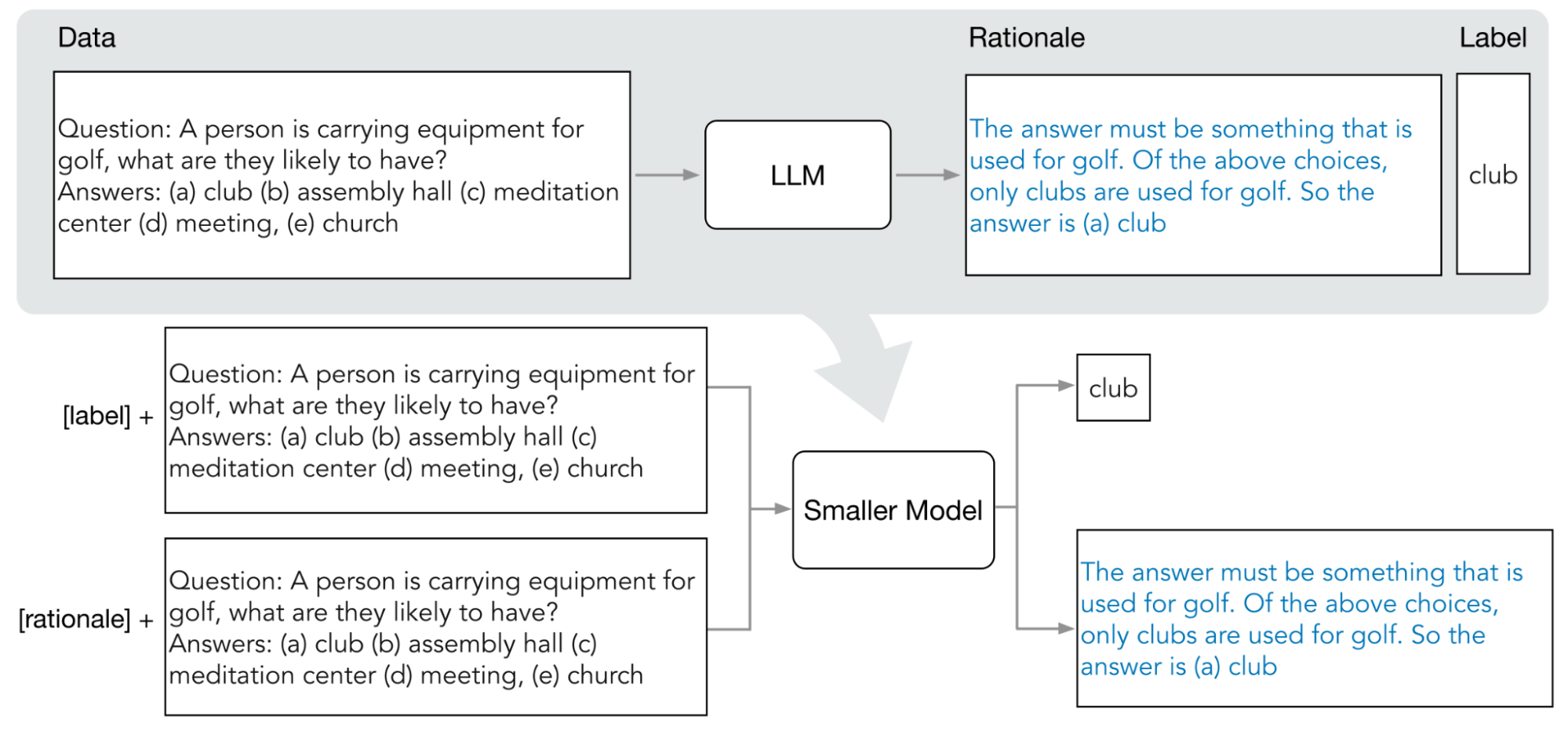
Vertex AI supporta una forma di distillazione basata sulle risposte chiamata distillazione passo passo (DSS). La distillazione step-by-step (DSS) è un metodo per addestrare modelli più piccoli e specifici per attività tramite prompt a catena di pensieri (Chain-of-Thought, COT).
Per utilizzare DSS, è necessario un piccolo set di dati di addestramento composto da input e etichette. Se le etichette non sono disponibili, il modello insegnante le genera. Le motivazioni vengono estratte dal processo DSS e poi utilizzate per addestrare il piccolo modello con un'attività di generazione di motivazioni e un'attività di previsione tipica. In questo modo, il piccolo modello può elaborare un ragionamento intermedio prima di raggiungere la previsione finale.
Il seguente diagramma mostra come la distillazione passo passo utilizza i prompt COT per estrarre le motivazioni da un modello linguistico di grandi dimensioni (LLM). Le spiegazioni vengono utilizzate per addestrare modelli più piccoli e specifici per attività.
Quota
Ogni progetto Google Cloud richiede una quota sufficiente per eseguire un job di ottimizzazione e un job di ottimizzazione utilizza 8 GPU. Se il tuo progetto non dispone di quota sufficiente per un job di ottimizzazione o se vuoi eseguire più job di ottimizzazione contemporaneamente nel progetto, devi richiedere una quota aggiuntiva.
La tabella seguente mostra il tipo e la quantità di quota da richiedere in base alla regione in cui hai specificato che deve essere eseguita la regolazione:
| Regione | Quota per le risorse | Importo per job simultaneo |
|---|---|---|
|
|
8 |
|
96 | |
|
|
64 |
Prezzi
Quando ottimizzi o distilli un modello di base, paghi il costo di esecuzione della pipeline di ottimizzazione o distillazione. Quando esegui il deployment di un modello di base ottimizzato o distillato su un endpoint Vertex AI, non ti viene addebitato alcun costo per l'hosting. Per la pubblicazione delle previsioni, paghi lo stesso prezzo che paghi quando pubblichi le previsioni utilizzando un modello di base non ottimizzato (per l'ottimizzazione) o il modello dello studente (per la distillazione). Per scoprire quali modelli di base possono essere ottimizzati e distillati, consulta Modelli di base. Per dettagli sui prezzi, consulta la pagina Prezzi per l'IA generativa su Vertex AI.
Passaggi successivi
- Scopri come ottimizzare un modello di base utilizzando l'ottimizzazione supervisionata.
- Scopri come ottimizzare un modello di base utilizzando l'ottimizzazione RLHF.
- Scopri come ottimizzare un modello di codice.
- Scopri come estrarre un modello di testo.