本页面简要介绍了如何调优文本和聊天模型以及对文本模型进行提炼。您将了解可用的调优类型以及提炼的工作原理。您还将了解调优和提炼的好处,以及可能需要调优或提炼文本模型的场景。
调优模型
您可以选择以下方法之一来调整文本模型:
监督式调整 - 文本生成和文字聊天模型支持监督式调整。如果模型的输出不复杂且相对容易定义,则对文本模型进行监督式调整是一个不错的选择。建议将监督式调整用于分类、情感分析、实体提取、非复杂内容的总结以及编写特定领域的查询。对于代码模型,只能选择监督式调整。如需了解如何使用监督式调整来调整文本模型,请参阅使用监督式调整来调整文本模型。
基于人类反馈的强化学习 (RLHF) 调整 - 文本生成基础模型和一些 Flan Text-to-Text Transfer Transformer (Flan-T5) 模型支持 RLHF 调整。如果模型的输出很复杂,RLHF 调节便是不错的选择。RLHF 非常适合具有无法通过监督式调整轻松区分的序列级目标的模型。建议将 RLHF 调整用于问答、复杂内容的总结以及内容创建(例如改写)。如需了解如何使用 RLHF 调整来调整文本模型,请参阅使用 RLHF 调整来调整文本模型。
调整文本模型的好处
调整后的文本模型基于更多样本(超过提示中可容下的样本数)进行训练。因此,调整预先训练的模型后,相较于原始的预训练模型,您可以在提示中提供更少的样本。需要的样本更少可带来以下好处:
- 请求的延迟时间更短。
- 使用的词元更少。
- 延迟时间缩短,词元数量减少,推理费用继而降低。
模型提炼
除了监督式和 RLHF 调优之外,Vertex AI 还支持模型提炼。蒸馏是指在较大的教师模型上训练较小的学生模型,以在缩小模型大小的同时模仿较大模型的行为。
模型蒸馏有以下几种类型:
- 基于回答:根据教师模型的回答概率训练学生模型。
- 基于特征:训练学生模型以模仿教师模型的内部层。
- 基于关系:根据教师模型的输入或输出数据中的关系训练学生模型。
- 自行提炼:教师和学生模型具有相同的架构,模型自学。
分步蒸馏的好处
分步蒸馏的好处包括:
- 提高了准确性:分步提示在 LLM 上优于标准少样本提示。
- 精简的 LLM 可以针对用户的特定最终任务取得与更大 LLM 类似的结果。
- 克服数据限制。您可以将 DSS 与仅包含几千个示例的未标记提示数据集搭配使用。
- 托管空间占用更小。
- 缩短了推理延迟时间。
使用 Vertex AI 分步提取数据
Vertex AI 支持一种基于回答的提炼,称为分步提炼 (DSS)。DSS 是一种通过思维链 (COT) 提示训练针对特定任务的较小模型的方法。
如需使用 DSS,您需要一个由输入和标签组成的小型训练数据集。如果没有标签,教师模型会生成标签。理由由 DSS 流程提取,然后用于通过理由生成任务和典型预测任务训练小型模型。这样,小型模型就可以在做出最终预测之前构建中间推理。
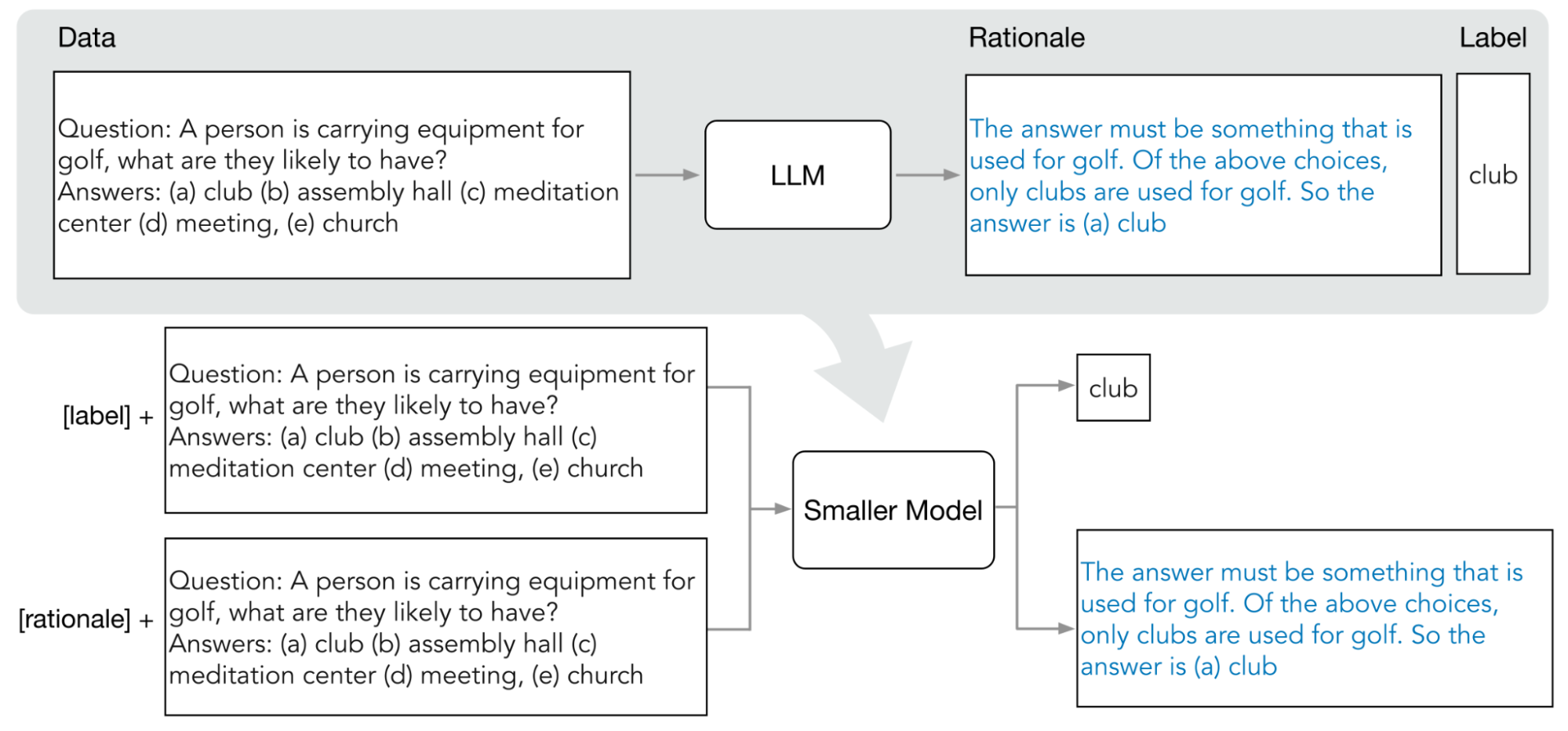
下图展示了分步提炼如何使用 COT 提示从大型语言模型 (LLM) 中提取理由。这些理由用于训练特定于任务的较小模型。
配额
每个 Google Cloud 项目都需要足够的配额来运行一个调优作业,一个调优作业使用 8 个 GPU。如果您的项目没有足够的配额来完成一个调优作业,或者您想要在项目中运行多个并发调优作业,则需要申请更多配额。
下表显示了根据您指定进行调优的区域请求的配额类型和数量:
| 区域 | 资源配额 | 每个并发作业的数量 |
|---|---|---|
|
|
8 |
|
96 | |
|
|
64 |
价格
调优或提炼基础模型时,您需要支付运行调优或提炼流水线的费用。将调优或提炼后的基础模型部署到 Vertex AI 端点时,您无需为托管付费。对于执行预测,使用未经调优的基础模型(适用于调优)或学生模型(适用于提炼)执行预测时支付的费用相同。 如需了解可以调优和提炼哪些基础模型,请参阅基础模型。如需了解价格详情,请参阅 Vertex AI 上的生成式 AI 的价格。
后续步骤
- 了解如何使用监督式调优来对基础模型调优。
- 了解如何使用 RLHF 调优来对基础模型调优。
- 了解如何调优代码模型。
- 了解如何蒸馏文本模型。