This page introduces how to perform pairwise model-based evaluation using AutoSxS, which is a tool that runs through the evaluation pipeline service. We explain how you can use AutoSxS through the Vertex AI API, Vertex AI SDK for Python, or the Google Cloud console.
AutoSxS
Automatic side-by-side (AutoSxS) is a pairwise model-based evaluation tool that runs through the evaluation pipeline service. AutoSxS can be used to evaluate the performance of either generative AI models in Vertex AI Model Registry or pre-generated predictions, which allows it to support Vertex AI foundation models, tuned generative AI models, and third-party language models. AutoSxS uses an autorater to decide which model gives the better response to a prompt. It's available on demand and evaluates language models with comparable performance to human raters.
The autorater
At a high level, the diagram shows how AutoSxS compares the predictions of models A and B with a third model, the autorater.
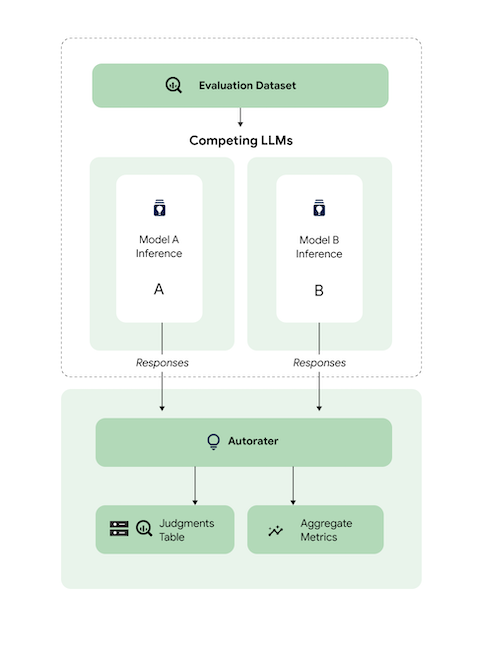
Models A and B receive input prompts, and each model generates responses that are sent to the autorater. Similar to a human rater, an autorater is a language model that judges the quality of model responses given an original inference prompt. With AutoSxS, the autorater compares the quality of two model responses given their inference instruction by using a set of criteria. The criteria are used to determine which model performed the best by comparing Model A's results with Model B's results. The autorater outputs response preferences as aggregate metrics and outputs preference explanations and confidence scores for each example. For more information, see the judgment table.
Supported models
AutoSxS supports evaluation of any model when pre-generated predictions are provided. AutoSxS also supports automatically generating responses for any model in Vertex AI Model Registry that supports batch prediction on Vertex AI.
If your Text model isn't supported by Vertex AI Model Registry, AutoSxS also accepts pre-generated predictions stored as JSONL in Cloud Storage or a BigQuery table. For pricing, see Text generation.
Supported tasks and criteria
AutoSxS supports evaluating models for summarization and question-answering tasks. The evaluation criteria are predefined for each task, which make language evaluation more objective and improve response quality.
The criteria are listed by task.
Summarization
The summarization task has a 4,096 input token
limit.
The list of evaluation criteria for summarization is as follows:
| Criteria | |
|---|---|
| 1. Follows instructions | To what extent does the model's response demonstrate an understanding of the instruction from the prompt? |
| 2. Grounded | Does the response include only information from the inference context and inference instruction? |
| 3. Comprehensive | To what extent does the model capture key details in the summarization? |
| 4. Brief | Is the summarization verbose? Does it include flowery language? Is it overly terse? |
Question answer
The question_answering task has a 4,096 input token
limit.
The list of evaluation criteria for question_answering is as follows:
| Criteria | |
|---|---|
| 1. Fully answers the question | The answer responds to the question, completely. |
| 2. Grounded | Does the response include only information from the instruction context and inference instruction? |
| 3. Relevance | Does the content of the answer relate to the question? |
| 4. Comprehensive | To what extent does the model capture key details in the question? |
Prepare evaluation dataset for AutoSxS
This section details the data you should provide in your AutoSxS evaluation dataset and best practices for dataset construction. The examples should mirror real-world inputs that your models might encounter in production and best contrast how your live models behave.
Dataset format
AutoSxS accepts a single evaluation dataset with a flexible schema. The dataset can be a BigQuery table or stored as JSON Lines in Cloud Storage.
Each row of the evaluation dataset represents a single example, and the columns are one of the following:
- ID columns: Used to identify each unique example.
- Data columns: Used to fill out prompt templates. See Prompt parameters
- Pre-generated predictions: Predictions made by the same model using the same prompt. Using pre-generated predictions saves time and resources.
- Ground-truth human preferences: Used to benchmark AutoSxS against your ground-truth preference data when pre-generated predictions are provided for both models.
Here is an example evaluation dataset where context and question are data columns, and model_b_response contains pre-generated predictions.
context |
question |
model_b_response |
|---|---|---|
| Some might think that steel is the hardest material or titanium, but diamond is actually the hardest material. | What is the hardest material? | Diamond is the hardest material. It is harder than steel or titanium. |
For more information on how to call AutoSxS, see Perform model evaluation. For details about token length, see Supported tasks and criteria. To upload your data to Cloud Storage, see Upload evaluation dataset to Cloud Storage.
Prompt parameters
Many language models take prompt parameters as inputs instead of a single prompt
string. For example,
chat-bison takes
several prompt parameters (messages, examples, context), which make up pieces
of the prompt. However, text-bison
has only one prompt parameter, named prompt, which contains the entire
prompt.
We outline how you can flexibly specify model prompt parameters at inference and evaluation time. AutoSxS gives you the flexibility to call language models with varying expected inputs through templated prompt parameters.
Inference
If any of the models don't have pre-generated predictions, AutoSxS uses Vertex AI batch prediction to generate responses. Each model's prompt parameters must be specified.
In AutoSxS, you can provide a single column in the evaluation dataset as a prompt parameter.
{'some_parameter': {'column': 'my_column'}}
Alternatively, you can define templates, using columns from the evaluation dataset as variables, to specify prompt parameters:
{'some_parameter': {'template': 'Summarize the following: {{ my_column }}.'}}
When providing model prompt parameters for inference, users can use the
protected default_instruction keyword as a template argument, which is
replaced with the default inference instruction for the given task:
model_prompt_parameters = {
'prompt': {'template': '{{ default_instruction }}: {{ context }}'},
}
If generating predictions, provide model prompt parameters and an output column. See the following examples:
Gemini
For Gemini models, the keys for model prompt parameters are
contents (required) and system_instruction (optional), which align with
the Gemini request body
schema.
model_a_prompt_parameters={
'contents': {
'column': 'context'
},
'system_instruction': {'template': '{{ default_instruction }}'},
},
text-bison
For example, text-bison uses "prompt" for input and "content" for
output. Follow these
steps:
- Identify the inputs and outputs needed by the models being evaluated.
- Define the inputs as model prompt parameters.
- Pass output to the response column.
model_a_prompt_parameters={
'prompt': {
'template': {
'Answer the following question from the point of view of a college professor: {{ context }}\n{{ question }}'
},
},
},
response_column_a='content', # Column in Model A response.
response_column_b='model_b_response', # Column in eval dataset.
Evaluation
Just as you must provide prompt parameters for inference, you must also provide prompt parameters for evaluation. The autorater requires the following prompt parameters:
| Autorater prompt parameter | Configurable by user? | Description | Example |
|---|---|---|---|
| Autorater instruction | No | A calibrated instruction describing the criteria the autorater should use to judge the given responses. | Pick the response that answers the question and best follows instructions. |
| Inference instruction | Yes | A description of the task each candidate model should perform. | Answer the question accurately: Which is the hardest material? |
| Inference context | Yes | Additional context for the task being performed. | While titanium and diamond are both harder than copper, diamond has a hardness rating of 98 while titanium has a rating of 36. A higher rating means higher hardness. |
| Responses | No1 | A pair of responses to evaluate, one from each candidate model. | Diamond |
1You can only configure the prompt parameter through pre-generated responses.
Sample code using the parameters:
autorater_prompt_parameters={
'inference_instruction': {
'template': 'Answer the following question from the point of view of a college professor: {{ question }}.'
},
'inference_context': {
'column': 'context'
}
}
Models A and B can have inference instructions and context that are formatted differently, whether or not the same information is provided. This means that the autorater takes a separate but single inference instruction and context.
Example of evaluation dataset
This section provides an example of a question-answer task evaluation dataset,
including pre-generated predictions for model B. In this example, AutoSxS
performs inference only for model A. We provide an id column to differentiate
between examples with the same question and context.
{
"id": 1,
"question": "What is the hardest material?",
"context": "Some might think that steel is the hardest material, or even titanium. However, diamond is actually the hardest material.",
"model_b_response": "Diamond is the hardest material. It is harder than steel or titanium."
}
{
"id": 2,
"question": "What is the highest mountain in the world?",
"context": "K2 and Everest are the two tallest mountains, with K2 being just over 28k feet and Everest being 29k feet tall.",
"model_b_response": "Mount Everest is the tallest mountain, with a height of 29k feet."
}
{
"id": 3,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "Francis Ford Coppola directed The Godfather."
}
{
"id": 4,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "John Smith."
}
Best practices
Follow these best practices when defining your evaluation dataset:
- Provide examples that represent the types of inputs, which your models process in production.
- Your dataset must include a minimum of one evaluation example. We recommend around 100 examples to ensure high-quality aggregate metrics. The rate of aggregate-metric quality improvements tends to decrease when more than 400 examples are provided.
- For a guide to writing prompts, see Design text prompts.
- If you're using pre-generated predictions for either model, include the pre-generated predictions in a column of your evaluation dataset. Providing pre-generated predictions is useful, because it lets you compare the output of models that aren't in Vertex Model Registry and lets you reuse responses.
Perform model evaluation
You can evaluate models by using the REST API, Vertex AI SDK for Python, or the Google Cloud console.
Use this syntax to specify the path to your model:
- Publisher model:
publishers/PUBLISHER/models/MODELExample:publishers/google/models/text-bison Tuned model:
projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL@VERSIONExample:projects/123456789012/locations/us-central1/models/1234567890123456789
REST
To create a model evaluation job, send a POST request by using the
pipelineJobs method.
Before using any of the request data, make the following replacements:
- PIPELINEJOB_DISPLAYNAME : Display name for the
pipelineJob. - PROJECT_ID : Google Cloud project that runs the pipeline components.
- LOCATION : Region to run the pipeline components.
us-central1is supported. - OUTPUT_DIR : Cloud Storage URI to store evaluation output.
- EVALUATION_DATASET : BigQuery table or a comma-separated list of Cloud Storage paths to a JSONL dataset containing evaluation examples.
- TASK : Evaluation task, which can be one of
[summarization, question_answering]. - ID_COLUMNS : Columns that distinguish unique evaluation examples.
- AUTORATER_PROMPT_PARAMETERS : Autorater prompt parameters mapped to columns or templates. The expected parameters are:
inference_instruction(details on how to perform a task) andinference_context(content to reference to perform the task). As an example,{'inference_context': {'column': 'my_prompt'}}uses the evaluation dataset's `my_prompt` column for the autorater's context. - RESPONSE_COLUMN_A : Either the name of a column in the evaluation dataset containing predefined predictions, or the name of the column in the Model A output containing predictions. If no value is provided, the correct model output column name will attempt to be inferred.
- RESPONSE_COLUMN_B : Either the name of a column in the evaluation dataset containing predefined predictions, or the name of the column in the Model B output containing predictions. If no value is provided, the correct model output column name will attempt to be inferred.
- MODEL_A (Optional): A fully-qualified model resource name (
projects/{project}/locations/{location}/models/{model}@{version}) or publisher model resource name (publishers/{publisher}/models/{model}). If Model A responses are specified, this parameter shouldn't be provided. - MODEL_B (Optional): A fully-qualified model resource name (
projects/{project}/locations/{location}/models/{model}@{version}) or publisher model resource name (publishers/{publisher}/models/{model}). If Model B responses are specified, this parameter shouldn't be provided. - MODEL_A_PROMPT_PARAMETERS (Optional): Model A's prompt template parameters mapped to columns or templates. If Model A responses are predefined, this parameter shouldn't be provided. Example:
{'prompt': {'column': 'my_prompt'}}uses the evaluation dataset'smy_promptcolumn for the prompt parameter namedprompt. - MODEL_B_PROMPT_PARAMETERS (Optional): Model B's prompt template parameters mapped to columns or templates. If Model B responses are predefined, this parameter shouldn't be provided. Example:
{'prompt': {'column': 'my_prompt'}}uses the evaluation dataset'smy_promptcolumn for the prompt parameter namedprompt. - JUDGMENTS_FORMAT
(Optional): The format to write judgments to. Can be
jsonl(default),json, orbigquery. - BIGQUERY_DESTINATION_PREFIX: BigQuery table to write judgments to if the specified format is
bigquery.
Request JSON body
{
"displayName": "PIPELINEJOB_DISPLAYNAME",
"runtimeConfig": {
"gcsOutputDirectory": "gs://OUTPUT_DIR",
"parameterValues": {
"evaluation_dataset": "EVALUATION_DATASET",
"id_columns": ["ID_COLUMNS"],
"task": "TASK",
"autorater_prompt_parameters": AUTORATER_PROMPT_PARAMETERS,
"response_column_a": "RESPONSE_COLUMN_A",
"response_column_b": "RESPONSE_COLUMN_B",
"model_a": "MODEL_A",
"model_a_prompt_parameters": MODEL_A_PROMPT_PARAMETERS,
"model_b": "MODEL_B",
"model_b_prompt_parameters": MODEL_B_PROMPT_PARAMETERS,
"judgments_format": "JUDGMENTS_FORMAT",
"bigquery_destination_prefix":BIGQUERY_DESTINATION_PREFIX,
},
},
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default"
}
Use curl to send your request.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/pipelineJobs"
Response
"state": "PIPELINE_STATE_PENDING",
"labels": {
"vertex-ai-pipelines-run-billing-id": "1234567890123456789"
},
"runtimeConfig": {
"gcsOutputDirectory": "gs://my-evaluation-bucket/output",
"parameterValues": {
"evaluation_dataset": "gs://my-evaluation-bucket/output/data.json",
"id_columns": [
"context"
],
"task": "question_answering",
"autorater_prompt_parameters": {
"inference_instruction": {
"template": "Answer the following question: {{ question }} }."
},
"inference_context": {
"column": "context"
}
},
"response_column_a": "",
"response_column_b": "response_b",
"model_a": "publishers/google/models/text-bison@002",
"model_a_prompt_parameters": {
"prompt": {
"template": "Answer the following question from the point of view of a college professor: {{ question }}\n{{ context }} }"
}
},
"model_b": "",
"model_b_prompt_parameters": {}
}
},
"serviceAccount": "123456789012-compute@developer.gserviceaccount.com",
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default",
"templateMetadata": {
"version": "sha256:7366b784205551ed28f2c076e841c0dbeec4111b6df16743fc5605daa2da8f8a"
}
}
Vertex AI SDK for Python
To learn how to install or update the Vertex AI SDK for Python, see Install the Vertex AI SDK for Python. For more information on the Python API, see the Vertex AI SDK for Python API.
For more information about pipeline parameters, see Google Cloud Pipeline Components Reference Documentation.
Before using any of the request data, make the following replacements:
- PIPELINEJOB_DISPLAYNAME : Display name for the
pipelineJob. - PROJECT_ID : Google Cloud project that runs the pipeline components.
- LOCATION : Region to run the pipeline components.
us-central1is supported. - OUTPUT_DIR : Cloud Storage URI to store evaluation output.
- EVALUATION_DATASET : BigQuery table or a comma-separated list of Cloud Storage paths to a JSONL dataset containing evaluation examples.
- TASK : Evaluation task, which can be one of
[summarization, question_answering]. - ID_COLUMNS : Columns that distinguish unique evaluation examples.
- AUTORATER_PROMPT_PARAMETERS : Autorater prompt parameters mapped to columns or templates. The expected parameters are:
inference_instruction(details on how to perform a task) andinference_context(content to reference to perform the task). As an example,{'inference_context': {'column': 'my_prompt'}}uses the evaluation dataset's `my_prompt` column for the autorater's context. - RESPONSE_COLUMN_A : Either the name of a column in the evaluation dataset containing predefined predictions, or the name of the column in the Model A output containing predictions. If no value is provided, the correct model output column name will attempt to be inferred.
- RESPONSE_COLUMN_B : Either the name of a column in the evaluation dataset containing predefined predictions, or the name of the column in the Model B output containing predictions. If no value is provided, the correct model output column name will attempt to be inferred.
- MODEL_A (Optional): A fully-qualified model resource name (
projects/{project}/locations/{location}/models/{model}@{version}) or publisher model resource name (publishers/{publisher}/models/{model}). If Model A responses are specified, this parameter shouldn't be provided. - MODEL_B (Optional): A fully-qualified model resource name (
projects/{project}/locations/{location}/models/{model}@{version}) or publisher model resource name (publishers/{publisher}/models/{model}). If Model B responses are specified, this parameter shouldn't be provided. - MODEL_A_PROMPT_PARAMETERS (Optional): Model A's prompt template parameters mapped to columns or templates. If Model A responses are predefined, this parameter shouldn't be provided. Example:
{'prompt': {'column': 'my_prompt'}}uses the evaluation dataset'smy_promptcolumn for the prompt parameter namedprompt. - MODEL_B_PROMPT_PARAMETERS (Optional): Model B's prompt template parameters mapped to columns or templates. If Model B responses are predefined, this parameter shouldn't be provided. Example:
{'prompt': {'column': 'my_prompt'}}uses the evaluation dataset'smy_promptcolumn for the prompt parameter namedprompt. - JUDGMENTS_FORMAT
(Optional): The format to write judgments to. Can be
jsonl(default),json, orbigquery. - BIGQUERY_DESTINATION_PREFIX: BigQuery table to write judgments to if the specified format is
bigquery.
import os
from google.cloud import aiplatform
parameters = {
'evaluation_dataset': 'EVALUATION_DATASET',
'id_columns': ['ID_COLUMNS'],
'task': 'TASK',
'autorater_prompt_parameters': AUTORATER_PROMPT_PARAMETERS,
'response_column_a': 'RESPONSE_COLUMN_A',
'response_column_b': 'RESPONSE_COLUMN_B',
'model_a': 'MODEL_A',
'model_a_prompt_parameters': MODEL_A_PROMPT_PARAMETERS,
'model_b': 'MODEL_B',
'model_b_prompt_parameters': MODEL_B_PROMPT_PARAMETERS,
'judgments_format': 'JUDGMENTS_FORMAT',
'bigquery_destination_prefix':
BIGQUERY_DESTINATION_PREFIX,
}
aiplatform.init(project='PROJECT_ID', location='LOCATION', staging_bucket='gs://OUTPUT_DIR')
aiplatform.PipelineJob(
display_name='PIPELINEJOB_DISPLAYNAME',
pipeline_root=os.path.join('gs://OUTPUT_DIR', 'PIPELINEJOB_DISPLAYNAME'),
template_path=(
'https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default'),
parameter_values=parameters,
).run()
Console
To create a pairwise model evaluation job by using the Google Cloud console, perform the following steps:
Start with a Google foundation model, or use a model that already exists in your Vertex AI Model Registry:
To evaluate a Google foundation model:
Go to the Vertex AI Model Garden and select a model that supports pairwise evaluation, such as
text-bison.Click Evaluate.
In the menu that appears, click Select to select a model version.
A Save model pane may ask you to save a copy of the model in Vertex AI Model Registry if you don't have a copy already. Enter a Model name and click Save.
A Create Evaluation page appears. For the Evaluate Method step, select Evaluate this model against another model.
Click Continue.
To evaluate an existing model in the Vertex AI Model Registry:
Go to the Vertex AI Model Registry page:
Click the name of the model you want to evaluate. Make sure the model type has pairwise evaluation support. For example,
text-bison.In the Evaluate tab, click SxS.
Click Create SxS Evaluation.
For each step in the evaluation creation page, enter the required information and click Continue:
For the Evaluation dataset step, select an evaluation objective and a model to compare against your selected model. Select an evaluation dataset and enter the id columns (response columns).
For the Model settings step, specify whether you want to use the model responses already in your dataset, or if you want to use Vertex AI Batch Prediction to generate the responses. Specify the response columns for both models. For the Vertex AI Batch Prediction option, you can specify your inference model prompt parameters.
For the Autorater settings step, enter your autorater prompt parameters and an output location for the evaluations.
Click Start Evaluation.
View evaluation results
You can find the evaluation results in the Vertex AI Pipelines by inspecting the following artifacts produced by the AutoSxS pipeline:
- The judgments table is produced by the AutoSxS arbiter.
- Aggregate metrics are produced by the AutoSxS metrics component.
- Human-preference alignment metrics are produced by the AutoSxS metrics component.
Judgments
AutoSxS outputs judgments (example-level metrics) that help users understand model performance at the example level. Judgments include the following information:
- Inference prompts
- Model responses
- Autorater decisions
- Rating explanations
- Confidence scores
Judgments can be written to Cloud Storage in JSONL format or to a BigQuery table with these columns:
| Column | Description |
|---|---|
| id columns | Columns that distinguish unique evaluation examples. |
inference_instruction |
Instruction used to generate model responses. |
inference_context |
Context used to generate model responses. |
response_a |
Model A's response, given inference instruction and context. |
response_b |
Model B's response, given inference instruction and context. |
choice |
The model with the better response. Possible values are Model A, Model B, or Error. Error means that an error prevented the autorater from determining whether model A's response or model B's response was best. |
confidence |
A score between 0 and 1, which signifies how confident the autorater was with its choice. |
explanation |
The autorater's reason for its choice. |
Aggregate metrics
AutoSxS calculates aggregate (win-rate) metrics using the judgments table. If no human-preference data is provided, then the following aggregate metrics are generated:
| Metric | Description |
|---|---|
| AutoRater model A win rate | Percentage of time the autorater decided model A had the better response. |
| AutoRater model B win rate | Percentage of time the autorater decided model B had the better response. |
To better understand the win rate, look at the row-based results and the autorater's explanations to determine if the results and explanations align with your expectations.
Human-preference alignment metrics
If human-preference data is provided, AutoSxS outputs the following metrics:
| Metric | Description | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AutoRater model A win rate | Percentage of time the autorater decided model A had the better response. | ||||||||||||||
| AutoRater model B win rate | Percentage of time the autorater decided model B had the better response. | ||||||||||||||
| Human-preference model A win rate | Percentage of time humans decided model A had the better response. | ||||||||||||||
| Human-preference model B win rate | Percentage of time humans decided model B had the better response. | ||||||||||||||
| TP | Number of examples where both the autorater and human preferences were that Model A had the better response. | ||||||||||||||
| FP | Number of examples where the autorater chose Model A as the better response, but the human preference was that Model B had the better response. | ||||||||||||||
| TN | Number of examples where both the autorater and human preferences were that Model B had the better response. | ||||||||||||||
| FN | Number of examples where the autorater chose Model B as the better response, but the human preference was that Model A had the better response. | ||||||||||||||
| Accuracy | Percentage of time where the autorater agreed with human raters. | ||||||||||||||
| Precision | Percentage of time where both the autorater and humans thought Model A had a better response, out of all cases where the autorater thought Model A had a better response. | ||||||||||||||
| Recall | Percentage of time where both the autorater and humans thought Model A had a better response, out of all cases where humans thought Model A had a better response. | ||||||||||||||
| F1 | Harmonic mean of precision and recall. | ||||||||||||||
| Cohen's Kappa | A measurement of agreement between the autorater and human raters that takes the likelihood of random agreement into account. Cohen suggests the following interpretation:
|
AutoSxS use cases
You can explore how to use AutoSxS with three use case scenarios.
Compare models
Evaluate a tuned first-party (1p) model against a reference 1p model.
You can specify that inference runs on both models simultaneously.
This code sample evaluates a tuned model from Vertex Model Registry against a reference model from the same registry.
# Evaluation dataset schema:
# my_question: str
# my_context: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'model_a': 'publishers/google/models/text-bison@002',
'model_a_prompt_parameters': {QUESTION: {'template': '{{my_question}}\nCONTEXT: {{my_context}}'}},
'response_column_a': 'content',
'model_b': 'projects/abc/locations/abc/models/tuned_bison',
'model_b_prompt_parameters': {'prompt': {'template': '{{my_context}}\n{{my_question}}'}},
'response_column_b': 'content',
}
Compare predictions
Evaluate a tuned third-party (3p) model against a reference 3p model.
You can skip inference by directly supplying model responses.
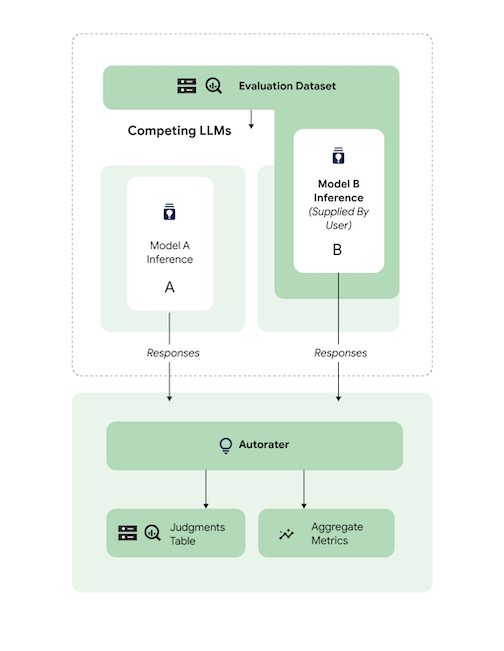
This code sample evaluates a tuned 3p model against a reference 3p model.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_b: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters':
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'content',
'response_column_b': 'response_b',
}
Check alignment
All supported tasks have been benchmarked using human-rater data to ensure that the autorater responses are aligned with human preferences. If you want to benchmark AutoSxS for your use cases, provide human-preference data directly to AutoSxS, which outputs alignment-aggregate statistics.
To check alignment against a human-preference dataset, you can specify both outputs (prediction results) to the autorater. You can also provide your inference results.
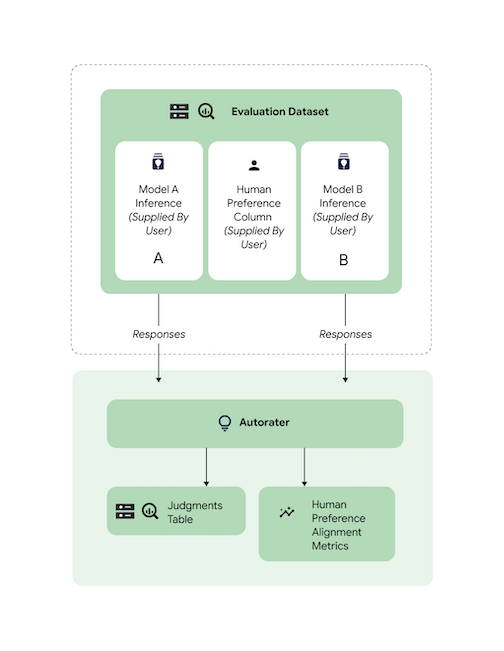
This code sample verifies that the autorater's results and explanations align with your expectations.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_a: str
# response_b: str
# actual: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'response_a',
'response_column_b': 'response_b',
'human_preference_column': 'actual',
}
What's next
- Learn about generative AI evaluation.
- Learn about online evaluation with Gen AI Evaluation Service.
- Learn how to tune language foundation models.