생성형 언어 모델을 프로그래매틱 방식으로 평가하기 위해 Vertex AI SDK for Python을 사용할 수 있습니다.
Vertex AI SDK를 설치합니다.
Vertex AI SDK for Python에서 Rapid Evaluation을 설치하려면 다음 명령어를 실행합니다.
pip install --upgrade google-cloud-aiplatform[rapid_evaluation]
자세한 내용은 Vertex AI SDK for Python 설치를 참조하세요.
Vertex AI SDK 인증
Vertex AI SDK for Python을 설치한 후 인증을 수행해야 합니다. 다음 주제에서는 로컬에서 작업하는 경우와 Colaboratory에서 작업하는 경우 Vertex AI SDK로 인증하는 방법을 설명합니다.
로컬에서 개발하는 경우 로컬 환경에서 애플리케이션 기본 사용자 인증 정보(ADC)를 설정합니다.
Colaboratory에서 작업하는 경우 Colab 셀에서 다음 명령어를 실행하여 인증합니다.
from google.colab import auth auth.authenticate_user()이 명령어를 실행하면 인증을 완료할 수 있는 창이 열립니다.
Rapid Evaluation SDK에 대한 자세한 내용은 Rapid Evaluation SDK 참조를 확인하세요.
평가 태스크 만들기
평가는 대부분 생성형 AI 모델에서 태스크 중심으로 이루어지므로 온라인 평가에서는 평가 사용 사례를 용이하게 하기 위해 평가 태스크 추상화를 도입합니다. 생성 모델을 공정하게 비교하기 위해 일반적으로 평가 데이터 세트 및 관련 측정항목에 대해 모델 및 프롬프트 템플릿에 대한 평가를 반복해서 실행할 수 있습니다. EvalTask 클래스는 이 새로운 평가 패러다임을 지원하도록 설계되었습니다. 또한 EvalTask를 사용하면 Vertex AI Experiments와 원활하게 통합할 수 있으므로 각 평가 실행의 설정과 결과를 추적할 수 있습니다.
Vertex AI Experiments는 평가 결과를 관리하고 해석하는 데 도움이 되므로 더 짧은 시간에 조치를 취할 수 있습니다. 다음 샘플은 EvalTask 클래스의 인스턴스를 만들고 평가를 실행하는 방법을 보여줍니다.
from vertexai.preview.evaluation import EvalTask
eval_task = EvalTask(
dataset=DATASET,
metrics=["bleu", "rouge_l_sum"],
experiment=EXPERIMENT_NAME
)
metrics 매개변수는 측정항목 목록을 허용하므로 단일 평가 호출로 여러 측정항목을 동시에 평가할 수 있습니다.
평가 데이터 세트 준비
데이터 세트는 EvalTask 인스턴스에 Pandas DataFrame으로 전달됩니다. 여기서 각 행은 별도의 평가 예시(인스턴스라고 함)를 나타내며 각 열은 측정항목 입력 매개변수를 나타냅니다. 각 측정항목에서 예상하는 입력은 측정항목을 참조하세요. Google에서는 다양한 평가 태스크를 위해 평가 데이터 세트를 빌드하기 위한 몇 가지 예시를 제공합니다.
요약 평가
다음 측정항목을 사용하여 점별 요약을 위한 데이터 세트를 구성하세요.
summarization_qualitygroundednessfulfillmentsummarization_helpfulnesssummarization_verbosity
필수 측정항목 입력 매개변수를 고려하여 평가 데이터 세트에 다음 열을 포함해야 합니다.
instructioncontextresponse
이 예시에는 2개의 요약 인스턴스가 있습니다. 요약 태스크 평가에 필요한 instruction 및 context 필드를 입력으로 구성합니다.
instructions = [
# example 1
"Summarize the text in one sentence.",
# example 2
"Summarize the text such that a five-year-old can understand.",
]
contexts = [
# example 1
"""As part of a comprehensive initiative to tackle urban congestion and foster
sustainable urban living, a major city has revealed ambitious plans for an
extensive overhaul of its public transportation system. The project aims not
only to improve the efficiency and reliability of public transit but also to
reduce the city\'s carbon footprint and promote eco-friendly commuting options.
City officials anticipate that this strategic investment will enhance
accessibility for residents and visitors alike, ushering in a new era of
efficient, environmentally conscious urban transportation.""",
# example 2
"""A team of archaeologists has unearthed ancient artifacts shedding light on a
previously unknown civilization. The findings challenge existing historical
narratives and provide valuable insights into human history.""",
]
LLM 응답(요약)이 준비되었고 BYOP(Bring Your Own Prediction) 평가를 수행하려면 다음과 같이 응답 입력을 생성하면 됩니다.
responses = [
# example 1
"A major city is revamping its public transportation system to fight congestion, reduce emissions, and make getting around greener and easier.",
# example 2
"Some people who dig for old things found some very special tools and objects that tell us about people who lived a long, long time ago! What they found is like a new puzzle piece that helps us understand how people used to live.",
]
이러한 입력으로 평가 데이터 세트 및 EvalTask를 구성할 수 있습니다.
eval_dataset = pd.DataFrame(
{
"instruction": instructions,
"context": contexts,
"response": responses,
}
)
eval_task = EvalTask(
dataset=eval_dataset,
metrics=[
'summarization_quality',
'groundedness',
'fulfillment',
'summarization_helpfulness',
'summarization_verbosity'
],
experiment=EXPERIMENT_NAME
)
일반 텍스트 생성 평가
coherence, fluency, safety와 같은 일부 모델 기반 측정항목은 품질 평가에 모델 응답 자체만 필요합니다.
eval_dataset = pd.DataFrame({
"response": ["""The old lighthouse, perched precariously on the windswept cliff,
had borne witness to countless storms. Its once-bright beam, now dimmed by time
and the relentless sea spray, still flickered with stubborn defiance."""]
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["coherence", "fluency", "safety"],
experiment=EXPERIMENT_NAME
)
계산 기반 평가
일치검색, Bleu, Rouge와 같은 계산 기반 측정항목은 응답을 참조와 비교하므로 평가 데이터 세트에 응답 필드와 참조 필드가 모두 필요합니다.
eval_dataset = pd.DataFrame({
"response": ["The Roman Senate was filled with exuberance due to Pompey's defeat in Asia."],
"reference": ["The Roman Senate was filled with exuberance due to successes against Catiline."],
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["exact_match", "bleu", "rouge"],
experiment=EXPERIMENT_NAME
)
도구 사용 평가
도구 사용 평가의 경우 평가 데이터 세트에 응답과 참조만 포함하면 됩니다.
eval_dataset = pd.DataFrame({
"response": ["""{
"content": "",
"tool_calls":[{
"name":"get_movie_info",
"arguments": {"movie":"Mission Impossible", "time": "today 7:30PM"}
}]
}"""],
"reference": ["""{
"content": "",
"tool_calls":[{
"name":"book_tickets",
"arguments":{"movie":"Mission Impossible", "time": "today 7:30PM"}
}]
}"""],
})
eval_task = EvalTask(
dataset=eval_dataset,
metrics=["tool_call_valid", "tool_name_match", "tool_parameter_key_match",
"tool_parameter_kv_match"],
experiment=EXPERIMENT_NAME
)
측정항목 번들
측정항목 번들은 일반적으로 연결되는 측정항목을 결합하여 평가 프로세스를 간소화합니다. 측정항목은 다음 4가지 번들로 분류됩니다.
- 평가 작업: 요약, 질의 응답, 텍스트 생성
- 평가 관점: 유사성, 안전성, 품질
- 입력 일관성: 동일한 번들의 모든 측정항목이 동일한 데이터 세트 입력을 사용합니다.
- 평가 패러다임: 점별과 쌍별 비교
온라인 평가 서비스에서 이러한 측정항목 번들을 사용하여 맞춤형 평가 워크플로를 최적화할 수 있습니다.
다음 테이블에 사용 가능한 측정항목 번들에 대한 세부정보가 나와 있습니다.
| 측정항목 번들 이름 | 측정항목 이름 | 사용자 입력 |
|---|---|---|
text_generation_similarity |
exact_matchbleurouge |
예측 참조 |
tool_call_quality |
tool_call_validtool_name_matchtool_parameter_key_matchtool_parameter_kv_match |
예측 참조 |
text_generation_quality |
coherencefluency |
예측 |
text_generation_instruction_following |
fulfillment |
예측 참조 |
text_generation_safety |
safety |
예측 |
text_generation_factuality |
groundedness |
예측 컨텍스트 |
summarization_pointwise_reference_free |
summarization_qualitysummarization_helpfulnesssummarization_verbosity |
예측 컨텍스트 안내 |
summary_pairwise_reference_free |
pairwise_summarization_quality |
예측 컨텍스트 안내 |
qa_pointwise_reference_free |
question_answering_qualityquestion_answering_relevancequestion_answering_helpfulness |
예측 컨텍스트 안내 |
qa_pointwise_reference_based |
question_answering_correctness |
예측 컨텍스트 안내 참조 |
qa_pairwise_reference_free |
pairwise_question_answering_quality |
예측 컨텍스트 안내 |
평가 결과 보기
평가 태스크를 정의한 후 다음과 같이 태스크를 실행하여 평가 결과를 가져옵니다.
eval_result: EvalResult = eval_task.evaluate(
model=MODEL,
prompt_template=PROMPT_TEMPLATE
)
EvalResult 클래스는 요약 측정항목과 평가 데이터 세트 인스턴스 및 이에 상응하는 인스턴스별 측정항목이 있는 측정항목 테이블을 포함하는 평가 실행 결과를 나타냅니다. 클래스를 다음과 같이 정의하세요.
@dataclasses.dataclass
class EvalResult:
"""Evaluation result.
Attributes:
summary_metrics: the summary evaluation metrics for an evaluation run.
metrics_table: a table containing eval inputs, ground truth, and
metrics per row.
"""
summary_metrics: Dict[str, float]
metrics_table: Optional[pd.DataFrame] = None
도우미 함수를 사용하면 Colab 노트북에 평가 결과가 표시될 수 있습니다.
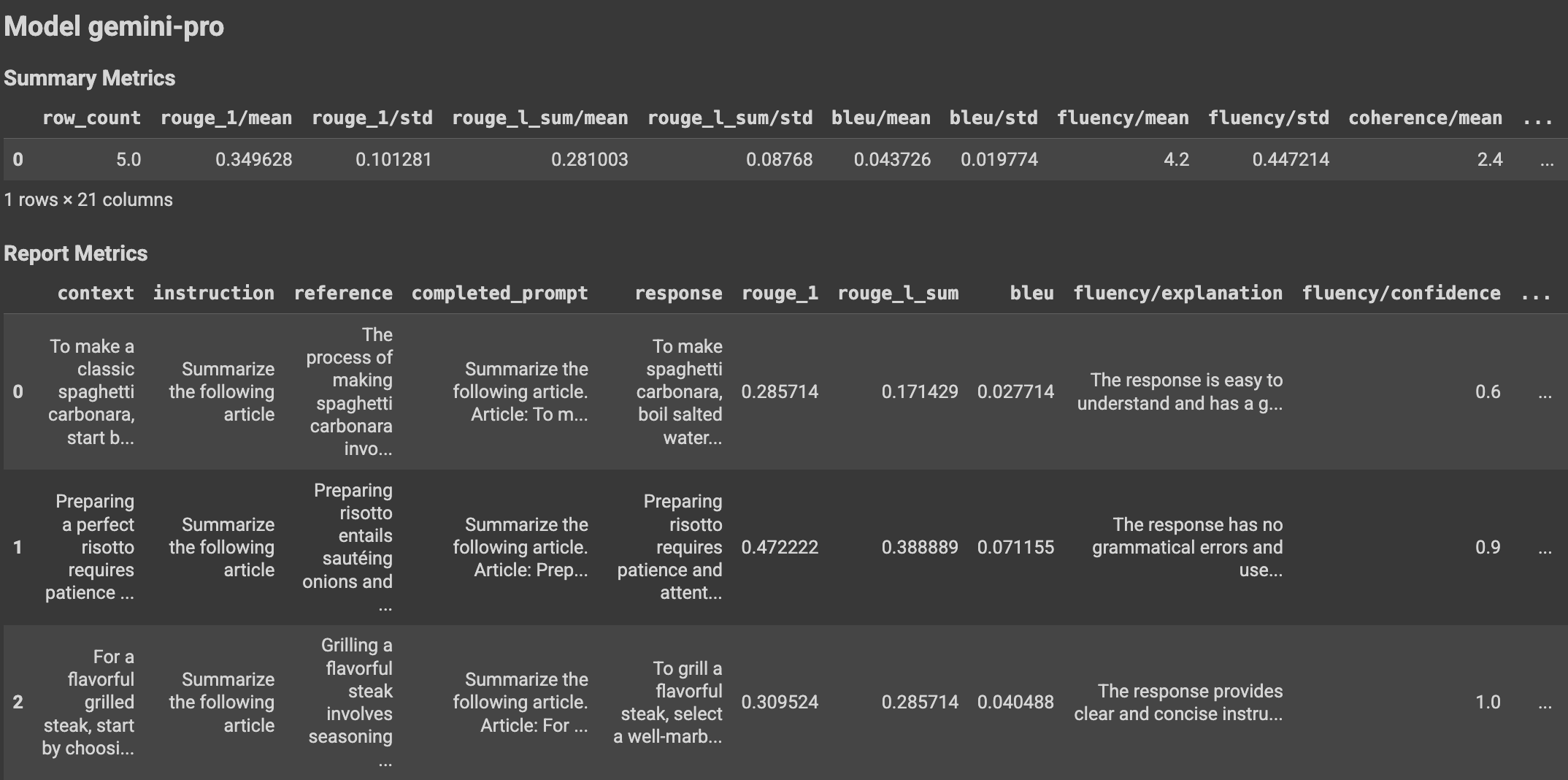
시각화
방사형 차트나 막대 그래프에 요약 측정항목을 표시하여 다양한 평가 실행의 결과들을 시각화하고 비교할 수 있습니다. 이 시각화는 다양한 모델 및 다양한 프롬프트 템플릿을 평가하는 데 유용합니다.
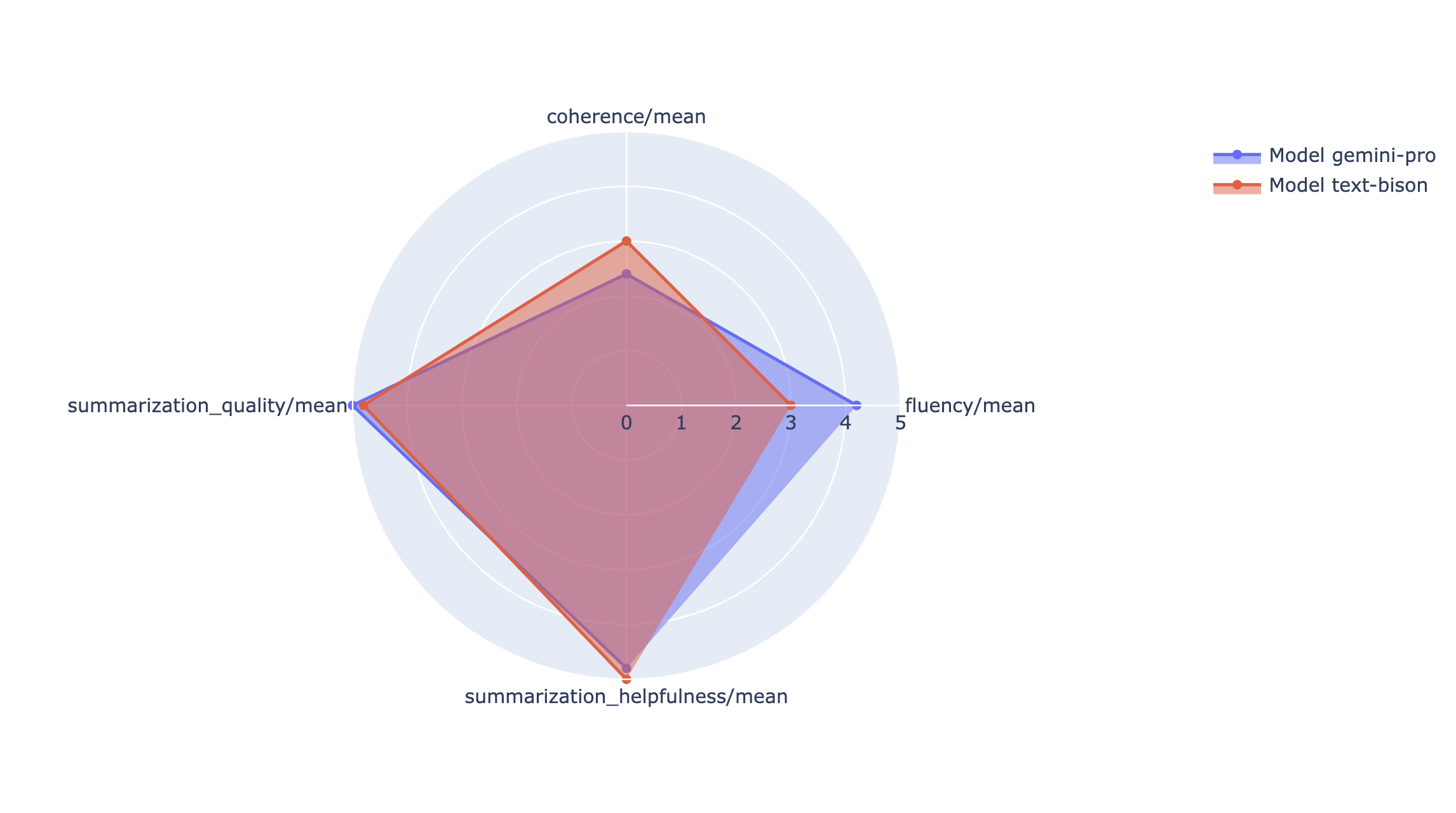
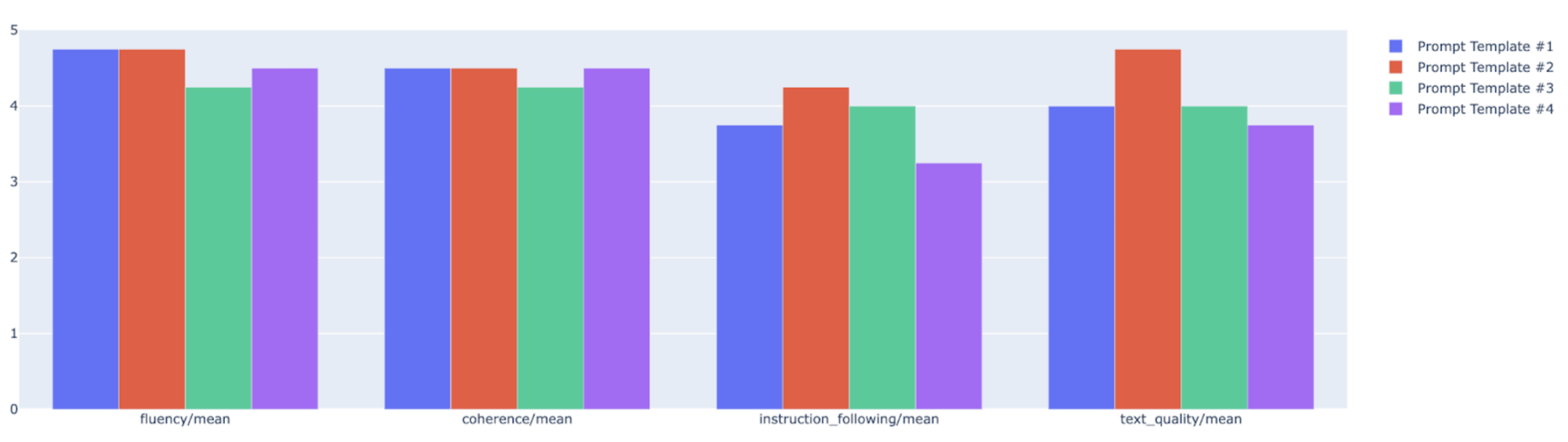
Rapid Evaluation API
Rapid Evaluation API에 대한 자세한 내용은 Rapid Evaluation API를 참조하세요.
서비스 계정 이해
서비스 계정은 온라인 평가 서비스에서 모델 기반 평가 측정항목에 대한 온라인 예측 서비스로부터 예측을 가져오는 데 사용됩니다. 이 서비스 계정은 온라인 평가 서비스에 대한 첫 번째 요청 시 자동으로 프로비저닝됩니다.
| 이름 | 설명 | 이메일 주소 | 역할 |
|---|---|---|---|
| Vertex AI Rapid Eval 서비스 에이전트 | 모델 기반 평가를 위한 예측을 가져오는 데 사용되는 서비스 계정입니다. | service-PROJECT_NUMBER@gcp-sa-ENV-vertex-eval.iam.gserviceaccount.com |
roles/aiplatform.rapidevalServiceAgent |
Rapid Eval 서비스 에이전트와 관련된 권한은 다음과 같습니다.
| 역할 | 권한 |
|---|---|
| Vertex AI Rapid Eval 서비스 에이전트(roles/aiplatform.rapidevalServiceAgent) | aiplatform.endpoints.predict |
다음 단계
- 평가 예시 노트북 사용해 보기
- 생성형 AI 평가 알아보기
- AutoSxS 파이프라인을 사용하는 모델 기반 쌍 평가 알아보기
- 계산 기반 평가 파이프라인 알아보기
- 파운데이션 모델 조정 방법 알아보기