Halaman ini menjelaskan apa itu Vertex AI RAG Engine dan cara kerjanya.
| Deskripsi | Konsol |
|---|---|
| Untuk mempelajari cara menggunakan Vertex AI SDK guna menjalankan tugas Vertex AI RAG Engine, lihat Mulai cepat RAG untuk Python. |
Ringkasan
Vertex AI RAG Engine, komponen Vertex AI Platform, memfasilitasi Retrieval-Augmented Generation (RAG). Vertex AI RAG Engine juga merupakan framework data untuk mengembangkan aplikasi model bahasa besar (LLM) yang dilengkapi konteks. Peningkatan konteks terjadi saat Anda menerapkan LLM ke data Anda. Bagian ini menerapkan retrieval-augmented generation (RAG).
Masalah umum pada LLM adalah bahwa LLM tidak memahami pengetahuan pribadi, yaitu data organisasi Anda. Dengan Vertex AI RAG Engine, Anda dapat memperkaya konteks LLM dengan informasi pribadi tambahan, karena model dapat mengurangi halusinasi dan menjawab pertanyaan dengan lebih akurat.
Dengan menggabungkan sumber pengetahuan tambahan dengan pengetahuan yang sudah dimiliki LLM, konteks yang lebih baik akan diberikan. Konteks yang ditingkatkan bersama dengan kueri akan meningkatkan kualitas respons LLM.
Gambar berikut mengilustrasikan konsep utama untuk memahami Vertex AI RAG Engine.
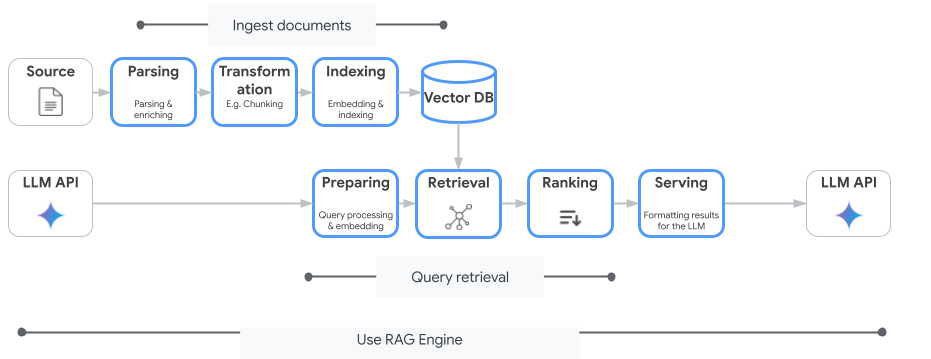
Konsep ini tercantum dalam urutan proses retrieval-augmented generation (RAG).
Penyerapan data: Memasukkan data dari berbagai sumber data. Misalnya, file lokal, Cloud Storage, dan Google Drive.
Transformasi data: Konversi data dalam persiapan pengindeksan. Misalnya, data dibagi menjadi beberapa bagian.
Embedding: Representasi numerik kata atau bagian teks. Angka ini menangkap makna semantik dan konteks teks. Kata atau teks yang serupa atau terkait cenderung memiliki embedding yang serupa, yang berarti posisinya lebih berdekatan dalam ruang vektor berdimensi tinggi.
Pengindeksan data: Vertex AI RAG Engine membuat indeks yang disebut korpus. Indeks menyusun pusat informasi sehingga dioptimalkan untuk penelusuran. Misalnya, indeks ini seperti daftar isi mendetail untuk buku referensi yang sangat besar.
Pengambilan (Retrieval): Saat pengguna mengajukan pertanyaan atau memberikan perintah, komponen pengambilan di Vertex AI RAG Engine akan menelusuri pusat informasinya untuk menemukan informasi yang relevan dengan kueri.
Generasi: Informasi yang diambil menjadi konteks yang ditambahkan ke kueri pengguna asli sebagai panduan bagi model AI generatif untuk menghasilkan respons yang berbasis fakta dan relevan.
Region yang didukung
Mesin RAG Vertex AI didukung di wilayah berikut:
| Wilayah | Lokasi | Deskripsi | Tahap peluncuran |
|---|---|---|---|
us-central1 |
Iowa | Versi v1 dan v1beta1 didukung. |
Daftar yang diizinkan |
us-east4 |
Virginia | Versi v1 dan v1beta1 didukung. |
GA |
europe-west3 |
Frankfurt, Jerman | Versi v1 dan v1beta1 didukung. |
GA |
europe-west4 |
Eemshaven, Belanda | Versi v1 dan v1beta1 didukung. |
GA |
us-central1diubah menjadiAllowlist. Jika Anda ingin bereksperimen dengan Vertex AI RAG Engine, coba region lain. Jika Anda berencana untuk mengaktifkan traffic produksi keus-central1, hubungivertex-ai-rag-engine-support@google.com.
Menghapus Vertex AI RAG Engine
Contoh kode berikut menunjukkan cara menghapus Vertex AI RAG Engine untuk konsol Google Cloud , Python, dan REST:
Parameter API Versi 1 (v1) dan contoh kode.
Parameter API v1beta1 dan contoh kode.
Kirim masukan
Untuk memulai percakapan dengan dukungan Google, buka grup dukungan Vertex AI RAG Engine.
Untuk mengirim email, gunakan alamat email
vertex-ai-rag-engine-support@google.com.
Langkah berikutnya
- Untuk mempelajari cara menggunakan Vertex AI SDK guna menjalankan tugas Vertex AI RAG Engine, lihat Mulai cepat RAG untuk Python.
- Untuk mempelajari perujukan, lihat Ringkasan perujukan.
- Untuk mempelajari lebih lanjut respons dari RAG, lihat Output Pengambilan dan Pembuatan Mesin RAG Vertex AI.
- Untuk mempelajari arsitektur RAG: