Mulai 29 April 2025, model Gemini 1.5 Pro dan Gemini 1.5 Flash tidak tersedia di project yang belum pernah menggunakan model ini, termasuk project baru. Untuk mengetahui detailnya, lihat Versi dan siklus proses model.
Vertex AI RAG Engine, komponen Platform Vertex AI, memfasilitasi Retrieval-Augmented Generation (RAG).
Vertex AI RAG Engine juga merupakan framework data untuk mengembangkan aplikasi model bahasa besar (LLM) yang dilengkapi konteks. Peningkatan konteks
terjadi saat Anda menerapkan LLM ke data Anda. Ini menerapkan retrieval-augmented generation (RAG).
Masalah umum pada LLM adalah bahwa LLM tidak memahami pengetahuan pribadi, yaitu data organisasi Anda. Dengan Vertex AI RAG Engine, Anda dapat memperkaya konteks LLM dengan informasi pribadi tambahan, karena model dapat mengurangi halusinasi dan menjawab pertanyaan dengan lebih akurat.
Dengan menggabungkan sumber pengetahuan tambahan dengan pengetahuan yang sudah dimiliki LLM, konteks yang lebih baik akan diberikan. Konteks yang ditingkatkan bersama dengan kueri
meningkatkan kualitas respons LLM.
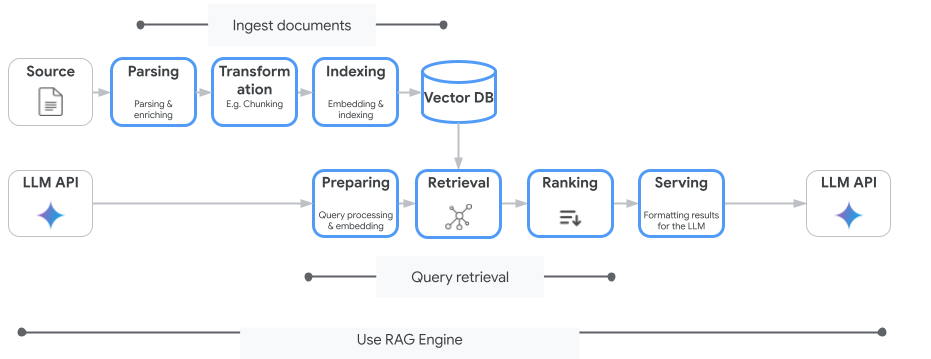
Gambar berikut mengilustrasikan konsep utama untuk memahami
Vertex AI RAG Engine.
Konsep ini tercantum dalam urutan proses retrieval-augmented generation
(RAG).
Penyerapan data: Memasukkan data dari berbagai sumber data. Misalnya,
file lokal, Cloud Storage, dan Google Drive.
Transformasi data:
Konversi data dalam persiapan pengindeksan. Misalnya, data dibagi menjadi beberapa bagian.
Embedding: Representasi
numerik kata atau potongan teks. Angka ini menangkap makna semantik dan konteks teks. Kata atau teks yang serupa atau terkait
cenderung memiliki embedding yang serupa, yang berarti posisinya lebih berdekatan dalam
ruang vektor berdimensi tinggi.
Pengindeksan data: Vertex AI RAG Engine membuat indeks yang disebut korpus.
Indeks menyusun pusat informasi sehingga dioptimalkan untuk penelusuran. Misalnya, indeks ini seperti daftar isi mendetail untuk buku referensi yang sangat besar.
Pengambilan (Retrieval): Saat pengguna mengajukan pertanyaan atau memberikan perintah, komponen pengambilan
di Vertex AI RAG Engine akan menelusuri basis pengetahuannya untuk menemukan informasi yang relevan dengan kueri.
Generasi: Informasi yang diambil menjadi konteks yang ditambahkan ke kueri pengguna asli sebagai panduan bagi model AI generatif untuk menghasilkan respons yang berbasis fakta dan relevan.
Region yang didukung
Mesin RAG Vertex AI didukung di wilayah berikut:
Wilayah
Lokasi
Deskripsi
Tahap peluncuran
us-central1
Iowa
Versi v1 dan v1beta1 didukung.
Daftar yang diizinkan
us-east4
Virginia
Versi v1 dan v1beta1 didukung.
GA
europe-west3
Frankfurt, Jerman
Versi v1 dan v1beta1 didukung.
GA
europe-west4
Eemshaven, Belanda
Versi v1 dan v1beta1 didukung.
GA
us-central1 diubah menjadi Allowlist. Jika Anda ingin bereksperimen dengan
Vertex AI RAG Engine, coba region lain. Jika Anda berencana untuk mengaktifkan traffic produksi ke us-central1, hubungi vertex-ai-rag-engine-support@google.com.
[[["Mudah dipahami","easyToUnderstand","thumb-up"],["Memecahkan masalah saya","solvedMyProblem","thumb-up"],["Lainnya","otherUp","thumb-up"]],[["Sulit dipahami","hardToUnderstand","thumb-down"],["Informasi atau kode contoh salah","incorrectInformationOrSampleCode","thumb-down"],["Informasi/contoh yang saya butuhkan tidak ada","missingTheInformationSamplesINeed","thumb-down"],["Masalah terjemahan","translationIssue","thumb-down"],["Lainnya","otherDown","thumb-down"]],["Terakhir diperbarui pada 2025-09-04 UTC."],[],[],null,["# Vertex AI RAG Engine overview\n\n| The [VPC-SC security controls](/vertex-ai/generative-ai/docs/security-controls) and\n| CMEK are supported by Vertex AI RAG Engine. Data residency and AXT security controls aren't\n| supported.\n| You must be added to the allowlist to access\n| Vertex AI RAG Engine in `us-central1`. For users\n| with existing projects, there is no impact. For users with new projects, you\n| can try other regions, or contact\n| `vertex-ai-rag-engine-support@google.com` to onboard to\n| `us-central1`.\n\nThis page describes what Vertex AI RAG Engine is and how it\nworks.\n\nOverview\n--------\n\nVertex AI RAG Engine, a component of the Vertex AI\nPlatform, facilitates Retrieval-Augmented Generation (RAG).\nVertex AI RAG Engine is also a data framework for developing\ncontext-augmented large language model (LLM) applications. Context augmentation\noccurs when you apply an LLM to your data. This implements retrieval-augmented\ngeneration (RAG).\n\nA common problem with LLMs is that they don't understand private knowledge, that\nis, your organization's data. With Vertex AI RAG Engine, you can\nenrich the LLM context with additional private information, because the model\ncan reduce hallucination and answer questions more accurately.\n\nBy combining additional knowledge sources with the existing knowledge that LLMs\nhave, a better context is provided. The improved context along with the query\nenhances the quality of the LLM's response.\n\nThe following image illustrates the key concepts to understanding\nVertex AI RAG Engine.\n\nThese concepts are listed in the order of the retrieval-augmented generation\n(RAG) process.\n\n1. **Data ingestion**: Intake data from different data sources. For example,\n local files, Cloud Storage, and Google Drive.\n\n2. [**Data transformation**](/vertex-ai/generative-ai/docs/fine-tune-rag-transformations):\n Conversion of the data in preparation for indexing. For example, data is\n split into chunks.\n\n3. [**Embedding**](/vertex-ai/generative-ai/docs/embeddings/get-text-embeddings): Numerical\n representations of words or pieces of text. These numbers capture the\n semantic meaning and context of the text. Similar or related words or text\n tend to have similar embeddings, which means they are closer together in the\n high-dimensional vector space.\n\n4. **Data indexing** : Vertex AI RAG Engine creates an index called a [corpus](/vertex-ai/generative-ai/docs/manage-your-rag-corpus#corpus-management).\n The index structures the knowledge base so it's optimized for searching. For\n example, the index is like a detailed table of contents for a massive\n reference book.\n\n5. **Retrieval**: When a user asks a question or provides a prompt, the retrieval\n component in Vertex AI RAG Engine searches through its knowledge\n base to find information that is relevant to the query.\n\n6. **Generation** : The retrieved information becomes the context added to the\n original user query as a guide for the generative AI model to generate\n factually [grounded](/vertex-ai/generative-ai/docs/grounding/overview) and relevant responses.\n\nSupported regions\n-----------------\n\nVertex AI RAG Engine is supported in the following regions:\n\n- `us-central1` is changed to `Allowlist`. If you'd like to experiment with Vertex AI RAG Engine, try other regions. If you plan to onboard your production traffic to `us-central1`, contact `vertex-ai-rag-engine-support@google.com`.\n\nSubmit feedback\n---------------\n\nTo chat with Google support, go to the [Vertex AI RAG Engine\nsupport\ngroup](https://groups.google.com/a/google.com/g/vertex-ai-rag-engine-support).\n\nTo send an email, use the email address\n`vertex-ai-rag-engine-support@google.com`.\n\nWhat's next\n-----------\n\n- To learn how to use the Vertex AI SDK to run Vertex AI RAG Engine tasks, see [RAG quickstart for\n Python](/vertex-ai/generative-ai/docs/rag-quickstart).\n- To learn about grounding, see [Grounding\n overview](/vertex-ai/generative-ai/docs/grounding/overview).\n- To learn more about the responses from RAG, see [Retrieval and Generation Output of Vertex AI RAG Engine](/vertex-ai/generative-ai/docs/model-reference/rag-output-explained).\n- To learn about the RAG architecture:\n - [Infrastructure for a RAG-capable generative AI application using Vertex AI and Vector Search](/architecture/gen-ai-rag-vertex-ai-vector-search)\n - [Infrastructure for a RAG-capable generative AI application using Vertex AI and AlloyDB for PostgreSQL](/architecture/rag-capable-gen-ai-app-using-vertex-ai)."]]