Este guia para iniciantes apresenta as principais tecnologias da IA generativa e explica como eles se complementam para potencializar chatbots e aplicativos. A IA generativa, também conhecida como genAI ou IA generativa, é um campo de machine learning (ML) que desenvolve e usa modelos de ML para gerar conteúdo novo.
Os modelos de IA generativa são frequentemente chamados de modelos de linguagem grandes (LLMs) devido ao tamanho grande e a capacidade de entender e gerar linguagem natural. No entanto, dependendo dos dados com os quais os modelos são treinados, eles podem entender e gerar conteúdo em diversas modalidades, incluindo texto, imagens, vídeos e áudio. Modelos que funcionam com várias modalidades de dados chamados modelos multimodais.
O Google oferece a família de modelos de IA generativa do Gemini projetada para casos de uso multimodais, capaz de processar informações de várias modalidades, incluindo imagens, vídeos e texto.
Geração de conteúdo
Para que os modelos de IA generativa gerem conteúdo útil em aplicativos reais, elas precisam ter os seguintes recursos:
Aprenda a realizar novas tarefas:
Os modelos de IA generativa são projetados para realizar tarefas gerais. Se você quiser um modelo para executar tarefas exclusivas do seu caso de uso, é preciso personalizar o modelo. Na Vertex AI, é possível personalizar seu modelo por meio do ajuste de modelos.
Acesso a informações externas:
Os modelos de IA generativa são treinados com grandes quantidades de dados. No entanto, para que esses modelos sejam úteis, eles precisam conseguir acessar informações fora dos dados de treinamento. Por exemplo, se você quiser criar um chatbot de atendimento ao cliente com tecnologia de IA generativa, o modelo precisa ter acesso às informações sobre os produtos e serviços que você oferta. Na Vertex AI, você usa os recursos de chamada função e embasamento para ajudar o modelo a acessar informações externas.
Bloquear conteúdo nocivo:
Os modelos de IA generativa podem gerar resultados inesperados, incluindo texto ofensivo ou insensível. Para manter a segurança e evitar o uso indevido, os modelos precisam de filtros de segurança para bloquear comandos e respostas que sejam considerados potencialmente nocivos. A Vertex AI tem recursos de segurança integrados que promovem o uso responsável dos nossos serviços de IA generativa.
O diagrama a seguir mostra como esses diferentes recursos funcionam em parceria para gerar o conteúdo que você quer:
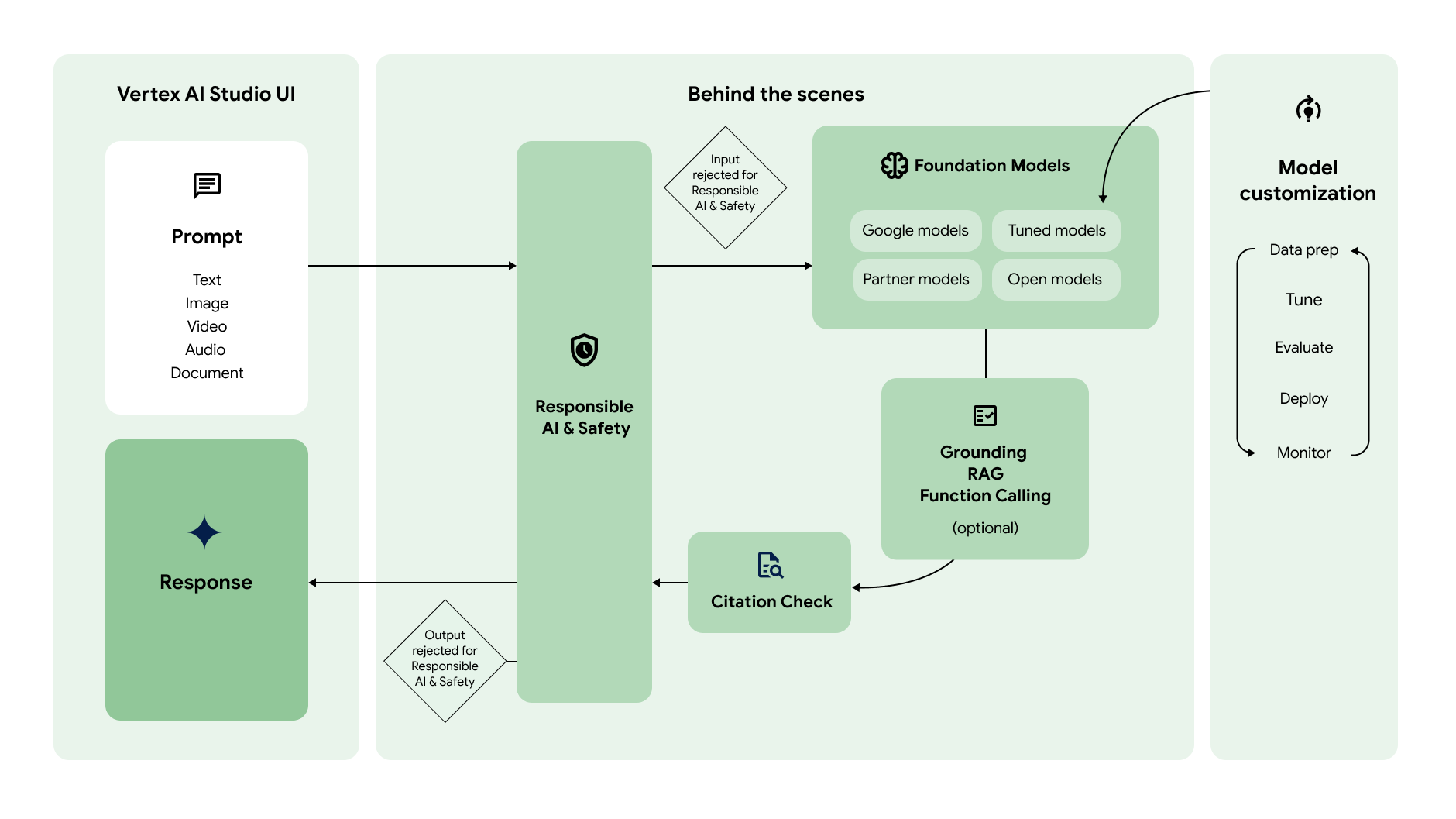
Comando
|
|
O fluxo de trabalho da IA generativa geralmente começa com solicitações. Um prompt é uma solicitação de linguagem natural enviada a um modelo de IA generativa para receber uma resposta. Dependendo do modelo, um comando pode conter texto, imagens, vídeos, áudio, documentos e outras modalidades, ou até mesmo várias modalidades (multimodais). Criar um comando para receber a resposta desejada do modelo é uma prática chamada design de comandos. Embora o design de prompts seja um processo de tentativa e erro, há princípios e estratégias que podem ser usados para fazer com que o modelo se comporte da maneira desejada. O Vertex AI Studio oferece uma ferramenta de gestão de comandos para ajudar você a gerenciá-los. |
Modelos de fundação
|
|
Os comandos são enviados a um modelo de IA generativa para geração de respostas. A Vertex AI tem vários modelos de fundação de IA generativa acessíveis por uma API, incluindo estes:
Os modelos diferem em tamanho, modalidade e custo. Conheça os modelos do Google, bem como os de parceiros do Google, no Model Garden. |
Personalização de modelos
|
|
É possível personalizar o comportamento padrão dos modelos básicos do Google para que eles gerem de maneira consistente os resultados desejados sem usar solicitações complexas. Esse processo de personalização é chamado de ajuste do modelo. O ajuste de modelo ajuda a reduzir o custo e a latência das solicitações, o que simplifica as solicitações. A Vertex AI também oferece ferramentas de avaliação de modelos para ajudar você a avaliar o desempenho do modelo ajustado. Depois que o modelo ajustado estiver pronto para produção, será possível implantá-lo em um endpoint e monitorar o desempenho como em fluxos de trabalho MLOps padrão. |
Acessar informações externas
|
|
A Vertex AI oferece várias maneiras de fornecer o acesso do modelo a APIs externas e informações em tempo real.
|
Verificação da citação
|
|
Depois que a resposta é gerada, a Vertex AI verifica se as citações precisam ser incluídas nela. Se uma parte significativa do texto na resposta vier de uma fonte específica, essa fonte será adicionada aos metadados de citação na resposta. |
IA e segurança responsáveis
|
|
A última camada de verificações que a solicitação e a resposta passam antes de serem retornadas são os filtros de segurança. A Vertex AI verifica a solicitação e a resposta para saber quanto ela pertence a uma categoria de segurança. Se o limite for excedido para uma ou mais categorias, a resposta será bloqueada e a Vertex AI vai retornar uma resposta alternativa. |
Resposta
|
|
Se a solicitação e a resposta forem aprovadas nas verificações do filtro de segurança, a resposta será retornada. Normalmente, a resposta é retornada de uma só vez. No entanto, com a Vertex AI, você também pode receber respostas progressivamente à medida que são geradas, ativando o streaming. |
Primeiros passos
Confira um destes guias de início rápido para começar a usar a IA generativa na Vertex AI:
- Gerar texto usando a API Gemini da Vertex AI: use o SDK para enviar solicitações à API Gemini da Vertex AI
- Envie comandos para o Gemini usando a Galeria de comandos do Vertex AI Studio: teste comandos sem precisar de configuração
- Gerar uma imagem e verificar a marca-d'água dela usando o Imagen: Crie uma imagem com marca-d'água usando o Imagen na Vertex AI