Il sistema di risposta a domande visive (VQA) ti consente di fornire un'immagine al modello e porre una domanda sui contenuti dell'immagine. In risposta alla tua domanda ricevi una o più risposte in linguaggio naturale.
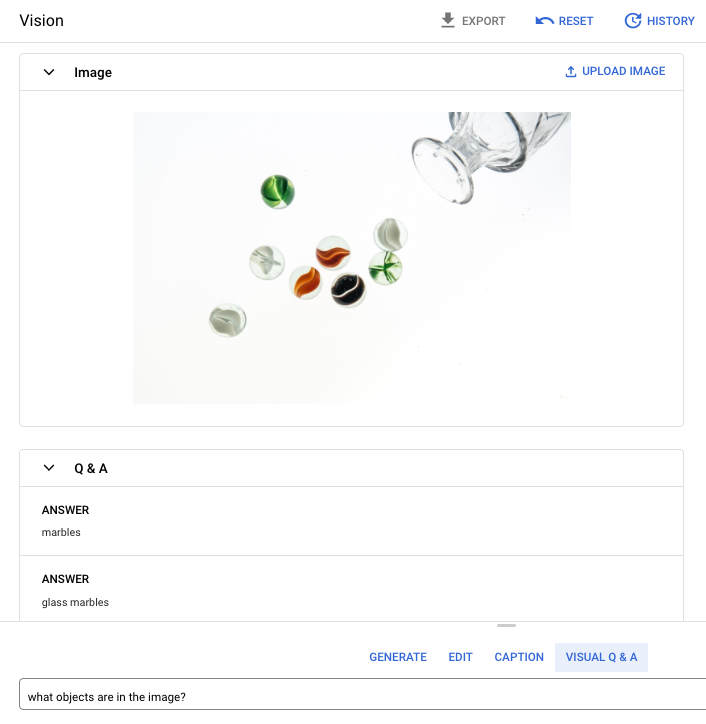
Domanda del prompt: Quali oggetti sono presenti nell'immagine?
Risposta 1: biglie
Risposta 2: biglie di vetro
Lingue supportate
VQA è disponibile nelle seguenti lingue:
- Inglese (en)
Prestazioni e limitazioni
Quando utilizzi questo modello, si applicano i seguenti limiti:
| Limiti | Valore |
|---|---|
| Numero massimo di richieste API (formato breve) al minuto per progetto | 500 |
| Numero massimo di token restituiti nella risposta (formato breve) | 64 token |
| Numero massimo di token accettati nella richiesta (solo VQA in formato breve) | 80 token |
Quando utilizzi questo modello, si applicano le seguenti stime di latenza del servizio. Questi valori sono indicativi e non rappresentano una promessa di servizio:
| Latenza | Valore |
|---|---|
| Richieste API (formato breve) | 1,5 secondi |
Località
Una località è una regione che puoi specificare in una richiesta per controllare dove vengono archiviati i dati at-rest. Per un elenco delle regioni disponibili, consulta Località dell'AI generativa su Vertex AI.
Filtro di sicurezza dell'AI responsabile
Il modello di funzionalità di didascalie delle immagini e di question answering per immagini (VQA) non supporta filtri di sicurezza configurabili dall'utente. Tuttavia, il filtraggio di sicurezza di Imagen complessivo avviene sui seguenti dati:
- Input utente
- Output del modello
Di conseguenza, l'output potrebbe differire da quello di esempio se Imagen applica questi filtri di sicurezza. Considera i seguenti esempi.
Input filtrato
Se l'input viene filtrato, la risposta è simile alla seguente:
{
"error": {
"code": 400,
"message": "Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394",
"status": "INVALID_ARGUMENT",
"details": [
{
"@type": "type.googleapis.com/google.rpc.DebugInfo",
"detail": "[ORIGINAL ERROR] generic::invalid_argument: Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394 [google.rpc.error_details_ext] { message: \"Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394\" }"
}
]
}
}
Output filtrato
Se il numero di risposte restituite è inferiore al conteggio del campione specificato,
significa che le risposte mancanti vengono filtrate dall'AI responsabile. Ad esempio,
di seguito è riportata una risposta a una richiesta con "sampleCount": 2, ma una delle
risposte viene filtrata:
{
"predictions": [
"cappuccino"
]
}
Se tutto l'output viene filtrato, la risposta è un oggetto vuoto simile al seguente:
{}
Utilizzare VQA su un'immagine (risposte brevi)
Utilizza i seguenti esempi per fare una domanda e ricevere una risposta su un'immagine.
REST
Per saperne di più sulle richieste del modello imagetext, consulta il
riferimento API del modello imagetext.
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- PROJECT_ID: il tuo Google Cloud ID progetto.
- LOCATION: la regione del progetto. Ad esempio,
us-central1,europe-west2oasia-northeast3. Per un elenco delle regioni disponibili, consulta Località dell'AI generativa su Vertex AI. - VQA_PROMPT: La domanda a cui vuoi ricevere una risposta in merito alla tua immagine.
- Di che colore è questa scarpa?
- Che tipo di maniche ha la maglietta?
- B64_IMAGE: L'immagine per cui ottenere i sottotitoli codificati. L'immagine deve essere specificata come stringa di byte con codifica base64. Dimensioni massime: 10 MB.
- RESPONSE_COUNT: il numero di risposte che vuoi generare. Valori interi accettati: 1-3.
Metodo HTTP e URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict
Corpo JSON della richiesta:
{
"instances": [
{
"prompt": "VQA_PROMPT",
"image": {
"bytesBase64Encoded": "B64_IMAGE"
}
}
],
"parameters": {
"sampleCount": RESPONSE_COUNT
}
}
Per inviare la richiesta, scegli una di queste opzioni:
curl
Salva il corpo della richiesta in un file denominato request.json,
ed esegui questo comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict"
PowerShell
Salva il corpo della richiesta in un file denominato request.json,
ed esegui questo comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict" | Select-Object -Expand Content
"sampleCount": 2 e "prompt": "What is this?". La risposta restituisce
due stringhe di previsione.
{
"predictions": [
"cappuccino",
"coffee"
]
}
Python
Prima di provare questo esempio, segui le istruzioni di configurazione di Python nella guida rapida di Vertex AI per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API Vertex AI Python.
Per eseguire l'autenticazione in Vertex AI, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
In questo esempio utilizzi il metodo load_from_file per fare riferimento a un file locale come Image di base per ottenere informazioni. Dopo aver specificato l'immagine di base, utilizza il metodo ask_question su ImageTextModel e stampa le risposte.
Node.js
Prima di provare questo esempio, segui le istruzioni di configurazione di Node.js nella guida rapida di Vertex AI per l'utilizzo delle librerie client. Per saperne di più, consulta la documentazione di riferimento dell'API Vertex AI Node.js.
Per eseguire l'autenticazione in Vertex AI, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.
In questo esempio, chiami il metodopredict su un PredictionServiceClient.
Il servizio restituisce le risposte alla domanda fornita.
Utilizzare i parametri per VQA
Quando ricevi risposte VQA, puoi impostare diversi parametri a seconda del caso d'uso.
Numero risultati
Utilizza il parametro del numero di risultati per limitare la quantità di risposte restituite
per ogni richiesta che invii. Per saperne di più, consulta il riferimento API del modello imagetext (VQA).
Numero seed
Un numero che aggiungi a una richiesta per rendere deterministiche le risposte generate. L'aggiunta
di un numero seed alla richiesta è un modo per assicurarti di ottenere la stessa previsione
(risposte) ogni volta. Tuttavia, le risposte non
vengono necessariamente restituite nello stesso ordine. Per saperne di più, consulta il
riferimento API del modello imagetext (VQA).
Passaggi successivi
Leggi gli articoli su Imagen e altri prodotti di AI generativa su Vertex AI:
- Guida per gli sviluppatori per iniziare a utilizzare Imagen 3 su Vertex AI
- Nuovi modelli e strumenti di media generativi, creati con e per i creator
- Novità di Gemini: Gem personalizzati e generazione di immagini migliorata con Imagen 3
- Google DeepMind: Imagen 3, il nostro modello di conversione da testo a immagine di altissima qualità