Filtri di sicurezza configurabili
Punteggio di attendibilità e gravità dell'attributo di sicurezza
I contenuti elaborati tramite l'API Vertex AI PaLM vengono valutati in base a un elenco di attributi relativi alla sicurezza, che includono "categorie dannose" e ad argomenti che possono essere considerati sensibili.
A ogni attributo di sicurezza viene assegnato un punteggio di affidabilità tra 0.0 e 1.0, arrotondato a un decimale, che riflette la probabilità che l'input o la risposta appartengano a una determinata categoria.
Quattro di questi attributi relativi alla sicurezza (molestie, incitamento all'odio, contenuti pericolosi e sessualmente espliciti), vengono assegnate una valutazione di sicurezza (livello di gravità) e un un punteggio di gravità compreso tra 0,0 e 1,0, arrotondato a una cifra decimale. Queste classificazioni e questi punteggi riflettono la gravità prevista dei contenuti appartenenti a una determinata categoria.
Esempio di risposta
{
"predictions": [
{
"safetyAttributes": {
"categories": [
"Derogatory",
"Toxic",
"Violent",
"Sexual",
"Insult",
"Profanity",
"Death, Harm & Tragedy",
"Firearms & Weapons",
"Public Safety",
"Health",
"Religion & Belief",
"Illicit Drugs",
"War & Conflict",
"Politics",
"Finance",
"Legal"
],
"scores": [
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1
],
"safetyRatings": [
{"category": "Hate Speech", "severity": "NEGLIGIBLE", "severityScore": 0.0,"probabilityScore": 0.1},
{"category": "Dangerous Content", "severity": "LOW", "severityScore": 0.3, "probabilityScore": 0.1},
{"category": "Harassment", "severity": "MEDIUM", "severityScore": 0.6, "probabilityScore": 0.1},
{"category": "Sexually Explicit", "severity": "HIGH", "severityScore": 0.9, "probabilityScore": 0.1}
],
"blocked": false
},
"content": "<>"
}
]
}
Nota: le categorie con un punteggio arrotondato a 0,0 vengono omesse nella risposta. Questa risposta di esempio è solo a scopo illustrativo.
Esempio di risposta in caso di blocco
{
"predictions": [
{
"safetyAttributes": {
"blocked": true,
"errors": [
150,
152,
250
]
},
"content": ""
}
]
}
Descrizioni degli attributi di sicurezza
| Attributo sicurezza | Descrizione |
|---|---|
| Contenuti dispregiativi | Commenti negativi o dannosi che hanno come target l'identità e/o attributi protetti. |
| Contenuti tossici | Contenuti scortesi, irrispettosi o volgari. |
| Contenuti di natura sessuale | Riferimenti ad atti sessuali o ad altri contenuti osceni. |
| Contenuti violenti | Descrive scenari che raffigurano violenza contro un individuo o un gruppo oppure descrizioni generali di scene di violenza. |
| Insulti | Commento offensivo, provocatorio o negativo nei confronti di una persona o di un gruppo di persone. |
| Linguaggio volgare | Linguaggio osceno o volgare, come parolacce. |
| Morte, danni e tragedie | Morti umane, tragedie, incidenti, disastri e autolesionismo. |
| Armi e armi da fuoco | Contenuti che fanno riferimento a coltelli, pistole, armi personali e accessori, quali come munizioni, fondine ecc. |
| Sicurezza pubblica | Servizi e organizzazioni che forniscono soccorso e garantiscono la sicurezza pubblica. |
| Salute | Salute umana, tra cui: patologie, malattie e disturbi; terapie mediche, farmaci, vaccinazioni e pratiche mediche; e le risorse per la guarigione, inclusi i gruppi di supporto. |
| Credo e religione | Credo che si occupano della possibilità di leggi soprannaturali ed esseri; religione, fede, credo, pratica spirituale, chiese e luoghi di culto. Include l'astrologia e l'occultismo. |
| Sostanze stupefacenti illegali | Sostanze stupefacenti per uso ricreativo e illegali; accessori e coltivazione di sostanze stupefacenti, headshop e altro ancora. Include l'uso di medicinali di solito utilizzati a scopo ricreativo (ad es. marijuana). |
| Guerre e conflitti | Guerre, conflitti militari e grandi conflitti fisici che coinvolgono il numero di persone. Include la discussione sui servizi militari, anche se non direttamente correlati a una guerra o un conflitto. |
| Finanza | Servizi finanziari per consumatori e aziende, come servizi bancari, prestiti, credito, investimenti, assicurazioni e altro ancora. |
| Politica | Notizie e media politici; discussioni su enti sociali, governativi delle norme pubbliche. |
| Legale | Contenuti correlati alla legge, per includere: studi legali, informazioni legali, principali materiali legali, servizi paralegali, pubblicazioni legali e tecnologia, testimoni periti, consulenti per controversie e altri fornitori di servizi legali. |
Attributi di sicurezza con valutazioni di sicurezza
| Attributo di sicurezza | Definizione | Livelli |
|---|---|---|
| Incitamento all'odio | Commenti negativi o dannosi rivolti all'identità e/o agli attributi protetti. | Alta, Media, Bassa, Negligible |
| Molestie | Commenti dannosi, intimidatori, prepotenti o illeciti rivolti a un altro individuo. | Alto, Medio, Basso, Trascurabile |
| Sessualmente esplicito | Riferimenti ad atti sessuali o ad altri contenuti osceni. | Alto, Medio, Basso, Trascurabile |
| Contenuti pericolosi | Promuove o consente l'accesso a beni, servizi e attività dannosi. | Alta, Media, Bassa, Negligible |
Soglie di sicurezza
Le soglie di sicurezza vengono applicate per i seguenti attributi di sicurezza:
- Incitamento all'odio
- Molestie
- Sessualmente esplicito
- Contenuti pericolosi
Google blocca le risposte del modello che superano i punteggi di gravità designati per questi attributi di sicurezza. Per richiedere la possibilità di modificare una soglia di sicurezza, contatta il team dedicato al tuo account Google Cloud.
Testare le soglie di confidenza e gravità
Puoi testare i filtri di sicurezza di Google e definire soglie di affidabilità adatte per la tua attività. Utilizzando queste soglie, puoi acquisire per rilevare contenuti che violano le norme di utilizzo o i termini di Google e a prendere le misure appropriate.
I punteggi di confidenza sono solo previsioni e non devono dipendere i punteggi di affidabilità o accuratezza. Google non è responsabile dell'interpretazione o usare questi punteggi per prendere decisioni aziendali.
Importante: probabilità e gravità
Ad eccezione dei quattro attributi di sicurezza con valutazioni di sicurezza, i punteggi di confidenza dei filtri di sicurezza dell'API PaLM si basano sulla probabilità che i contenuti non siano sicuri e non sulla gravità. Questo è importante da considerare perché alcuni contenuti possono avere una bassa probabilità di essere non sicuri, anche se la gravità del danno potrebbe essere comunque alta. Ad esempio, se confrontiamo frasi:
- Il robot mi ha dato un pugno.
- Il robot mi ha colpito.
La frase 1 potrebbe avere una maggiore probabilità di non essere sicura, ma potresti considerare la frase 2 di maggiore gravità in termini di violenza.
Pertanto, è importante che i clienti testino attentamente e valutino il livello di blocco appropriato per supportare i loro casi d'uso principali, minimizzando al contempo i danni agli utenti finali.
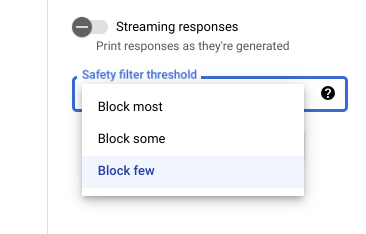
Impostazioni di sicurezza in Vertex AI Studio
Con la soglia del filtro di sicurezza regolabile, puoi regolare la probabilità
per visualizzare risposte potenzialmente dannose. Le risposte del modello vengono bloccate in base
probabilità che contenga molestie, incitamento all'odio, contenuti pericolosi o
contenuti sessualmente espliciti. L'impostazione del filtro di sicurezza si trova sul lato
destro del campo della richiesta in Vertex AI Studio. Puoi scegliere tra tre opzioni: block most, block some e block few.
Filtro citazioni
Le nostre funzionalità di codice generativo sono pensate per produrre contenuti originali e non replicare in dettaglio i contenuti esistenti. Abbiamo progettato i nostri sistemi in modo da limitare maggiori probabilità che ciò accada e migliorare continuamente il modo in cui questi sistemi personalizzata. Se queste funzionalità contengono direttamente e in dettaglio citazioni di una pagina web, per citare la pagina.
A volte gli stessi contenuti vengono trovati su più pagine web e tentiamo per indirizzarti a una fonte molto conosciuta. Nel caso di citazioni di repository di codice, la citazione potrebbe anche fare riferimento a una licenza open source applicabile. Il rispetto di eventuali requisiti di licenza è una tua responsabilità.
Per ulteriori informazioni sui metadati del filtro per le citazioni, consulta la documentazione di riferimento dell'API Citation.
Errori di sicurezza
I codici di errore di sicurezza sono codici a tre cifre che rappresentano il motivo per cui un
un prompt o una risposta sono stati bloccati. La prima cifra è un prefisso
indica se il codice si applica al prompt o alla risposta e
le cifre rimanenti indicano il motivo per cui la richiesta o la risposta è stata bloccata.
Ad esempio, un codice di errore 251 indica che la risposta è stata bloccata
a causa di un problema con contenuti di incitamento all'odio nella risposta del modello.
In una singola risposta possono essere restituiti più codici di errore.
Se si verificano errori che bloccano i contenuti nella risposta dal modello
(prefisso = 2, ad esempio 250),
modifica l'impostazione temperature nella tua richiesta. Ciò consente di generare
un insieme diverso di risposte con meno possibilità di essere bloccati.
Prefisso del codice di errore
Il prefisso del codice di errore è la prima cifra del codice di errore.
| 1 | Il codice di errore si applica al prompt inviato al modello. |
| 2 | Il codice di errore si applica alla risposta del modello. |
Motivo del codice di errore
Il motivo del codice di errore è costituito dalla seconda e dalla terza cifra del codice di errore.
I motivi dei codici di errore che iniziano con 3 o 4 indicano prompt o risposte
è bloccata perché la soglia di confidenza per una violazione dell'attributo di sicurezza era
sono soddisfatte determinate condizioni.
I motivi dei codici di errore che iniziano con 5 indicano prompt o risposte in cui
sono stati trovati contenuti non sicuri.
| 10 | La risposta è stata bloccata a causa di un problema di qualità o di un'impostazione del parametro che influisce sui metadati della citazione. Vale solo per
risposte da parte del modello. ovvero La funzionalità di controllo delle citazioni identifica problemi di qualità o derivanti da un
dell'impostazione del parametro. Prova ad aumentare Per ulteriori informazioni, consulta la sezione Filtro citazioni. |
| 20 | La lingua fornita o restituita non è supportata. Per un elenco delle lingue, vedi Lingue supportate. |
| 30 | Il prompt o la risposta è stata bloccata perché è stata ritenuta potenzialmente dannosa. Un termine è incluso dalla lista bloccata terminologica. Riformula il richiesta. |
| 31 | I contenuti potrebbero includere informazioni sensibili che consentono l'identificazione personale (informazioni personali sensibili). Riformula il prompt. |
| 40 | Il prompt o la risposta è stata bloccata perché è stata ritenuta potenzialmente dannosa. I contenuti violano le impostazioni di SafeSearch. Riformula il prompt. |
| 50 | Il prompt o la risposta sono stati bloccati perché potrebbero includere contenuti sessualmente espliciti. Riformula il prompt. |
| 51 | Il prompt o la risposta è stato bloccato perché potrebbe contenere contenuti di incitamento all'odio. Riformula il prompt. |
| 52 | Il prompt o la risposta sono stati bloccati perché potrebbero includere contenuti molesti. Riformula il prompt. |
| 53 | Il prompt o la risposta sono stati bloccati perché potrebbero includere contenuti pericolosi. Riformula il prompt. |
| 54 | Il prompt o la risposta è stato bloccato perché potrebbe contenere contenuti dannosi. Riformula il prompt. |
| 00 | Motivo sconosciuto. Riformula il prompt. |
Passaggi successivi
- Scopri di più sull'IA responsabile.
- Scopri di più sulla governance dei dati.